


データグラビティへの対応を後回しにできない理由
重力は、計画的に身につけるものではなく、自然に身についてしまうものです。データの重力(データグラビティ)もまったく同じです。一時的に設定した(当初は一時的のつもりだった)データレイクが、気が付いたら世界の中心になっていたなんてことがあります。APIの統合やセキュリティポリシー、分析パイプラインをすべて同じストレージアカウントに帰属させて何とかやりくりしているうち、今さら環境を移行するわけにもいかず、せいぜいデータとワークロード間の移行を工夫するのが関の山となります。
そもそもデータグラビティとは何か?
「データグラビティ」とは、2010年にデイブ・マックロ―リ(Dave McCrory)氏が使いだした言葉で、このデータ管理を物理学の喩えた表現は、今でも真理を突いています。データは日々蓄積され、時間が経てば経つほど移行が難しくなります。本番環境のワークロードがデータに依存するからです。API、パイプライン、セキュリティ管理、その他もろもろのサービスが、データを中心に構成されていきます。やがて、システム環境は「重力井戸」と化し、アーキテクチャの意思決定を左右するようになります。数年前に設定したデータベース、データレイク、オブジェクト ストレージ、エッジ環境などが、将来のワークロードの実行場所を決めます。インフラストラクチャを自由に構成してきたつもりが、実際には、既存のデータがすべての意思決定を開発者の代わりにするようになります。歳を取ると重力に逆らえなくなるように、開発者はデータに逆らえなくなるのです。
つまり、データグラビティは、クラウド戦略に大きく影響する現象です。AIの活用、バックアップ戦略、障害復旧(DR)プラン、ネットワーキング、コンプライアンス、ベンダー管理など、すべてがデータグラビティには逆らえません。気づいたときには、重力のような抗い難い力に可動性を奪われています。デイブ・マックロ―リ氏の用いた比喩は、エンタープライズ アーキテクチャの宿命を極めて端的かつ的確に言い得ています。
2026年はデータグラビティの分水嶺
2026年は重要な転機を迎えています。5年前と比べても、企業データのあり方は規模、配置、戦略の面で大きな広がりを見せています。明らかに、それを加速させているのはAIです。最新のAIシステムは、ドキュメント、トランザクションデータ、テレメトリーストリーム、画像、ロゴ、履歴データセットなどを活用しますが、それらをすべて専用のAIプラットフォームに移すのは、時間も費用も相当かかるし、そもそも不可能な場合も少なくありません。結局、データを一元化して中央管理することはあきらめ、GPU、推論サーバー、RAG(検索拡張生成)パイプラインを既存のデータセットの近くに配置することになるのが一般的なパターンです。しかし実際には、これは将来のインフラストラクチャプランを左右する重大な決定事項です。AIの導入に前のめりな企業は多いですが、ハードウェアをどこに置くかという現実的な問題にまず向き合うことを忘れてはなりません。
クラウドのコストも重要な決定要因です。ほとんどのクラウドプロバイダではインバウンドの移行が安価または無料なのに対し、リージョンやマルチクラウドにまたがる移行やアウトバウンドの移行は、ボリュームが増えれば、その分費用もかさみます。これは帯域幅の問題だけではありません。大規模なマイグレーションには、テスト、オーケストレーション、ダウンタイム プランニング、ロールバック手順、アプリケーションの再構成などが必要となり、相当な手間と時間と費用を割り当てなければなりません。20TB程度の環境なら、まだポータブルに感じられるかもしれませんが、ペタバイトレベルになると、実現可能性がかなり遠のきます。
エッジ環境のデータも日々増え続けています。工場、病院、店舗、車輛、支社などで、日常業務にともない蓄積されるデータは膨れ上がる一方です。このような生のイベントデータすべてを一元化された中央のプラットフォームに送るのは、不合理であったり、もはや技術的に不必要であったりします。エンタープライズ環境では、データをローカルで処理し、サマリーやフィルタリングされたデータのみをリテンション用に中央に送って保存する傾向にあります。
