
Syniti Data Replication(旧DBMoto)では、Apache Kafkaに対してのレプリケーションが追加されました。
膨大なデータ量を処理する必要があるビッグデータ解析や、毎秒IoTデバイスから転送されるデータを効率よく高速に処理したい、各種データソースからの変更をリアルタイムに別アプリケーションへ連携したい場合にApache Kafkaは最適なプラットフォームとなります。
Syniti Data Replicationを使用することで、数多くのデータベースに格納されているデータを、
Apache Kafkaに対してプログラミングすることなく、GUIからの設定のみで連携することが可能です。
ではまず、Apache Kafka接続の設定を見ていきましょう。
まず、データプロバイダとしてApache Kafkaを選択することで、自動的にデータプロバイダの読み込みが実行されます。
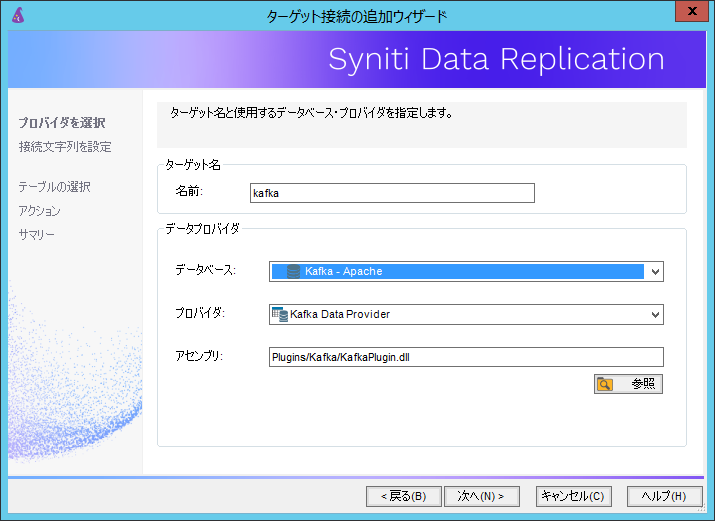
次に、接続ドライバの設定を行います。
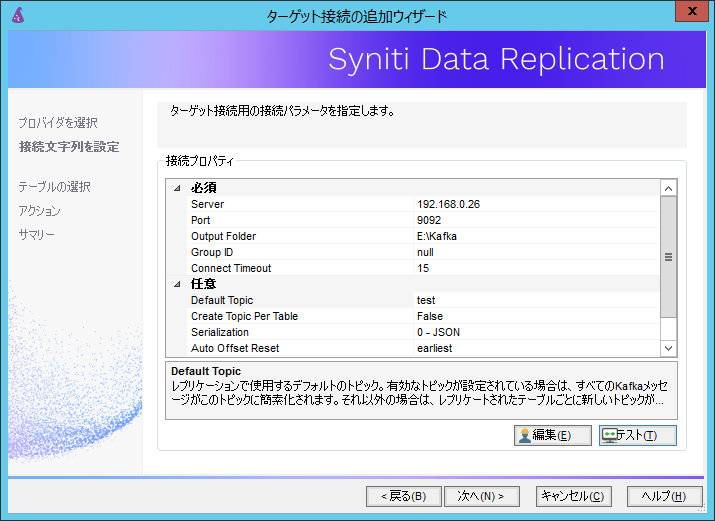
