各種データベース間でのリアルタイム同期
コンテナでデータレプリケーションを簡単実現
リレーショナルデータベースRDBMS、NoSQL&ドキュメントストア、ビックデータ、データレイク、クラウドストレージ、イベントストリーミング、メッセージキュー等々
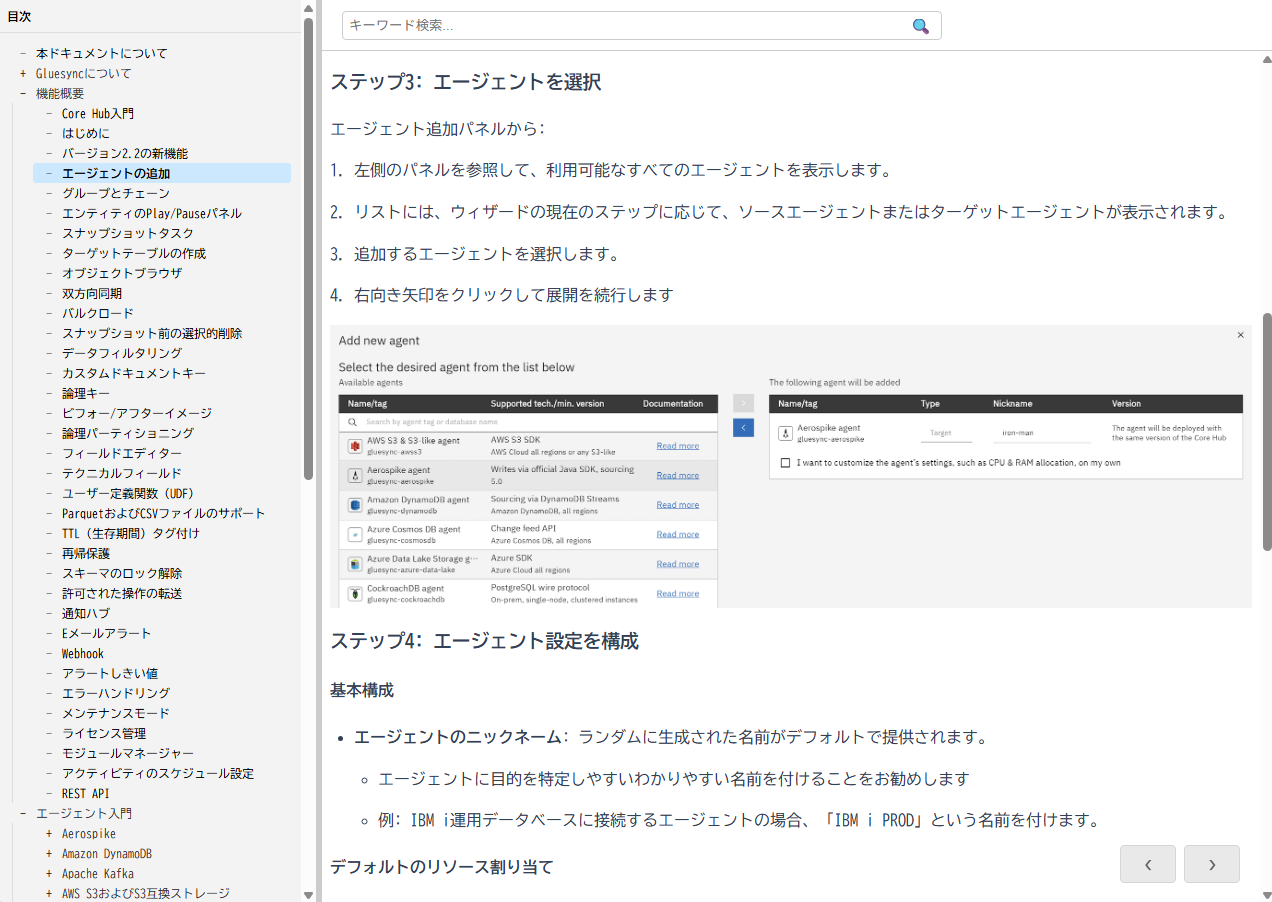
Gluesyncは、各種プラットフォーム間をリアルタイムに同期できます。異なるRDBMS間、NoSQL間、RDBMSとNoSQL間といった様々な構成に対応し、基幹DBのデータ活用やオフロード、バックアップ、分析のためのデータ統合、新しいデータ集約型アプリで使用するためのNoSQL連携など、さまざまな用途でご利用いただけます。
対応プラットフォーム
変更追跡に対応しているプラットフォームは同期のソースとしてサポートしています。
変更追跡に対応していないプラットフォームは同期のターゲットとしてのみサポートしています。
リレーショナルデータベース RDBMS
- ソース/ターゲット両対応
Db2 for IBM i