このようなコスト面や物理的な問題に加え、データ主権に関する法的側面も見逃せません。たとえば、GDPR(EU一般データ保護規則)やEUデータ法(Data Act)、インドDPDP(デジタル個人データ保護)法など、世界各地の法規制によってデータのローケーションがアーキテクチャの主要な制約となっています。データレジデンシーと国境をまたぐデータ移転の制約は、今やインフラストラクチャの配置を決める直接的な要因です。
データグラビティの成り立ち
データグラビティを生み出す要因は、ボリューム、レイテンシ、帯域幅、ガバナンスの4つです。これらは必ず同時に同レベルで発生するわけではなく、1つの要因が他の要因を上回ったりするなど、開発チームによって状況は異なります。
もっともわかりやすいのは「ボリューム」です。データセットが大きくなればなるほど、コピー、レプリケーション、マイグレーション、検証が難しくなるのは当然と言えます。しかし、データは徐々に継続的に増えていくので、問題が表面化する(データグラビティに気づく)のに時間がかかるのが一般的です。
次に顕著な要因は「レイテンシ」です。不正検出プラットフォーム、業務管理システム、医療画像処理ワークフロー、AI推論パイプラインなどは、すべて運用データへの低レイテンシアクセスを必要とします。少しの遅れがレスポンス要件を逸脱し、業務に影響をきたす結果になります。離れたリージョンのデータレイクにAI推論を実行してレイテンシの壁に直面し、データの往復だけでSLA違反になってしまうケースも珍しくありません。
その物理的な要因が「帯域幅」です。データの転送が技術的に可能であっても、スループットがメンテナンス時間やリカバリ目標の範囲内での転送をサポートしないケースが多々あります。
さらに、これらとは異なる側面から大きな制約を生むのが、「ガバナンス」です。法令順守のために、データをリージョン、テナント、施設、クラウドプラットフォームから外に移行できない場合があります。帯域幅やレイテンシと違い、ガバナンスの制約はエンジニアリングではどうしようもできない問題です。
データグラビティを生み出す4つの要因は、製造業を例にとると具体的にイメージしやすいです。最新の生産ラインは毎日数十テラバイト分の処理データやテレメトリーを生み出します。これを中央管理用のクラウドプラットフォームに転送するのはレイテンシを高め、ネットワークを過度に消費し、コンプライアンス違反につながるリスクがあります。このため、ほとんどのアーキテクチャではデータをローカルで処理し、ストリームのフィルタリング、推論の実行、不正検出、短期間の履歴管理などをデータソースの近場で実施しています。中央に送るのは要約されたインサイトのみというパターンが多いです。昨今のインフラストラクチャ設計では、データグラビティがあちこちで発生しているのが現状です。
データグラビティの功罪
データグラビティは悪いことばかりではありません。データが集中しているということは、そのプラットフォームの有用性を高めます。ガバナンスに一貫性が保たれ、セキュリティポリシーを施行しやすく、アクセス制御も予測が立ちやすく、効率的になります。部門間で一貫性を欠いた情報の重複が起きにくく、アナリティクスなど、さまざまなプロセスを簡素化できます。データセットとトレーニングの一貫性によってAIイニシアチブも推進され、バックアップとリテンションの標準化でセキュリティ管理も効率化されます。
しかし、このデータの集中が硬直化し出したとき、データグラビティの問題点が顕在化し始めます。数ペタバイトに達したデータレークを移行するのには相当な費用がかかります。アプリケーションの性能は、ローカルのレイテンシに左右され、API、インデックス、パイプライン、レポート、バックアップジョブがすべて、そこにデータがあることを前提として設計されてしまいます。やがてマイグレーションが困難になり、クラウドの出口コストが法外になります。よって、マルチクラウド戦略を立て難くなり、ベンダーロックインが長期的な懸念事項になります。かつてガバナンスを効率化したデータ集中は、アーキテクチャの機動性を奪う足かせと化します。