必須項目としては、Apache Kafkaが構成されているサーバのIPアドレスまたはホスト名、
レプリケーションに必要な一時ファイルを出力するフォルダパス、連携先となるApache Kafkaのトピックを指定します。
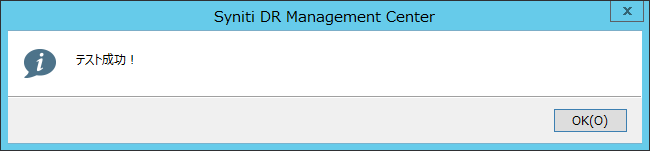
正しく構成できている場合、接続テストは成功と返ってきます。
以上で、Apache KafkaをSyniti Data Replicationコンソールへ登録することができます。
それでは実際にデータの連携を紹介していきます。
今回は、AS/400に存在しているレコードをApache Kafkaへ連携していきます。
まずは、Apache Kafka側の状態ですが、接続設定で指定されたtestというトピックが存在していることが確認できます。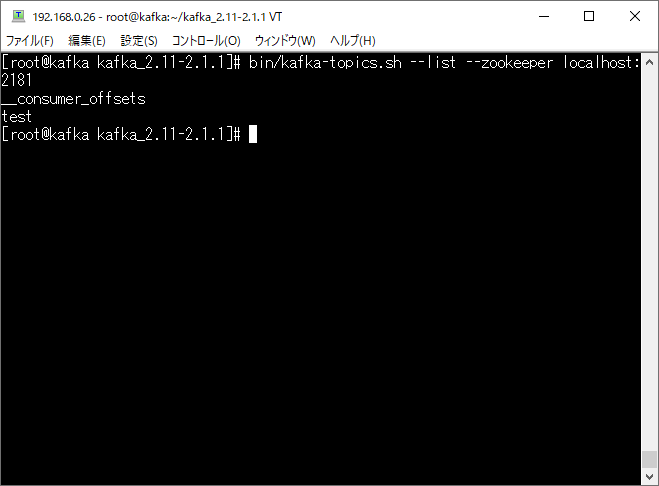
そして、実際に連携されるメッセージ(データ)を確認するため、Kafkaのコマンドを実行し待機します。