IBM Db2 for LUW

Informix

Oracle Database

MS SQL Server
SAP(Sybase)ASE

PostgreSQL

MySQL

MariaDB

YugabyteDB

SAP HANA

- ターゲットのみ対応
Google BigQuery

Snowflake

SingleStore

CockroachDB

Vertica

Amazon RedShift

NoSQL/ドキュメントストア
- ソース/ターゲット両対応
Amazon DynamoDB

Azure Cosmos DB

MongoDB

Aerospike

Couchbase

ScyllaDB

- ターゲットのみ対応
RavenDB

Redis

Cassandra

GridGain

ビッグデータ・データレイク・クラウドストレージ
- ソース/ターゲット両対応
- ターゲットのみ対応
Amazon S3、S3互換

Google Cloud Storage

Azure Data Lake Storage Gen2

イベントストリーミング・メッセージキュー
- ターゲットのみ対応
Google Pub/Sub

Apache Kafka

Solace PubSub+

アーキテクチャ
コンテナで動作
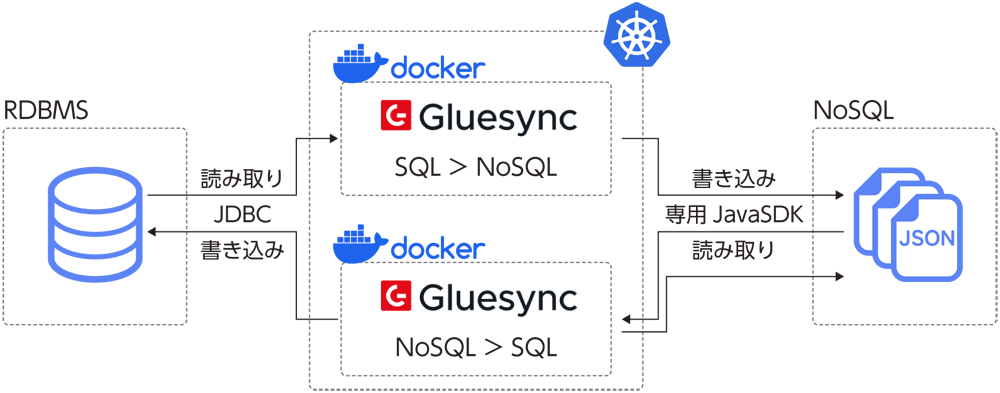
Gluesyncはコンテナで動作します。このため、KubernetesやOpenShiftなどのオーケストレータやDocker上で簡単に実行できます。また、オンプレだけでなく、Amazon EKSやGoogle Kubernetes Engine、Azure Kubernetes Serviceなどのクラウドでも利用でき、ハイブリッドな構成が可能です。

