
既存のデータベース上にあるデータをクラウド上で分析する際に、コネクタなどで直接参照するといった方法もありますが、セキュリティなどの観点から直接の参照はむずかしい、データをマスクやフィルタリングする必要があるなど、手間がかかります。



このような際に、Gluesyncを使用して、データを基盤となるAWS S3やAzure Data Lake Gen 2、Google Cloud Storageに連携しておくことで簡単に分析が行えます。
そして、GluesyncはAWS S3、Azure Data Lake Gen 2、Google Cloud Storageでの連携において、JSON形式のみでなく、最新版2.1.6にてParquetファイルをサポートしました。
Parquetファイルとは何かといった点に関しては、下記のブログなどが参考になるかと思います。簡単に言えば、CSV等とは異なり、バイナリでデータを保持することでサイズを削減し、列指向データ形式により、Amazon AthenaやAzure Data FactoryなどのBigQuery、データ分析パフォーマンスを大幅に向上できます。
既存データベース上のテーブルをCSVでエクスポートすることは簡単でも、Parquetでエクスポートすることは難しい場合が多く、追加での変換などが必要になるケースが多いですが、Gluesyncであれば、そのような手間なく、Parquetファイルで以下のようなデータのカスタマイズ、リアルタイム同期まで実現できます。
- 必要なテーブル/カラムのみ連携
- レコードの値でフォルタリング
- UDF(ユーザ定義関数)で変換やマスキング
- 全件同期のスナップショット
- 差分同期のCDC
今回は実際にソースをPostgreSQL、ターゲットをAmazon S3として、この同期を構成してみました。
パイプラインの作成
コンテナでCoreHubやPostgreSQL/AWS S3との接続エージェントを起動しておき、Web UIからパイプライン(データプラットフォームとの接続)を作成していきます。
新規パイプラインの作成をクリック
ソースを追加をクリック

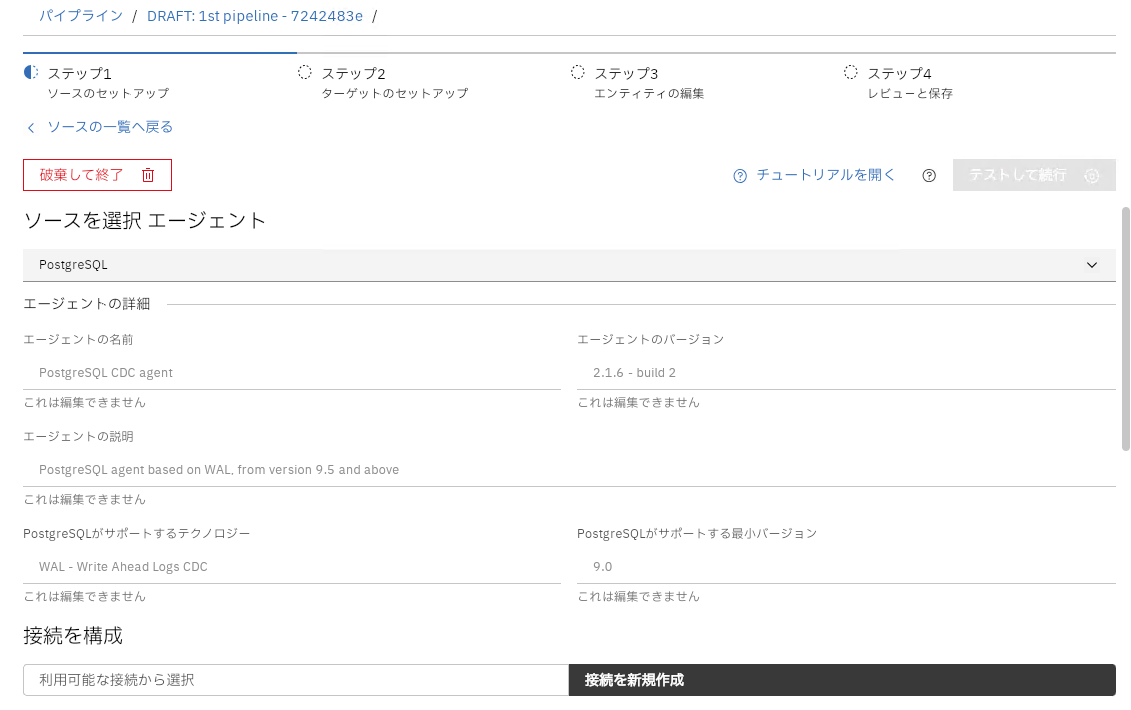
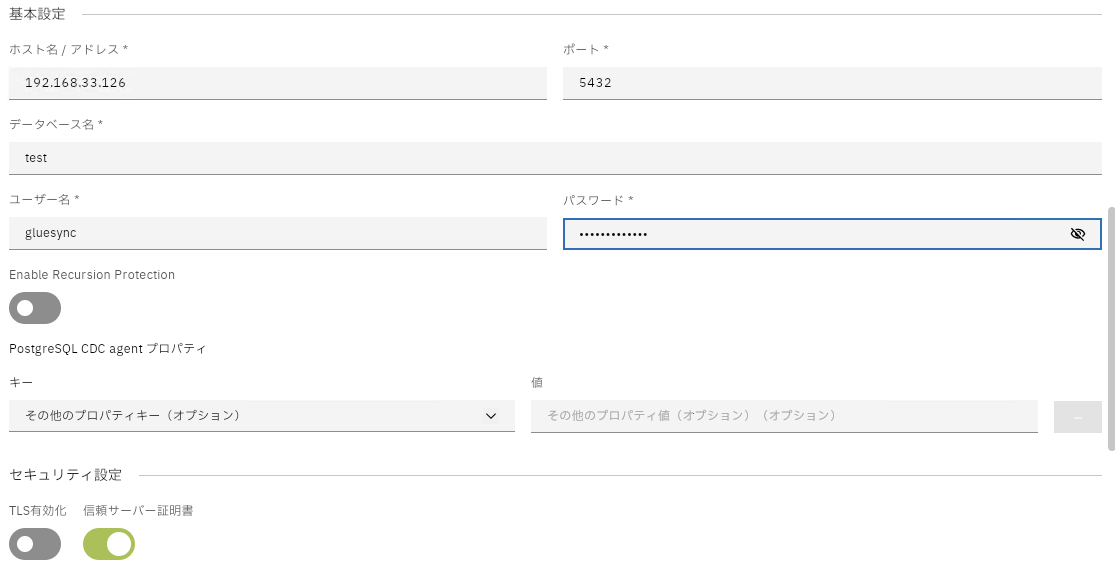
PostgreSQLを接続のエージェントとして選択して、接続情報を入力、テストして続行をクリックして次へ

ターゲットを追加をクリック
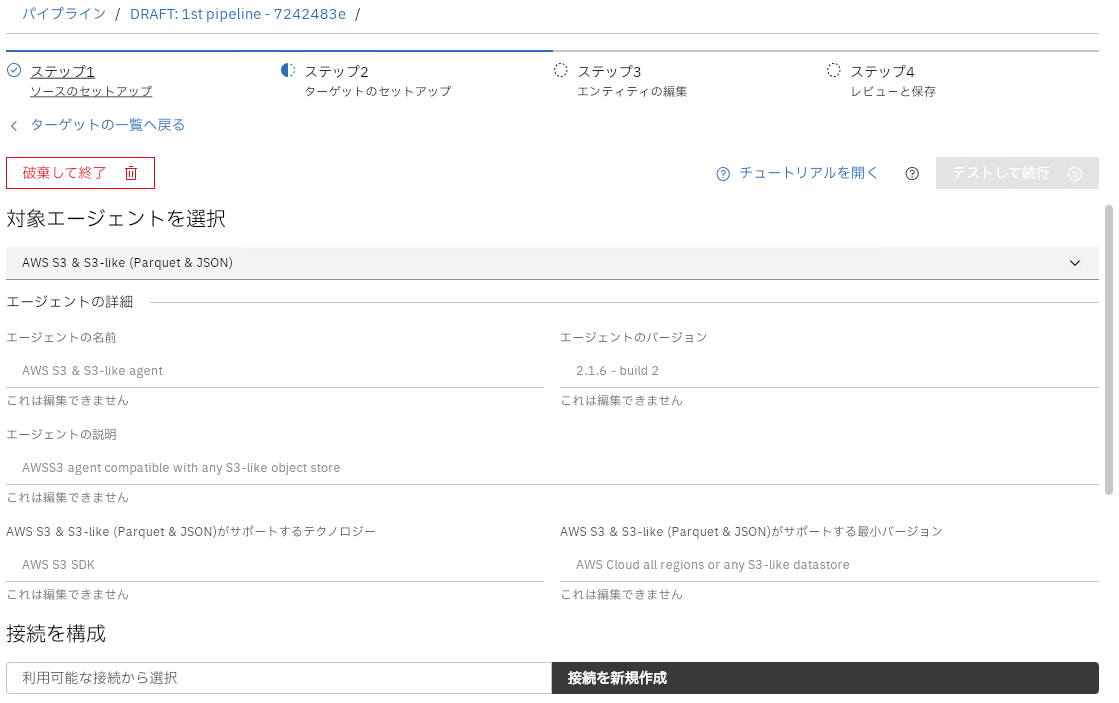
AWS S3 & S3-likeを接続のエージェントとして選択して接続情報(エンドポイントのURL、ポート、バケット名、アクセスキー、シークレットキー、リージョン)を入力、テストして続行をクリックして次へ

エンティティの設定
対象となるソーステーブルを選択
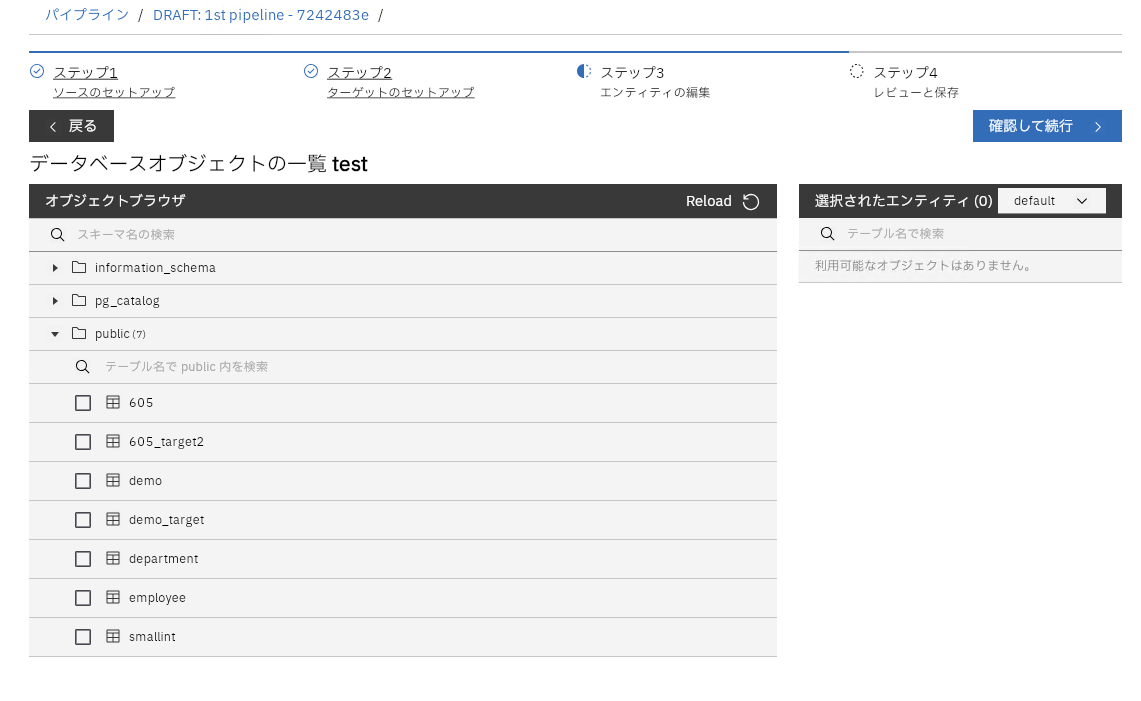
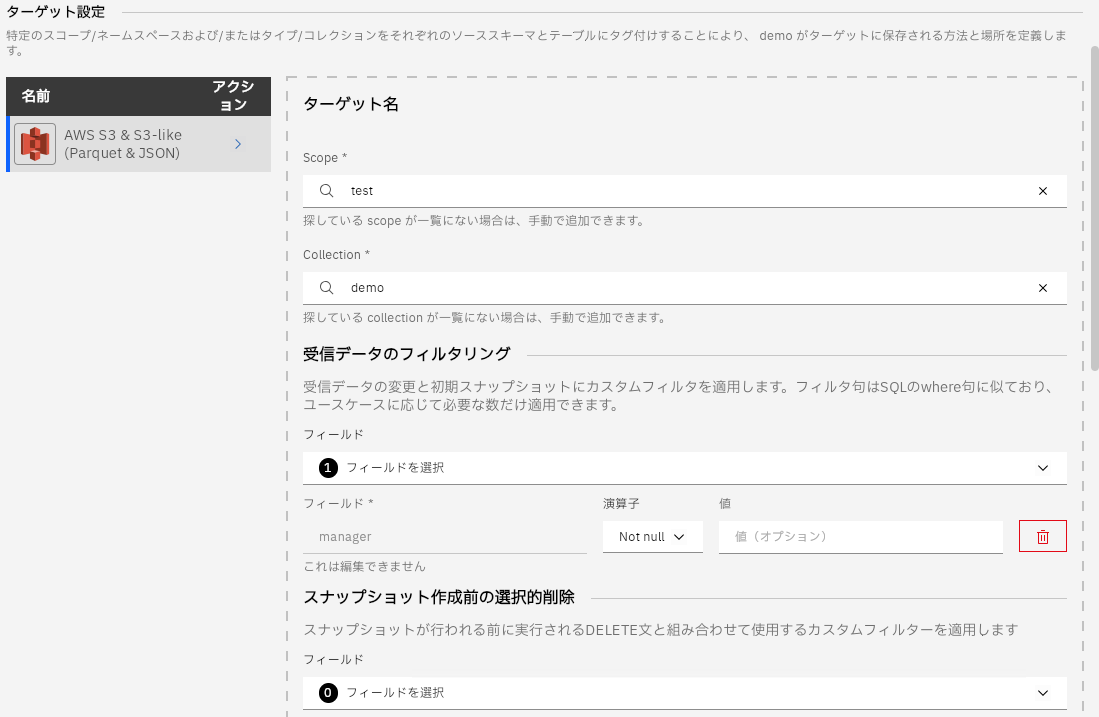