データ転出の問題
クラウドのEgress(送信トラフィック)費用は、データグラビティに関わるもっともわかりやすい問題の一つです。パブリッククラウド プラットフォームは通常インバウンドのデータ移転を安価に設定する一方、アウトバウンドにはまったく異なる対応をします。データが比較的小規模なうちはEgress費用も些細な出費に感じられるかもしれませんが、初期段階からエンタープライズ環境におけるマイグレーション計画の一環として「データ転出」を考慮しておくべきです。データがペタバイトレベルになると、たとえ1ギガバイト数セントの料金でも、1回の移転費用が数十万ドルになり、これにデータの準備やテスト、ダウンタイム費用を加算したら、決して看過できない出費となります。
データの移行後はデータの整合性の検証、パイプラインの再調整、アクセス制御の再設定、アプリケーションの再構成などが必要になります。マイグレーションが失敗した場合のロールバック手順も策定しておかなければなりません。マイグレーションはいざ手を付けてみると、次から次へと想定外の費用が嵩んでいきます。
クラウドの導入が間違っていたというわけでは決してありません。多くのワークロードにとって、パブリッククラウド インフラストラクチャが運用上も経済上も最適解であることに変わりはありません。重要なのは、データセットはいつまでもお手軽サイズで維持できるものではないことを念頭に、どこに配置するか、どのようにアクセスするか、どの程度拡大しているかを検証し、早めに出口戦略も用意しておくことです。それによってアーキテクチャの柔軟性に大きな差が出ます。
エッジ環境のデータグラビティ
エッジ環境では小規模の「重力井戸」が発生し、全体的なインフラストラクチャ マップにおいて重力井戸が散在することになります。工場、病院、小売店、車両などで、機械、センサー、カメラ、ユーザーからデータが生成され続けます。これら生のイベントデータを中央のデータセンターに送るにはかなりの時間と費用がかかり、合理的ではありません。当然ながら、エッジアーキテクチャがローカルでデータを処理する仕組みが一般化されつつあります。
したがって、AI推論、フィルタリング、圧縮、集約、不正検出、短期ストレージなどが、データソースのそばで実施される傾向にあります。この仕組みは、製造業、小売店の監視カメラ処理、医療用の画像処理、エネルギー、自動車などに適用されており、「エッジデータグラビティ」がコンピューティングとストレージをデータ発生場所の近くに配置する大きな要因となっています。WANリンクがカメラフィードを処理できないために、エッジクラスタが生産環境のデファクトスタンダードになっている工場施設もあります(かつてオンプレミス ストレージの絶滅を予測した経済分析が近年その予測を撤回したのも、まったく同じ理由です)。
AI時代のデータグラビティ
最新のAIシステムは、信頼できる運用データへの直接アクセスに大きく依存しているため、AIがデータグラビティを加速させる状況が起きています。トレーニング、ファインチューニング、検索と推論のワークフローなど、あらゆる機能がデータセットに直接関わることで効果を発揮しています。データの機密性や制約が高ければ高いほど、別のAI環境にエクスポートすることが実用的でなくなっています。
もっとも顕著な例はRAG(検索拡張生成)です。RAGシステムは、ドキュメント、データベース、ファイル共有、チケット履歴、知識ベースへのアクセスを必要とします。このようなデータ群を新しいAIプラットフォームにエクスポートするのは、セキュリティ、レイテンシ、データ重複のリスクを生じさせます。このため、一般的には、すでに管理されているデータソースにAIレイヤーを追加する構成が最適解とされています。