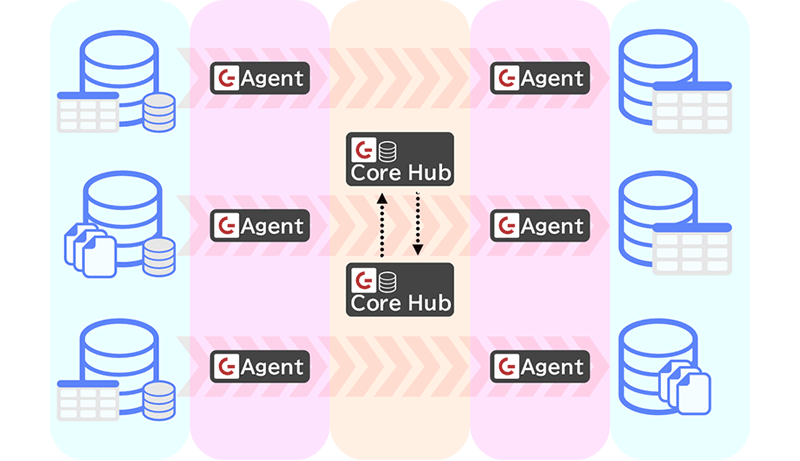
スケールアウト可能なコンポーネント構成
各プラットフォームとの接続はAgentが担当し、独立したコンテナとして1対1の関係で接続や変更追跡CDCを提供します。ソースプラットフォームからAgentが取得したデータはCore Hubへ送信され、そこでデータ処理や変換を実施、ターゲットのAgentへ送信され、ターゲットプラットフォームへ書き込まれます。