ターゲットの接続が表示されますが、S3の場合は適当なスコープとコレクションを指定します。ここで指定したスコープとコレクションはS3上のディレクトリ名に影響します。
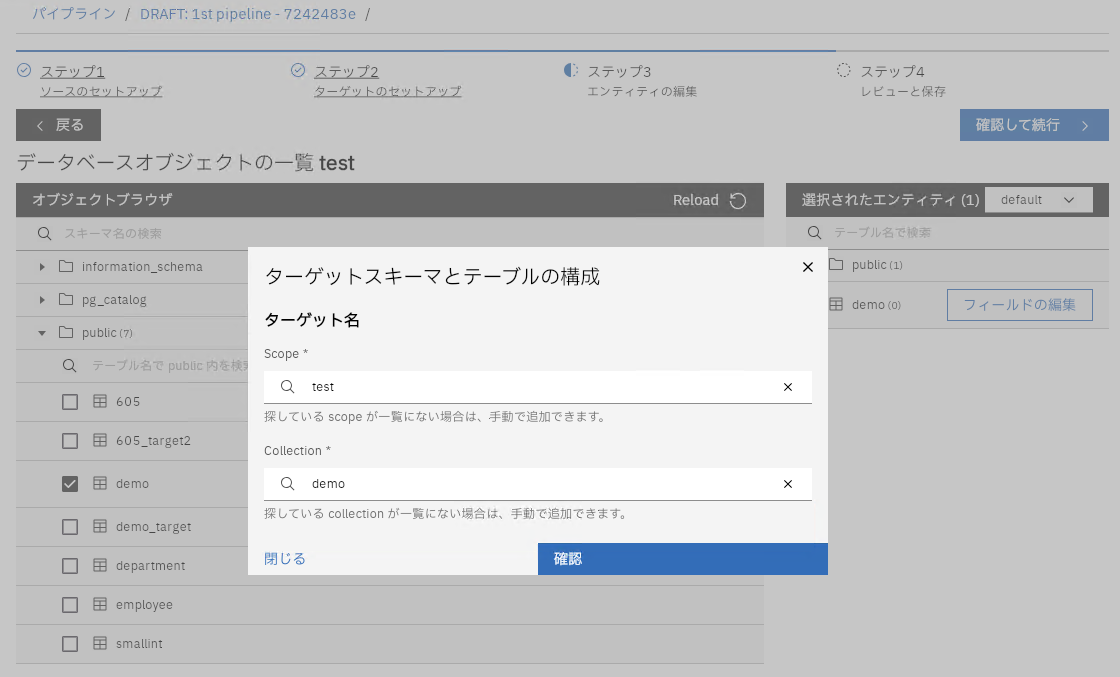
フィールドの編集からカラムのマッピングやUDFの指定が行えます。
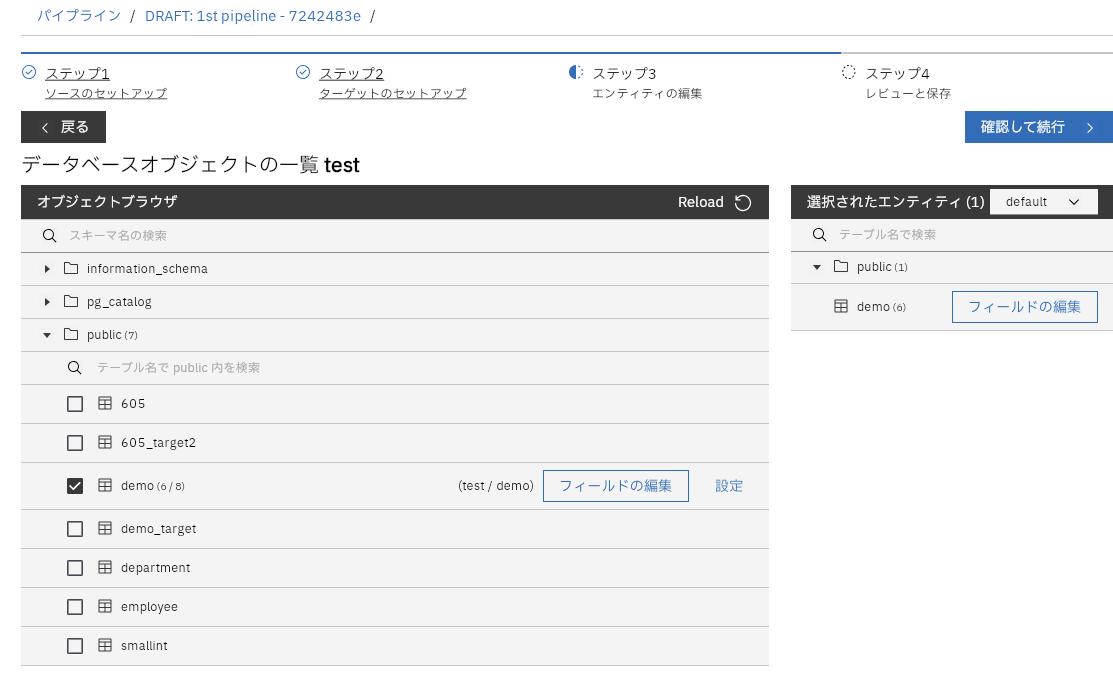
今回はsalaryとpercentage_salaryを対象外にします(デフォルトで同名でマッピングされています)。
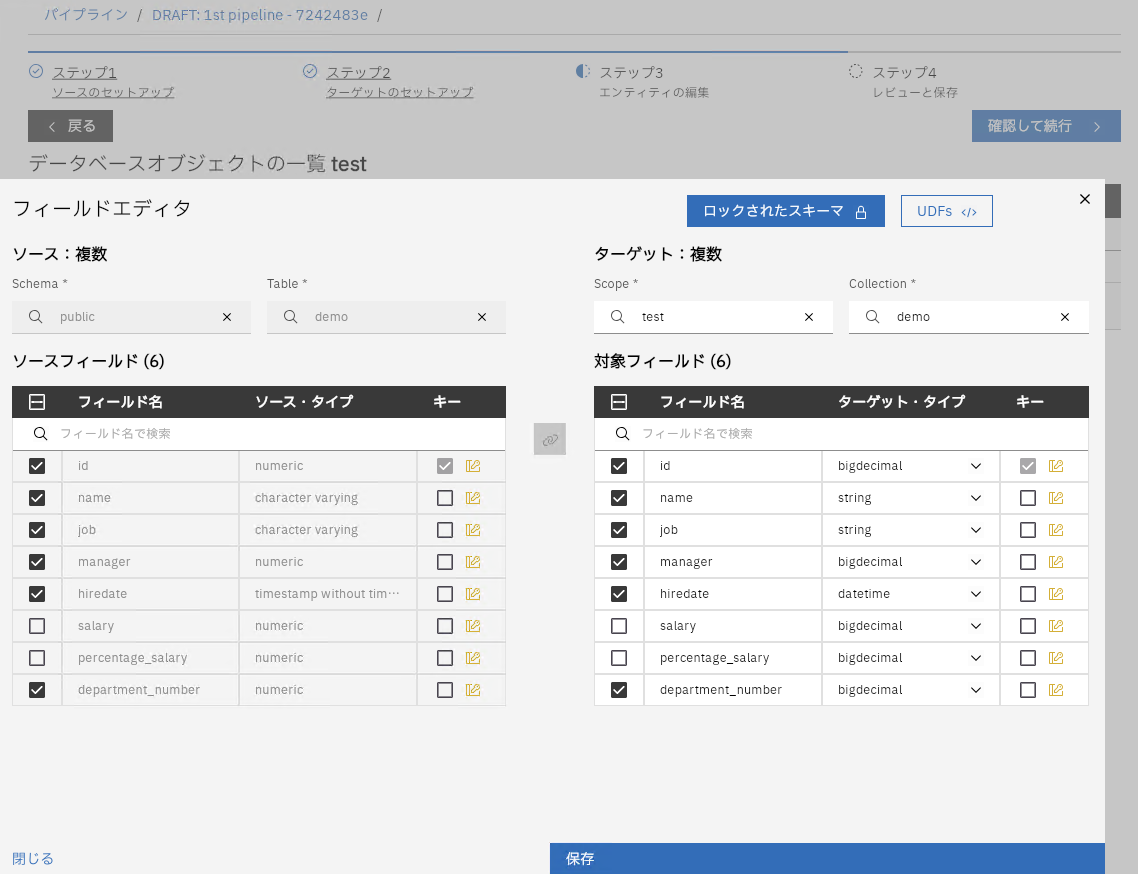
UDFも構成し、削除操作の際にnameカラムをマスクという値へ置き換えています。
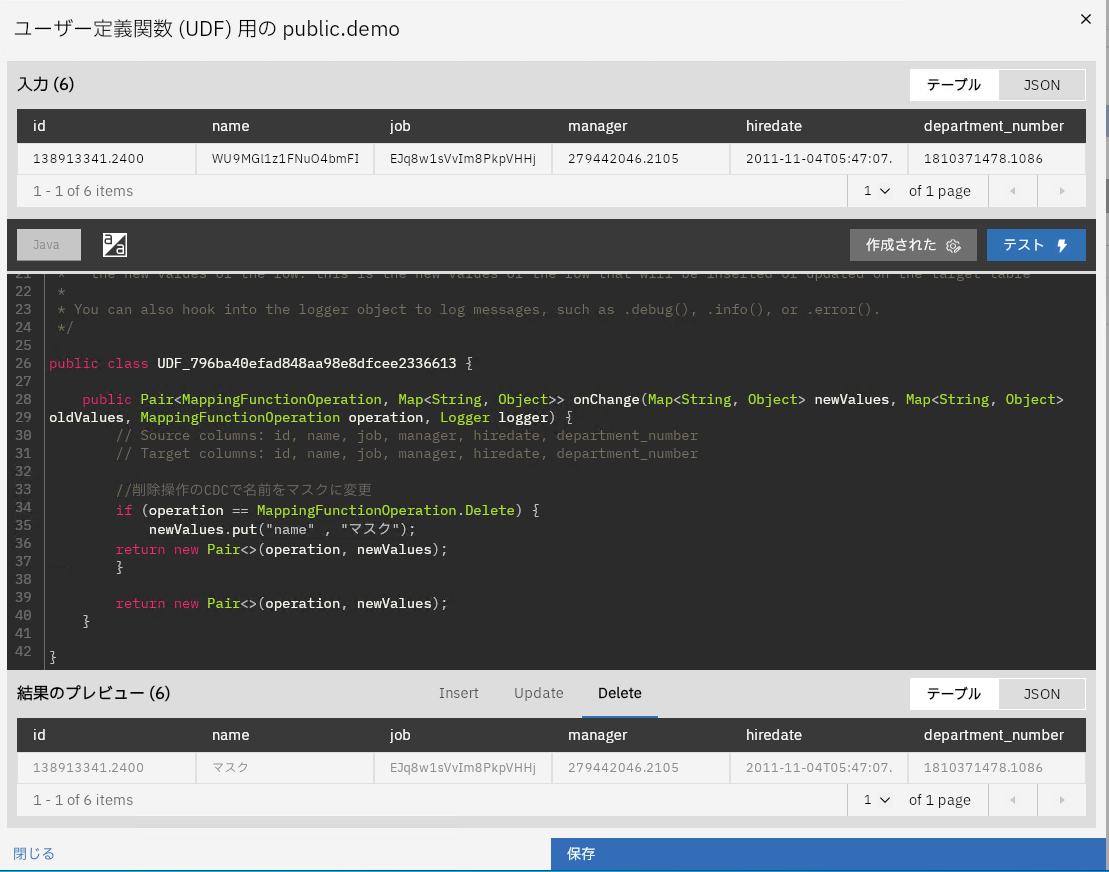
設定では各種追加の設定が行えます。
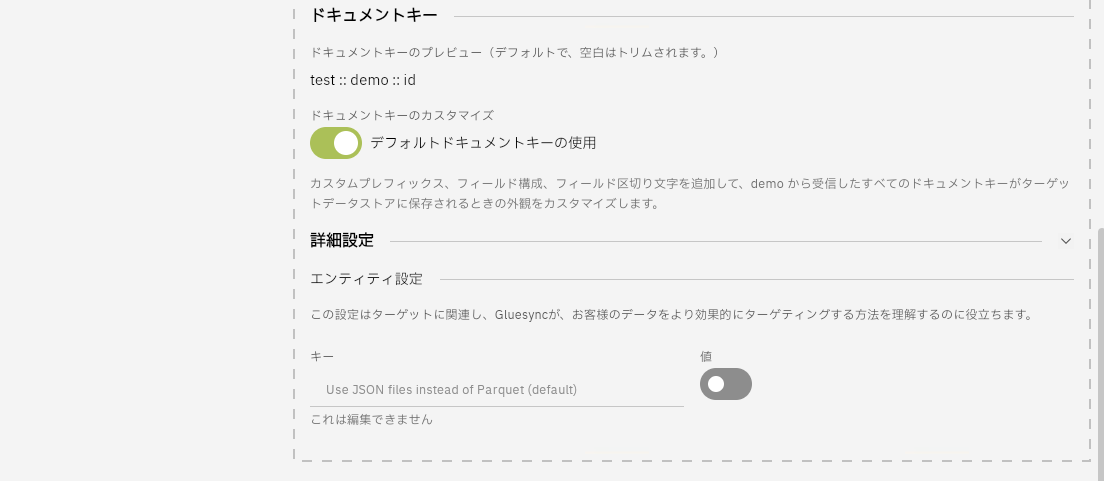
今回は受信データのフィルタリングでmanageカラムがNullでない場合のみ同期させるようにフィルタを設定しました。また、Use JSON files instead of Parquet(default)のトグルをオンにするとParquetファイル形式ではなくJSONファイル形式でS3へ同期するように変更できます。
最終的な設定を確認し、保存して完了をクリック
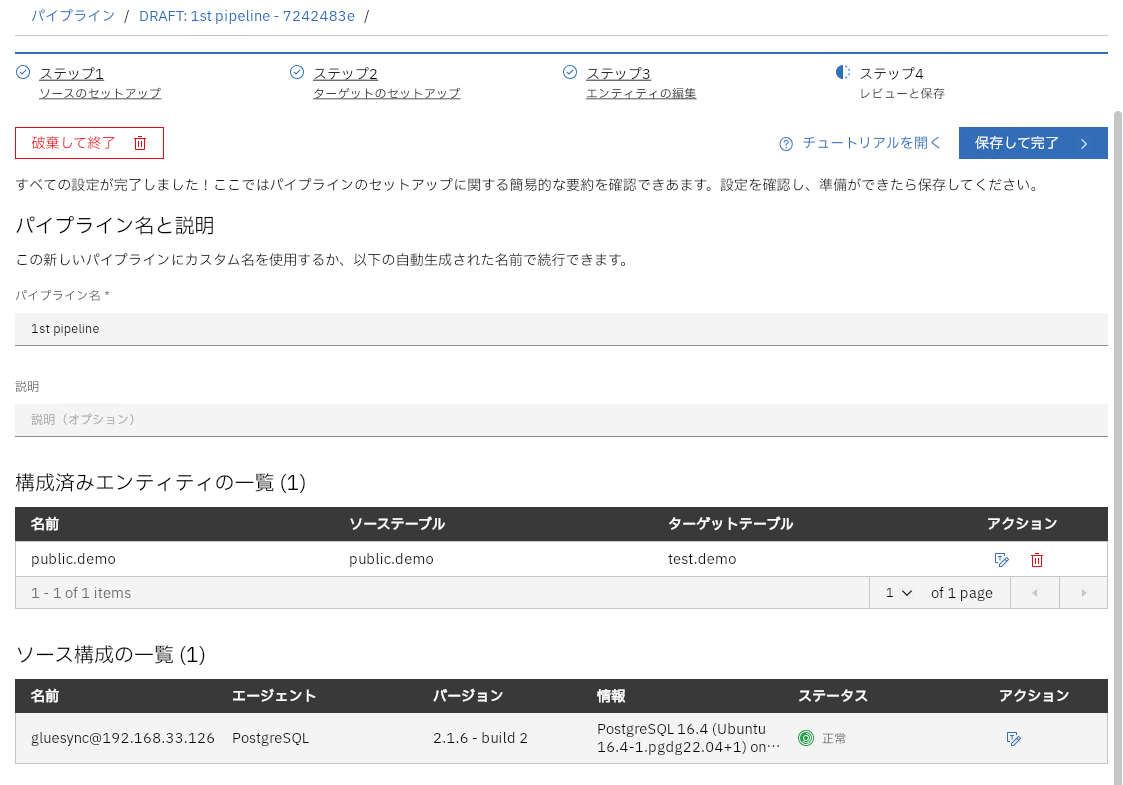