現在は、まだ何もデータが連携されていないことが確認できます。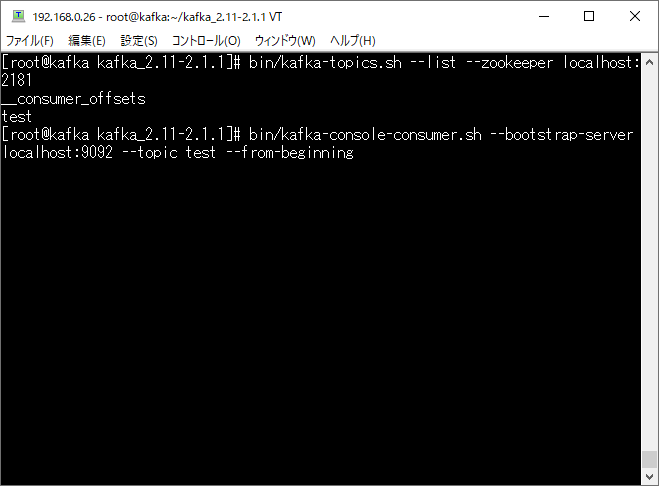
そしてSynitiコンソールからtestトピックに対してレコード参照を行っても、まだ何もレコードは確認できません。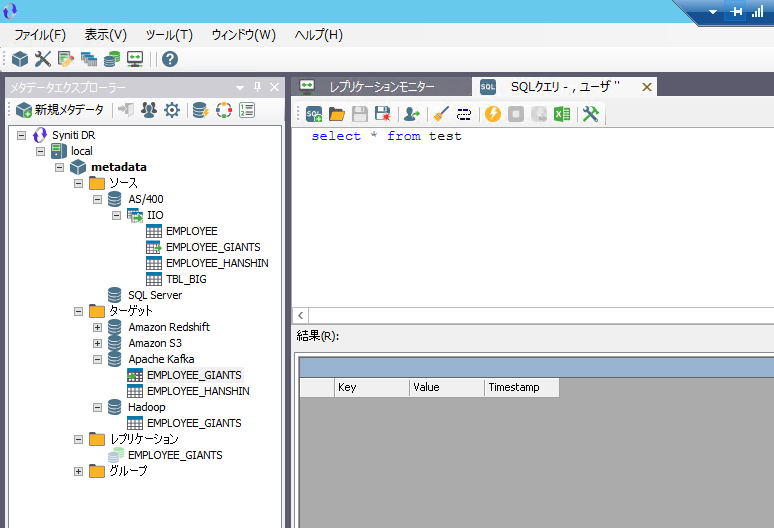
Synitiコンソールからレプリケーションジョブを作成し、実行することで、以下のようにApache Kafka側、Synitiコンソール側両方でデータが連携されていることがわかります。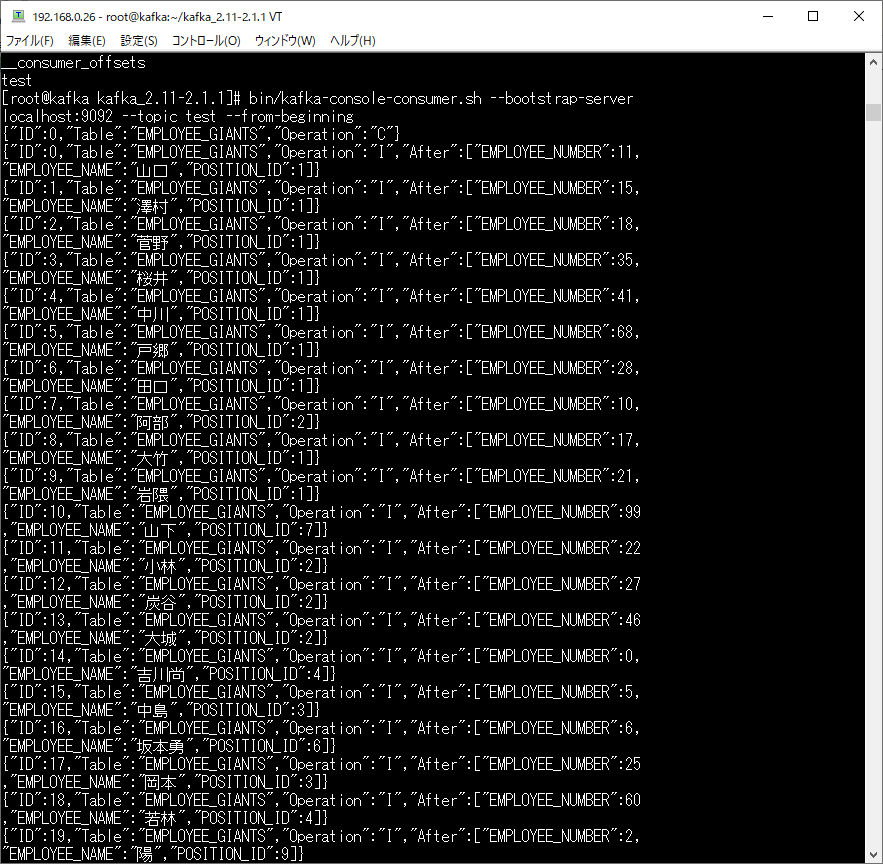
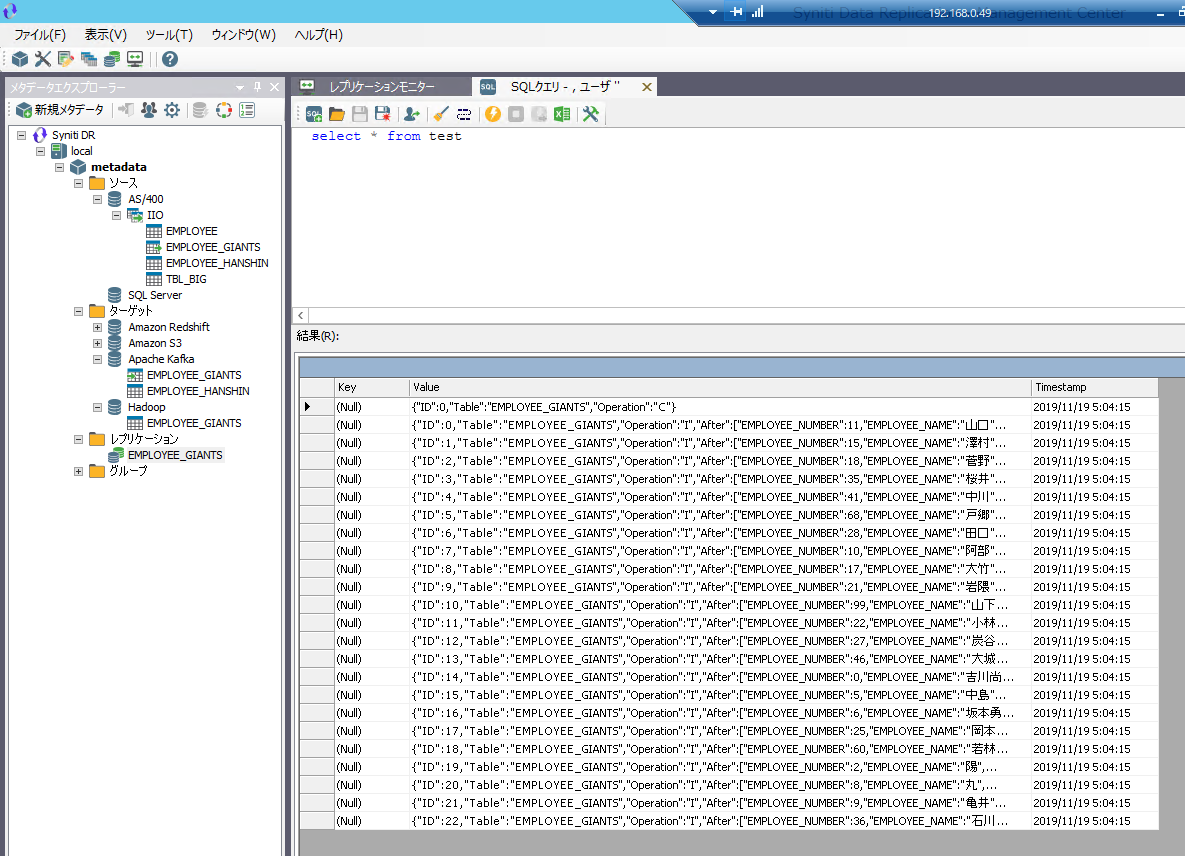
このように、Synitiを使用することでデータベースに格納された分析したいデータを、簡単にApache Kafkaへ連携することができます。
●Apache Kafkaへのデータレプリケーション設定デモ動画
Oracle から Kafka Streamsへのリアルタイム・データレプリケーション紹介動画

 RSSフィードを取得する
RSSフィードを取得する