これは、インフラストラクチャのゲームチェンジャーとも言えます。コンピューティングの配置は、これまでのようにリソースが安く済む場所、ではなく、データに安全で効率的かつ低レイテンシでアクセスできる場所が重視され、GPU、推論サーバー、AIサービスが既存のデータレイク、オブジェクトストア、ウェアハウス、エッジストレージ プラットフォームのすぐそばにデプロイされるようになっています。
データグラビティ vs データ主権
データグラビティとデータ主権は相互に深く関係するものですが、データに対する見地が根本的に異なります。データグラビティは物理的、運用的、経済的な制約であるのに対し、データ主権は法規制にもとづくものです。前者は、データの効率的な移動を難しくさせますが、後者は効率に関係なく、ルール上、移動を制限したり、禁じたりするものです。
| 属性 | データグラビティ | データ主権 |
| 制約の種類 | 物理的、経済的 | 法規制 |
| 主な要因 | データセットのサイズ、レイテンシ、帯域幅、移行コスト | 地域の法令や条例、業界のルール、契約 |
| 制限対象 | データとワークロードの移動 | データが許容されるロケーション |
| 典型的な対応 | ハイブリッド アーキテクチャ、エッジ プロセシング、アナリティクスの連携、クラウドからのデータ転出 | 地域的デプロイメント、テナントの隔離、国内ストレージ |
| 例 | マルチペタバイトのデータレイク マイグレーション費用が高額に | 欧州の個人データはGDPRとデータ法に則って管理 |
本番環境では通常、データグラビティとデータ主権が互いに作用しあって制約を強める傾向があります。データ主権の要件によって、データは特定の行政区または国内に留められます。データが拡大するに連れ、アナリティクス プラットフォーム、AIサービス、バックアップシステム、アプリケーションが自然にデータのそばに引き寄せられ、やがて、法的な境界線とアーキテクチャの境界線は一体化していきます。
データグラビティの管理方法
データグラビティを無くすことはできません。しかし、運用上の影響が少なくなるようにインフラストラクチャを設計することはできます。データセットが大きくなりすぎて、効率的な移行が困難になる前に手を打つことが重要です。
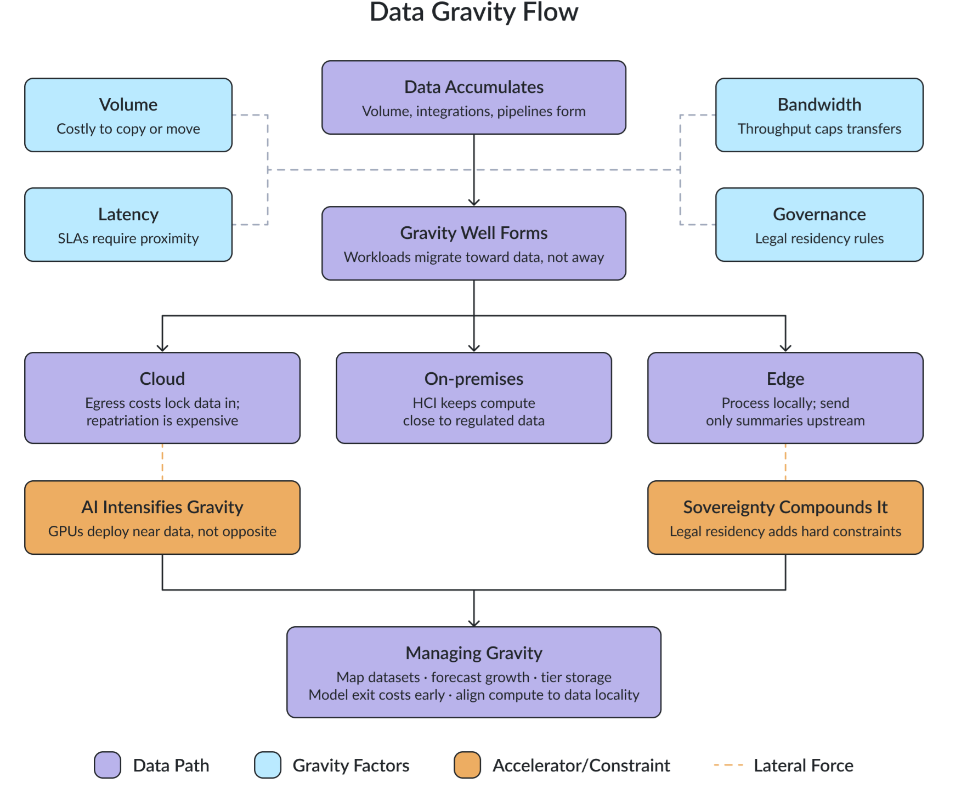
Figure 1: Data gravity forming process and mitigation
最初のステップは可視化です。重要なデータセットの構成を図にして、どのアプリケーションがどのデータセットに依存しているのかを特定し、データがどのくらいの速さで拡大しているのかを評価します。マイグレーションは早期から費用を見積もり、移転費用以外に、エンジニアリング、テスト、ダウンタイム対応、バックアップ再構成、アプリケーション依存関係、ロールバック要件など、さまざまな要素を考慮する必要があります。データセットが今後3年間で10倍に拡大する可能性はあるのか、現行アーキテクチャをそのまま移行することが合理的か、再編成が必要か、などを自問自答すると、より的確なプランニングが可能になります。
ワークロードはレイテンシの重要度に応じて区分する必要があります。すべてのアプリケーションにローカル データアクセスが必要なわけではありません。リモートアクセスに順応できるアプリケーションもあれば、リアルタイム レスポンスタイムに依存するアプリケーションもあります。この違いを理解することは、効果的なアーキテクチャ構成に不可欠です。
データの階層分けも依然として、もっとも効果のあるオペレーション管理と言えます。ホットデータはアクティブなコンピューティング リソースのそばに配置しなければならなず、ウォームデータは低コストでもアクセスしやすいストレージ階層に、コールドデータはアーカイブ プラットフォームに配置します。ただし、ビジネスとコンプライアンスの要件を満たすリカバリタイムを確保することが前提条件となります。