これで同期設定は完了です。
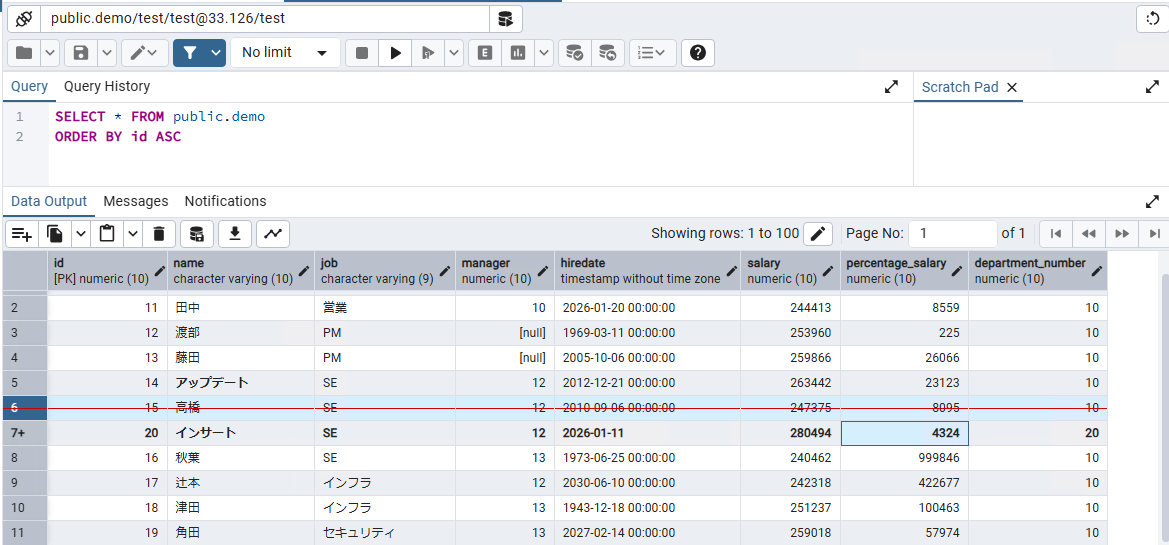
同期を開始する前に、テーブル構成として下記のように簡単なサンプルデータが入ってます。
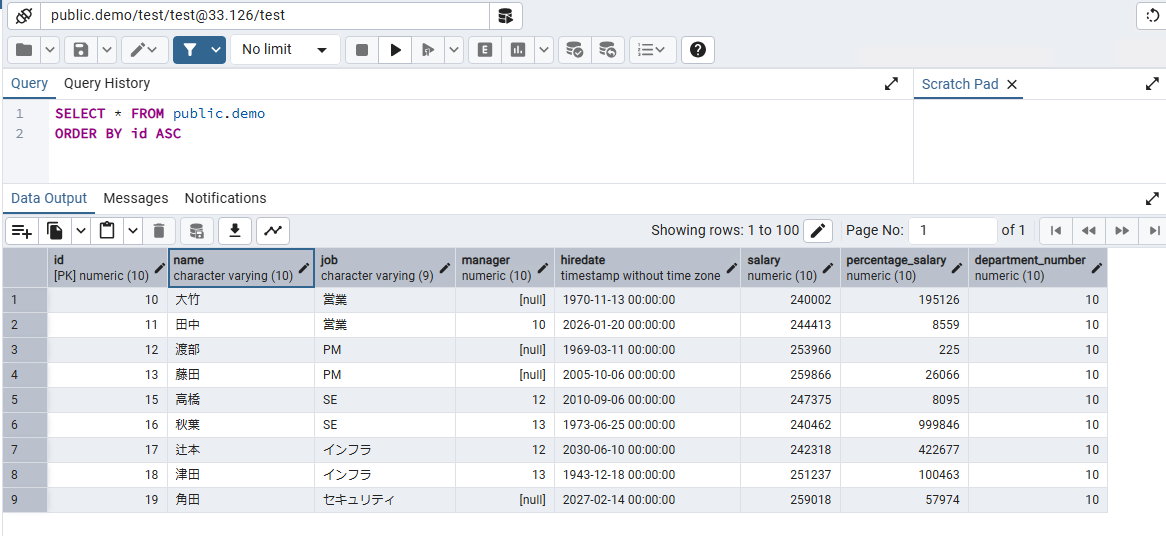
"id","name","job","manager","hiredate","salary","percentage_salary","department_number"
"10","大竹","営業",NULL,"1970-11-13 00:00:00","240002","195126","10"
"11","田中","営業","10","2026-01-20 00:00:00","244413","8559","10"
"12","渡部","PM",NULL,"1969-03-11 00:00:00","253960","225","10"
"13","藤田","PM",NULL,"2005-10-06 00:00:00","259866","26066","10"
"14","鈴木","SE","12","2012-12-21 00:00:00","263442","23123","10"
"15","高橋","SE","12","2010-09-06 00:00:00","247375","8095","10"
"16","秋葉","SE","13","1973-06-25 00:00:00","240462","999846","10"