Core Hubはデータ処理以外にも、同期の設定や一貫性を保持するための情報を記録している重要なコンポーネントであるため、複数コンテナでの冗長構成や負荷分散も可能です。
- Core Hub:
- ・高可用性、負荷分散
- ・データ処理、集約
- ・管理(Web UI/API)、監視
- Agent:
- ・プラットフォームとの接続
- ・最適化された変更追跡CDC
簡単なデプロイメント、設定
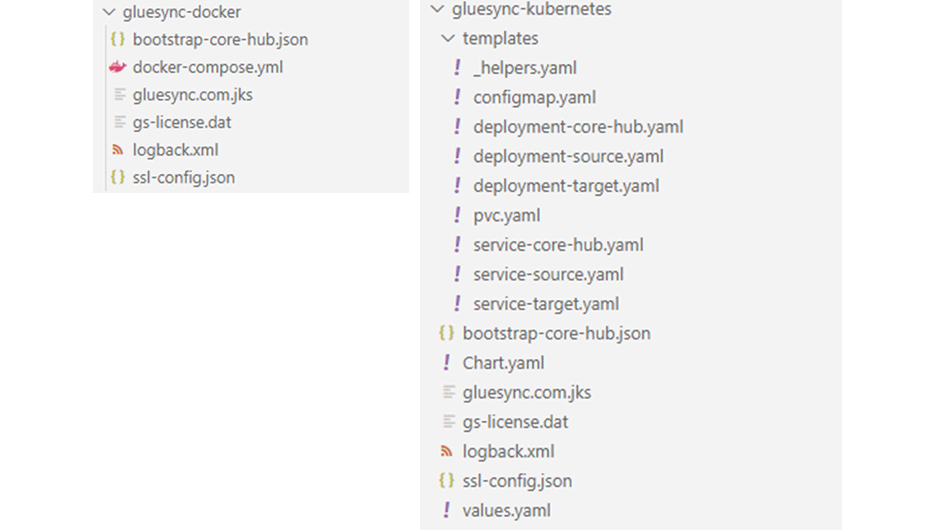
評価時に事前構成済みのDocker Compose、Helmチャートが提供されるため、これを基にDockerやKubernetes環境へインストール、実行ができます。
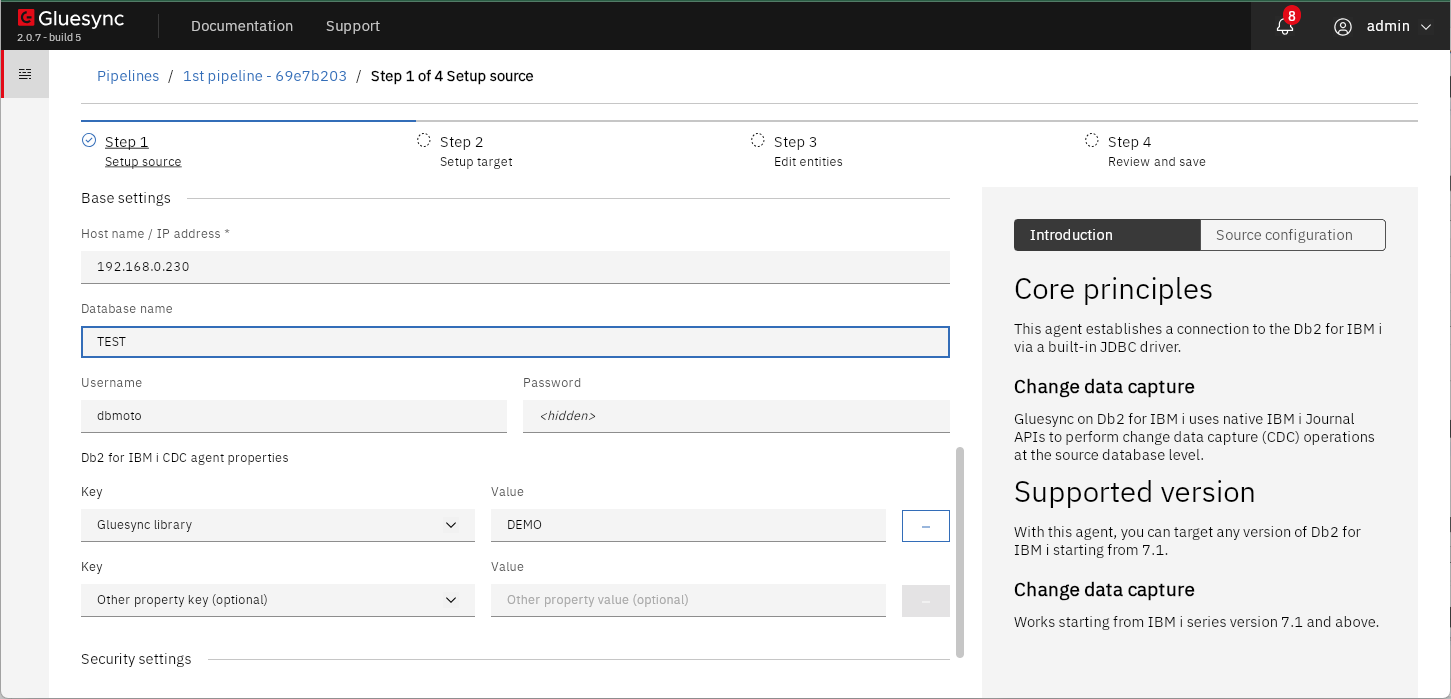
インストール後はWeb UIのウィザードに従って、必要項目を入力し同期設定を構成、実行できます。