エッジ環境では、処理をローカルで完結することで帯域幅の消費と、不必要な中央へのトラフィックを最低限に抑えることができます。ハイブリッド アーキテクチャでは、ワークロード ビヘイビア、レイテンシ要件、ガバナンスの制約、運用上の経済性にもとづいてリソースを選択することが重要で、組織で標準化された既存のデプロイメント モデルにとらわれすぎなようにすべきです。マイグレーションはすべからく1つの問いを端緒とすべきです。取締役会の予算承認なしに3年で移行を完了できるのか否か(この問いを省略したために、クライアントが“臨時で”設定した400TBのデータウェアハウスをリージョンの廃止に際して移行するのに、上層部からゴーサインを得るだけで11か月を要した実例があります)。この問いへの答えが否である場合、データセットは今すぐ階層分けが必要です。
コンピューティングはどこで実行されるべきか?
| 配置先 | 最適リソース | 考慮事項 | データグラビティの視点 |
| クラウド | 柔軟なアナリティクス、SaaS統合、その他 | Egressトラフィック、リージョンの選択、長期保存費用 | データの長期保存が可能な場合に有効 |
| オンプレミス | 規制対象データ、予測可能なワークロード、低レイテンシ アプリケーション | 容量、ハードウェア ライフサイクル | コンピューティングの近くでデータ管理 |
| エッジ環境 | センサーデータ、ビデオ、ローカル推論、非接続サイト | 複数ロケーションにまたがるオペレーション | データを中央に送る前にローカル処理 |
| ハイブリッド環境 | 複合クラウド、オンプレミスおよびエッジのニーズ | ガバナンスとツールのスプロール | 各ワークロードをそれぞれの重要データのそばに配置 |
ワークロードが機能するために環境をまたぐデータ移動を継続的に必要とする状況は、配置モデルの再考が必要なサインです。
HCIの役割とオンプレミス ストレージ
データグラビティの影響を受けやすいワークロードをオンプレミス環境で実行する場合、余計なインフラストラクチャ レイヤーを追加せずにコンピューティングをデータのすぐそばに配置するのは、簡単ではありません。
そのような環境には、ハイパーコンバージド インフラストラクチャ(HCI)が最適です。HCIでは、コンピューティングとストレージ リソースを同じ環境で組み合わせ、レイテンシを低減すると同時に、クラウドに簡単には移動できないワークロードの運用を簡素化できます。
たとえば、StarWindのVirtual SAN(VSAN)を使用すると、ハイパーバイザーホストのローカルストレージを可用性に優れた共有ストレージにまとめてHCTクラスタを構成することができます。データグラビティの観点で言えば、アプリケーションを物理的に運用データの近くに配置でき、SANインフラストラクチャを別に管理する手間とコストを回避することができます。事前構築されたデプロイメント モデルがよりニーズに合う場合は、 StarWind HCIアプライアンス(HCA)を細かな設定なしでそのままHCTプラットフォームとして利用するのも得策です。
データセットは今や、従来のVMを中心としたインフラストラクチャ パターンでは賄い切れない規模にまで成長してきています。非構造化データ、アーカイブ コンテンツ、AIデータセット、メディア リポジトリ、そしてエッジ環境のデータは日々増大し続けており、大規模な分散オブジェクト ストレージ環境にはDataCore Swarmのようなソフトウェア定義のオブジェクトストレージ ソリューションが必要になっています。それによって、クラウドリポジトリでの中央管理に依存することなく、分散環境のデータアクセスを維持しながら、ストレージを水平方向にスケーリングすることができます。VMをデータの近くに配置するためだけに新しいストレージアレイの導入を検討しなければならないとき、HCTにしておけばよかったと後悔する開発チームは少なくないはずです。
FAQ(よくある質問)
データグラビティが今、注目されている理由は何ですか?