"17","辻本","インフラ","12","2030-06-10 00:00:00","242318","422677","10"
"18","津田","インフラ","13","1943-12-18 00:00:00","251237","100463","10"
"19","角田","セキュリティ","13","2027-02-14 00:00:00","259018","57974","10"
ターゲットとなるバケットは空の状態です。
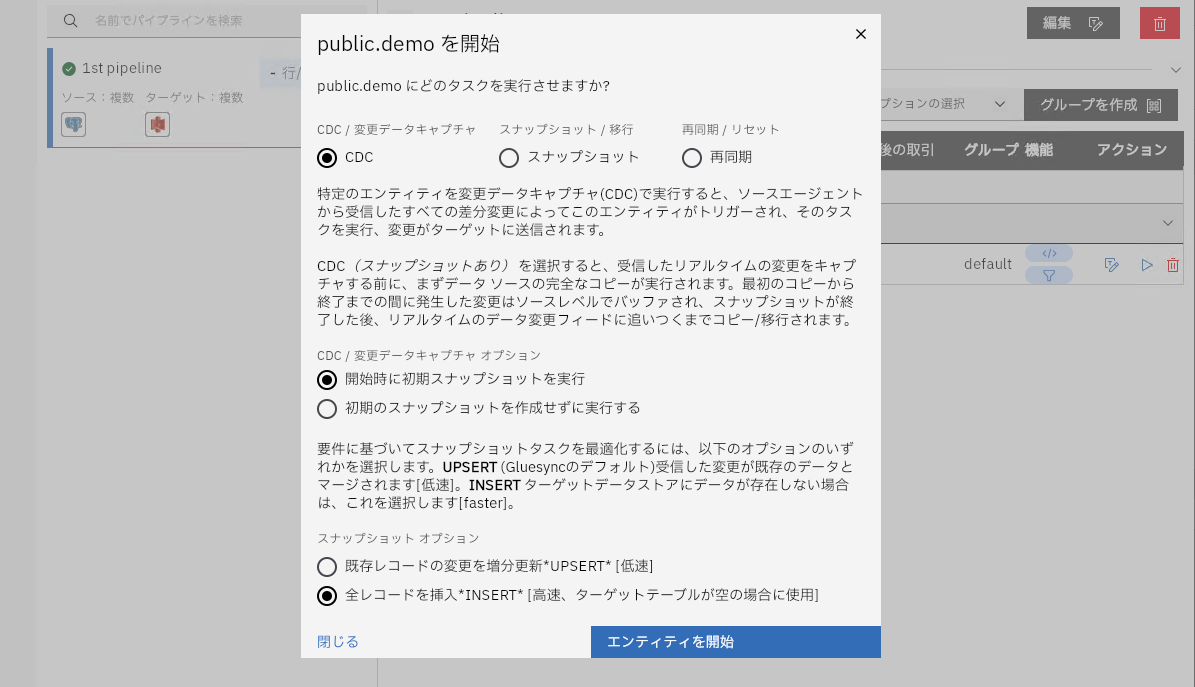
同期を開始します。今回はCDC(差分同期)+初期スナップショット(全件同期:Insert
モード)で実行するように指示しています。
同期し、初期スナップショットが完了すると下記のようにS3の階層化にJSONとParquetが配置されます。階層構造としては以下のようになっています。
- raw
- snapshot
- <スコープ名>_<コレクション名>
- year=<同期した年>
- month=<同期した月>
- <同期した日時>.json
- <同期した日時>.parquet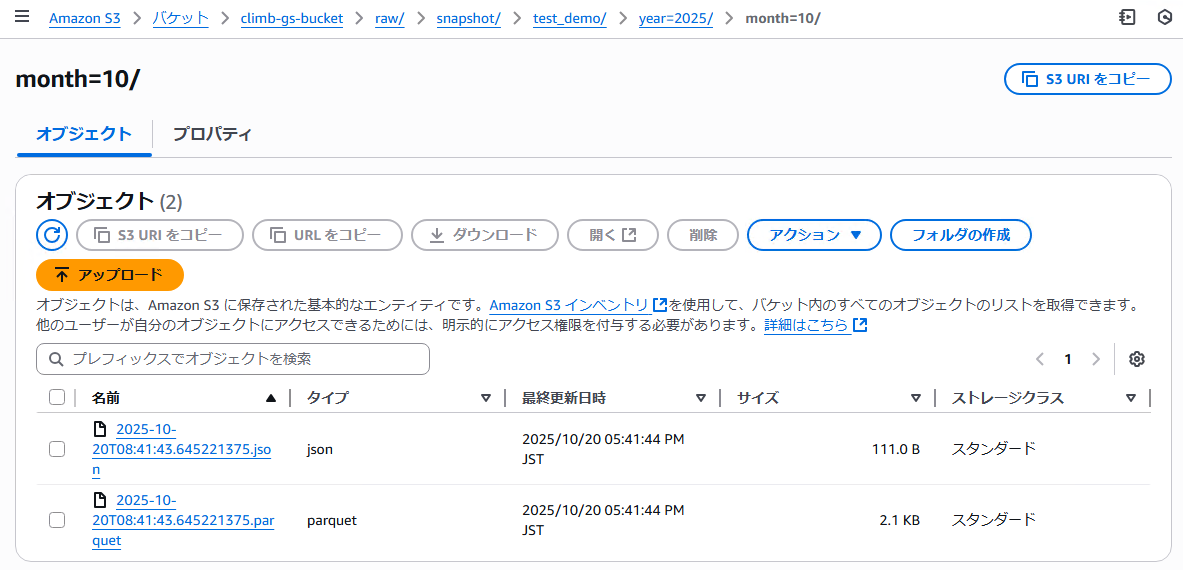
そしてJSONファイルには、実データではなく、どのような同期が行われたかを示すメタデータが保存されます。下記は、7レコードがInsertされたことを示しています。
{
"rowCount": 7,