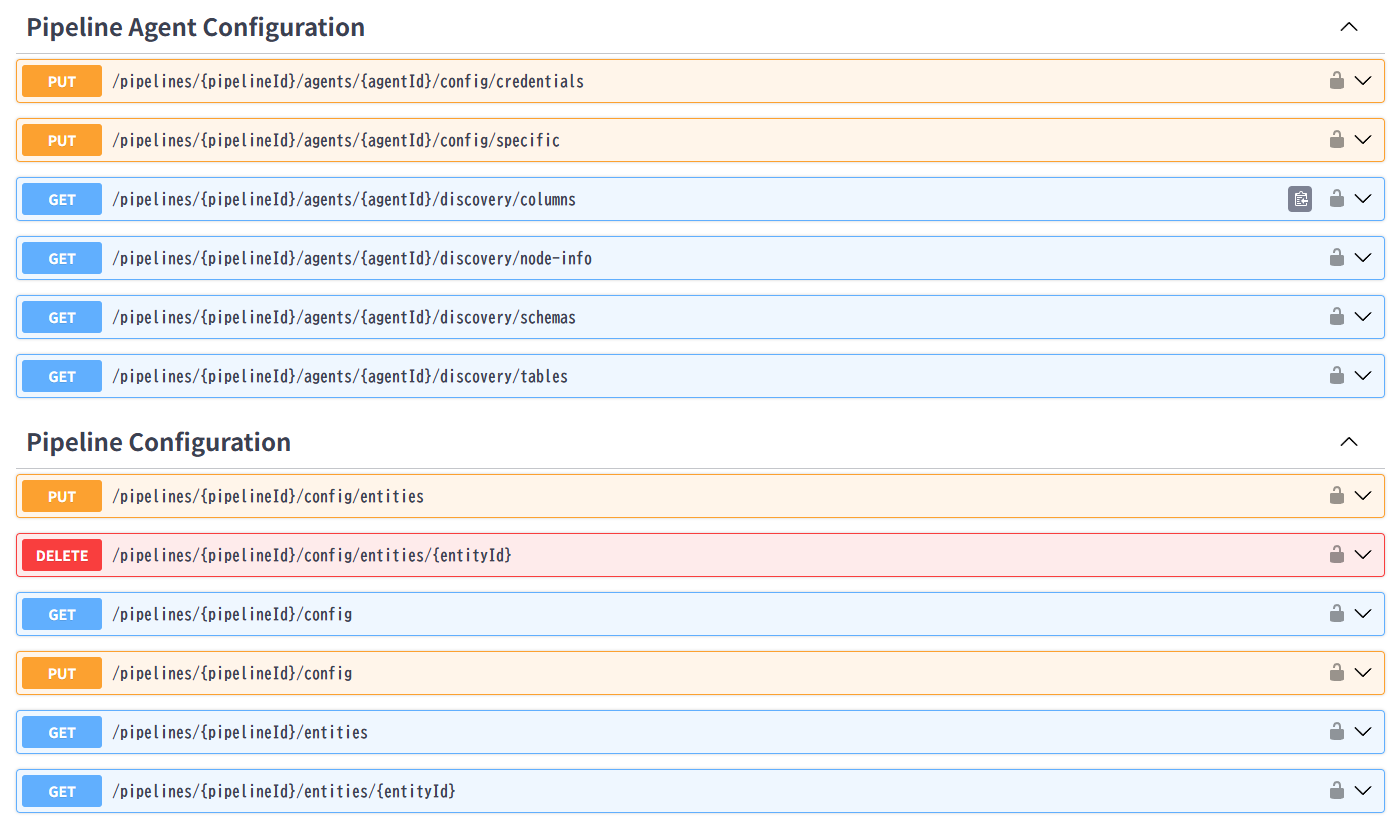
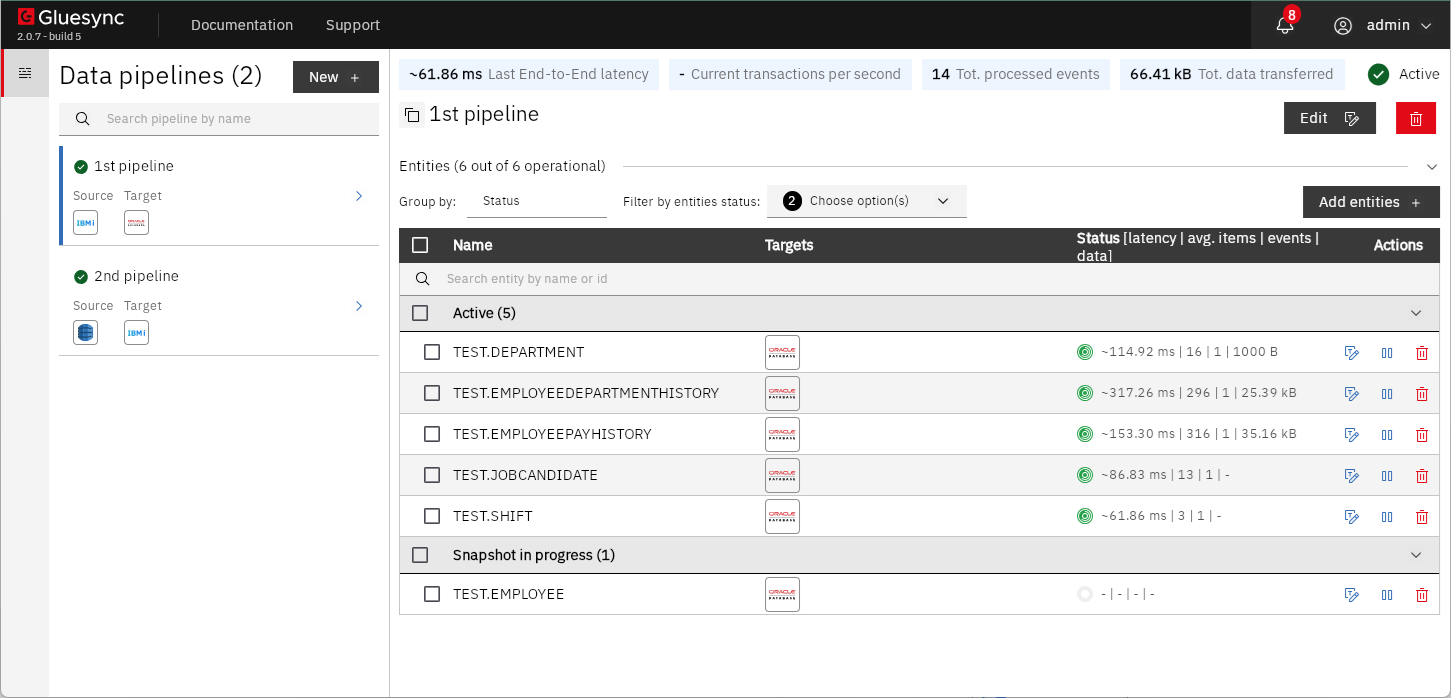
作成した同期設定はダッシュボードから状況を確認できます。
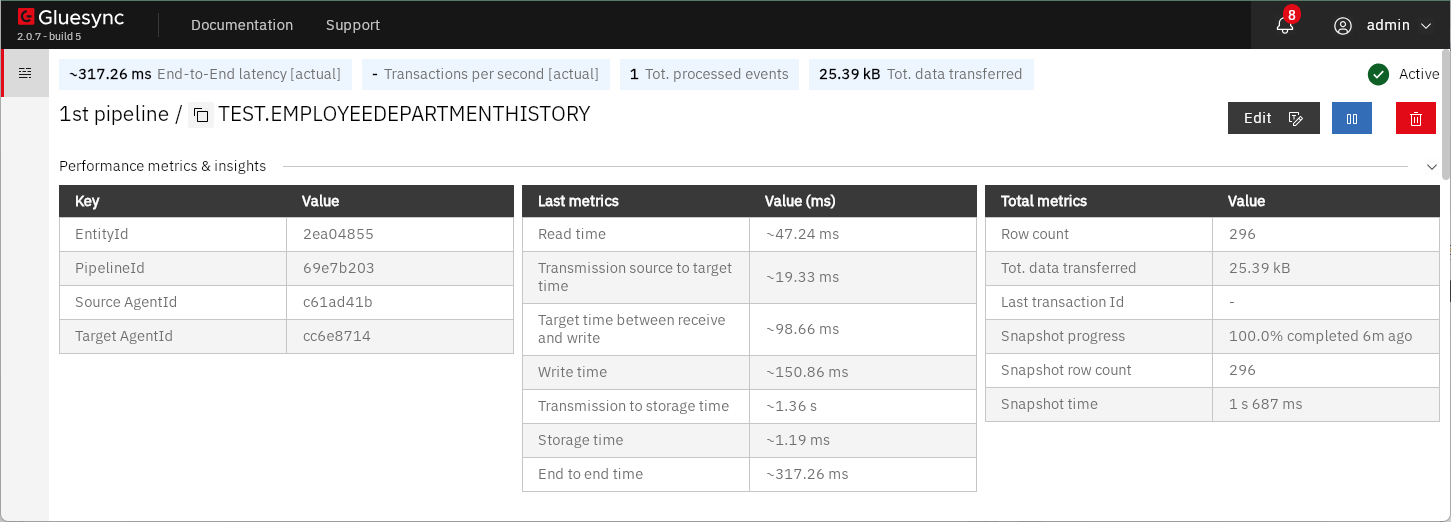
また同様の操作、設定が可能なRestAPIも用意されており、自動化や他のアプリケーションとの統合も可能です。