AIの導入、エッジ環境でのデータの拡大、クラウドの移転費用、データ主権ルールなど、あらゆる要因によってデータの配置がアーキテクチャのあり方を左右する重要な決定事項となっています。コンピューティング、アナリティクス、バックアップ、AIインフラストラクチャをどこにデプロイするかは、今やデータがどこにあるのかによって決まります。
データグラビティはクラウドストレージにどのように影響しますか?
マイグレーション、マルチクラウドの構成、クラウドからのデータ転出などが、データグラビティによって複雑化します。大規模なデータセットが1つのクラウドプロバイダに蓄積されると、その移行には高額な転出費用、長期間のマイグレーション プロセス、大量の確認作業がともないます。
データグラビティはベンダーロックインと同義ですか?
いいえ、ベンダーロックインはデータグラビティがもたらし得る1つの現象にすぎません。データグラビティにはより幅広い事象が関連し、データのサイズ、レイテンシ、帯域幅、コスト、ガバナンス、法的制約などが含まれます。
AIはデータグラビティの増加にどのように影響しますか?
AIワークロードは、信用できる大量のデータにアクセスできてはじめて機能します。コンピューティングが、ガバナンスの整ったデータソースの近くで実行されることで、AIモデルのトレーニング、ファインチューニング、検索や推論がより機能性を発揮できるようになります。
データグラビティとデータ主権の違いは何ですか?
データグラビティは物理的および経済的な制約ですが、データ主権は法的な制約です。データグラビティによってデータは移動しにくくなりますが、データ主権は(制約が適用される場合)データの移動そのものを許可しません。
データグラビティのリスクを軽減するにはどうすればよいですか?
全体的な環境における重要データセットの構成を可視化して、データの拡大傾向を予測し、早期にマイグレーション費用を見積もります。ストレージを階層分けし、エッジ環境のデータをローカル(現場)で処理し、コンピューティングの実行場所をデータの配置に合わせる必要もあります。また、データセットが移動できないほど大きくなる前に現実的な出口戦略を策定しておくことが重要です。
データグラビティの管理にHCIが有効な理由は何ですか?
HCTはコンピューティングとストレージを同じクラスタ内で連携させ、ワークロードをデータの近くで実行することでレイテンシを削減し、オンプレミスのデプロイメントを簡素化します。データを遠隔地のプラットフォームに送信することが現実的でない場合(規制対象の環境)やエッジ環境もサポートします。
まとめ
データの配置を、いつでも変更可能な優先順位の低いものと思っていると、あとで大きな代償を払うことになります。2、3月かけて事前に周到に準備するほうが、あとで付け焼き刃のマイグレーションを行うよりも、ずっと安くつきます。忘れてならないのは、データの寿命は現行のプラットフォームやベンダー、そしておそらく現在の仕事よりも長いということです。データの永続性と拡張性を念頭に置いてアーキテクチャを設計し、コンピューティングとデータの可搬性をガバナンスが許す範囲で確保しなければなりません。今日もっとも安く手軽に保存できた場所は、将来データを移行しなければならなくなったときに、それがもっとも安く手軽にできる場所とは限りません。データのグラビティはバグではなく、物理的、必然的な現象です。それを忘れずに、早期にプランニングすることが何より重要です。
 RSSフィードを取得する
RSSフィードを取得する







{kind=link}