"timestamp": "2025-10-20T08:41:43.645221375",
"operations": [
{
"type": "Insert"
},
1
],
"schemaVersion": 1
}そして実データとなるParquetファイルをS3 Selectで参照してみると、下記のようにデータがは入っています。
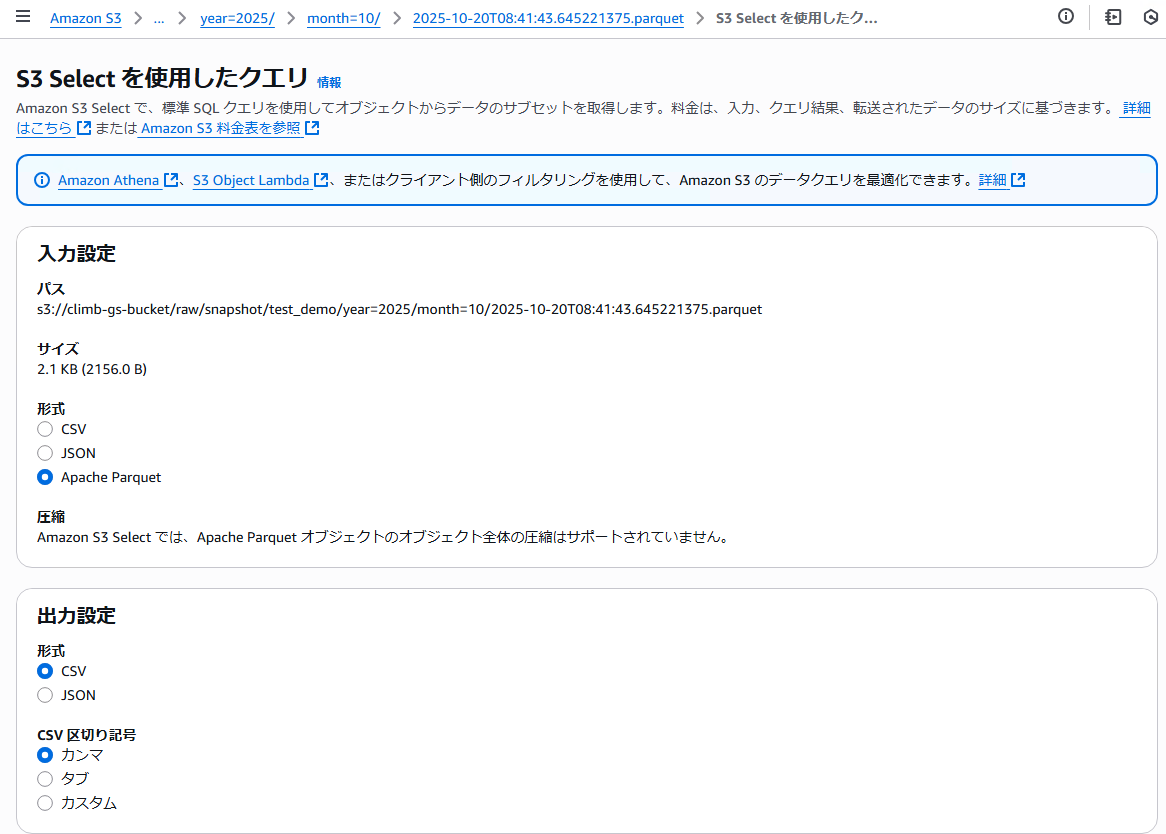
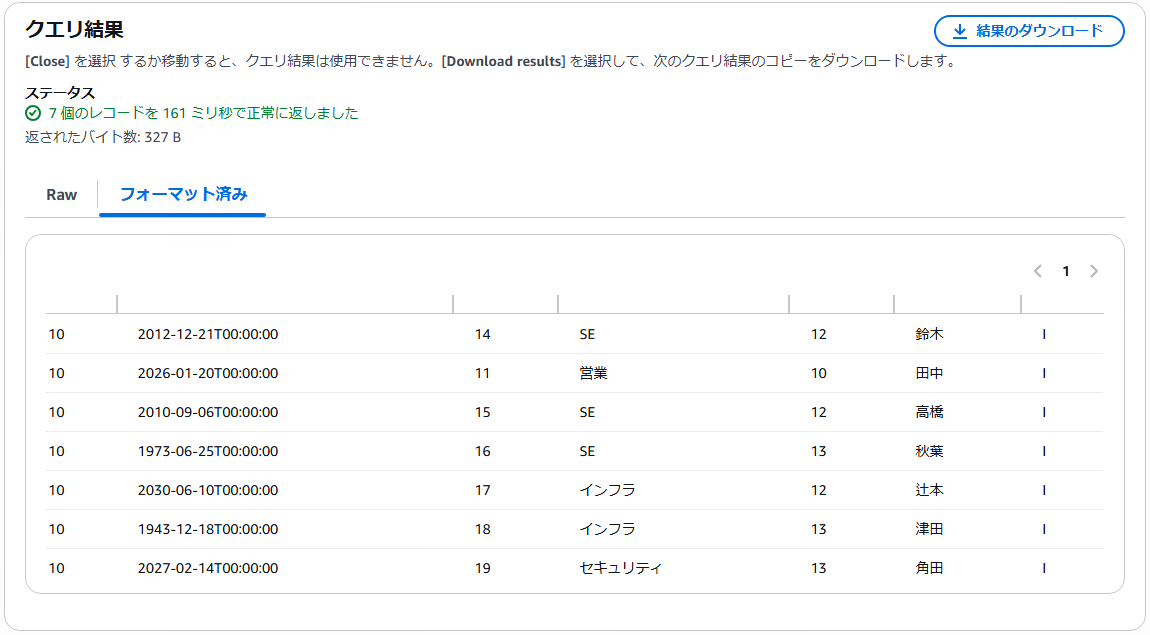
10,2012-12-21T00:00:00,14,SE,12,鈴木,I
10,2026-01-20T00:00:00,11,営業,10,田中,I
10,2010-09-06T00:00:00,15,SE,12,高橋,I
10,1973-06-25T00:00:00,16,SE,13,秋葉,I
10,2030-06-10T00:00:00,17,インフラ,12,辻本,I
10,1943-12-18T00:00:00,18,インフラ,13,津田,I
10,2027-02-14T00:00:00,19,セキュリティ,13,角田,I並び順が変わっているため少々分かりづらいですが、設定した通り、salaryとpercentage_salaryカラムは連携されず、managerがnullのレコードもフィルタリングされ、必要なデータのみが同期されていることを確認できます。
