
データベースのサイジングを適切に行い、データベーススキーマを適切に設計することは非常に困難です。そのため、運用中のデータベースのパフォーマンスを反復的に分析し、微調整することが重要です。
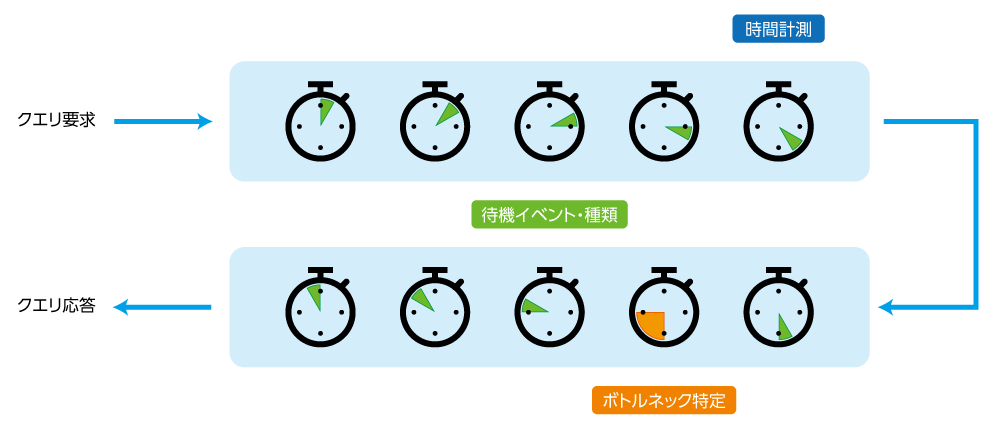
データベーススキーマの修正を始める前に、データベースが本当のボトルネックにぶつかっていることを検証する必要があります。データベースにはいくつものボトルネックがあるかもしれませんが、どのボトルネックが本当に重要なのでしょうか?どのボトルネックを修正する価値があるのでしょうか?どのボトルネックがユーザーエクスペリエンスに最も影響を及ぼしているのかでしょうか?
それを知るには、クライアントを最も待たせるSQLステートメントを特定できるツールから始めることでしょう。 Database Performance Analyzer (DPA)は、この分析に最適です。DPAを本番データベースに接続すると、実際の負荷を監視して分析することができます。
データベースのスループットを最適化してアプリケーションのパフォーマンスを向上させるという任務を負ったとき、それを実行します。まず、DPAをデータベースモニターとして使用し、待ち時間の多い上位100個のクエリ(SQL文)を分析・特定しました。
実践すべき、推奨するワークフローです。
1.データベースのボトルネックを特定するツールの活用
・DPAは、ほとんどのRDBMで使用できます。
2.待ち時間の合計が最も大きい上位N個のSQLステートメントを特定します。
・DPAで、データベースの「トレンド」ページに移動し、「SQLテキスト」タブ(チャートの下)を開いて、上位N個のSQLステートメントをリストアップします。
3.前のステップで特定したSQL文を最適化します。
・DPAは、特定のクエリまたは全体的なパフォーマンスを最適化する方法についてアドバイスを提供することがあります。
・SQL ハッシュをクリックして、クエリ詳細ページに移動します。このページには、パフォーマンスのヒントなど、1 つの SQL 文に関するすべての情報が 1 つのページにまとめられています。
・トレンド」ページの「待ち時間」タブに移動して、トップの待ち時間を確認できます。個々の待ち時間をクリックすると、全体的なパフォーマンスを向上させるためのアドバイスが得られます。
・「チューニング」タブに移動して、上位のクエリおよびテーブル・アドバイザーを表示します。
4.パフォーマンス要件を満たすまで繰り返す
ヒント: DPA では、デフォルトで上位 15 件のクエリがトレンド チャートに表示されます。NUMBER_OF_ITEMS_IN_TIMESERIES_CHARTSアドバンスオプションを変更すると、トレンドでより多くの(最大100)クエリが表示されます。
この演習を行うことで、次のような間違った仮定をすることを防げます。
・ユーザのデータベースは、タイムスタンプが論理キーの一部である行を保存しています。タイムスタンプでテーブルを分割すれば、全体として少なくとも10%の性能向上が期待できるはずだ。
・ユーザのデータベースは、エンティティIDが論理キーの一部である行を保存しています。データをエンティティIDでシャードに整理すると、全体として少なくとも10%のパフォーマンス向上が得られるはずです。
・ユーザのデータベースには大きなテーブルがあり、いくつかの大きなインデックスがありますが、カラムストアに切り替えるとこれを回避できます。
この場合、全体として少なくとも10%の性能向上が期待できます。
しかし、この例では、待ち時間の多い上位100個のクエリを特定しても、パーティショニング、シャーディング、列ストア技術から得られるメリットはほとんどありません。また、当初は最適化が必要だと考えていたトップクエリにはテーブルに関するものがありませんでした。
データベースへのパーティショニング、シャーディング、カラムストアの導入を検討する前に、まず待ち時間の合計が最も多いクエリを最適化することとです。これにより、全体的なパフォーマンスの向上がわずかであるにもかかわらず、データベーススキーマの再設計に多くの労力を費やすことを防いでいます。さらに、この手法でトップクエリを最適化した後は、すでに性能要件を満たしているため、これ以上データベースを最適化する必要がないことがよくあります。
関連したトピックス
- データベースのボトルネック:最も重要なボトルネックを特定する方法
- Database Performance Analyzer [DPA] でSQL Serverのパフォーマンスを見つけ、分析し、最適化へ
- MySQLスロー・クエリログ・アナライザ [DPA]
- SQL Server のデータベースパフォーマンス監視の重要性 [DPA]
- 待ち時間分析によるOracleからPostgreSQLへの移行のトラブルシューティング:Database Performance Analyzer(DPA)
- Database Performance Monitor :データベースの監視と効率化を行うSaaS型ソリューション
- 仮想化されたデータベース:パフォーマンス監視の考慮事項
- MySQLデータベースのパフォーマンスチューニングのヒント [DPA]
- Webセミナー録画とプレゼンテーション『 Oracle コンサルいらずのチューニングことはじめ』:2020/2/6 開催
- Amazon AWSクラウド上でのアプリケーションとデータベースのパフォーマンス問題

 RSSフィードを取得する
RSSフィードを取得する