また、どのような操作で連携されたか示す符号(I:Insert、U:Update、D:Delete)が追加されます。上記はInsertモードでのスナップショット同期のため、IのInsertが追加されています。
次に、ソーステーブルに変更(Insert/Update/Delete)を行い変更をCDCで同期させてみます。
CDCで同期されたファイルは下記のように異なる階層に配置されます。
- raw
- changes
- <スコープ名>_<コレクション名>
- year=<同期した年>
- month=<同期した月>
- <同期した日時>.json
- <同期した日時>.parquet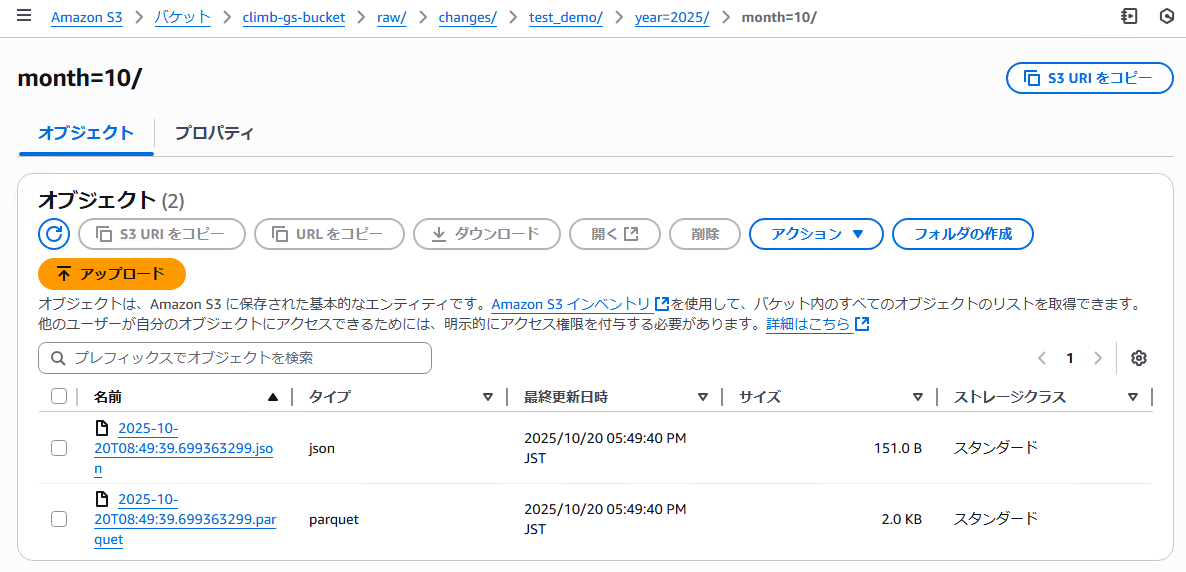
今回は各操作を実施しているため、同期されたレコード数は合計3件、各操作ごとに1件ずつであることを示すJSONも合わせて保存されています。
{
"rowCount": 3,
"timestamp": "2025-10-20T08:49:39.699363299",
"operations": [
{
"type": "Update"
},
1,
{
"type": "Delete"
},
1,
{
"type": "Insert"
},
1
],
"schemaVersion": 1
}ParquetファイルをS3 Selectで参照してみると、下記のようにデータがは入っています。
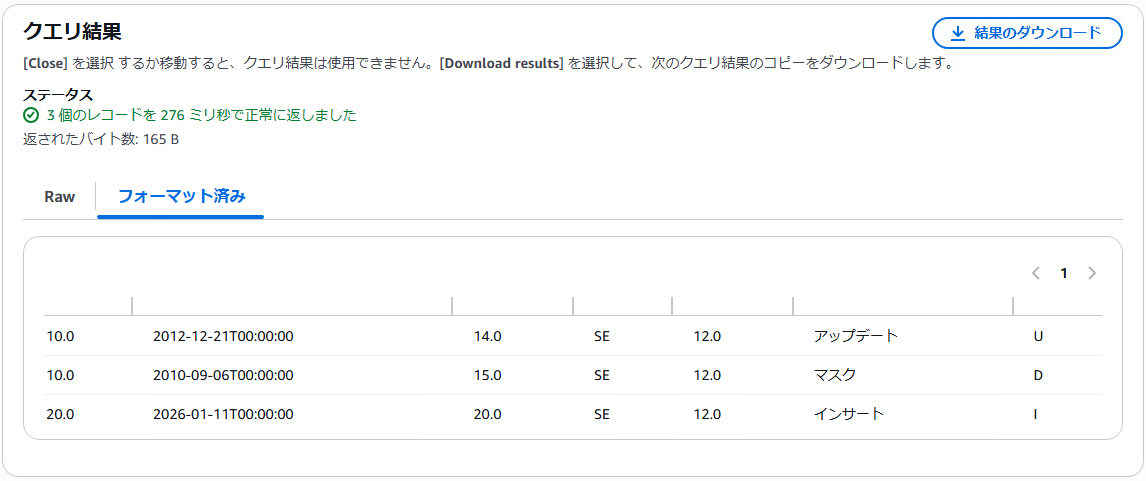
10.0,2012-12-21T00:00:00,14.0,SE,12.0,アップデート,U
10.0,2010-09-06T00:00:00,15.0,SE,12.0,マスク,D
20.0,2026-01-11T00:00:00,20.0,SE,12.0,インサート,I同様に符号(I:Insert、U:Update、D:Delete)が追加されており、削除操作に関してはUDFにより、マスクへ変換され同期されていることを確認できます。
このように簡単に構成でき、既存データが必要なデータのみを、データ分析の基盤となるストレージへ、効率の良いParquet形式で同期できます。
スケジュール、同期間隔について
また、上記のようにスナップショット:snapshotとCDC:changesに分かれて保持されますが、同期の設定(エンティティ)は、スケジュールで実行を制御できるため、例えば定期的な全件(スナップショット)同期のみを行い、CDCは実行しないといった設定も可能です。
加えてエンティティのオプション設定にてポーリングインターバル(ms)を変更することで、CDCで同期される間隔を調整できます。
リアルタイム性を高めるためデフォルトは100ms間隔でソースの変更を検知し、変更があれば同期するため、常に変更が発生しているテーブルの場合、changesに大量のParquetファイルが作成されることになります。
このような場合、この間隔を延ばして、5分おき(300000ms)に同期させるように変更するなどの対応も可能です。

 RSSフィードを取得する
RSSフィードを取得する


