
データウェアハウス導入の手引き
ビジネスを運営すれば、日々データが増え続けます。業種や事業規模によっては、天文学的に増える可能性だってあります。昨今では、データをきちんと整理し、しっかり管理して、その状況を十分に把握しておくことが、健全なビジネス運営に欠かせない条件となっています。そして、その実現に必要となるのが、データウェアハウスです。
本稿では、そもそもデータウェアハウスとは何なのか、どのように機能するのか、を説明し、それをサポートするアーキテクチャモデルについて、さらに実用上の利点と課題についても紹介していきます。
目次
データウェアハウスとは何なのか?
データウェアハウス(Data Warehouse)とは、さまざまな媒体から集められる多種多様なデータを単一の組織化されたデータベースにまとめ、ビジネス上の意思決定をデータ主導で行えるように整理するためのシステムです。これは、特にビジネスインテリジェンス(BI)において威力を発揮します。BIは、履歴データと現行データの両方への迅速かつ構造化されたアクセスを必要とするので、データウェアハウスの質がBIの意思決定効果を大きく左右します。
データウェアハウスを構築するには、通常、以下の2つのアプローチがとられます。
トップダウン ― データウェアハウスの全体的な設計から始めて、部門ごとのニーズに合わせたデータマートの構築へと細分化していくアプローチです。
ボトムアップ ― まず部門に特化したデータマートを作成し、それらを統合して、より大規模なデータウェアハウスを構成していくアプローチです。
企業がデータウェアハウス構築時にどちらのアプローチを取るかは、ビジネスのニーズ、利用可能なリソース、プロジェクトのスコープなど、さまざまな要因によって決まります。
データウェアハウスを構成する要素
![]()
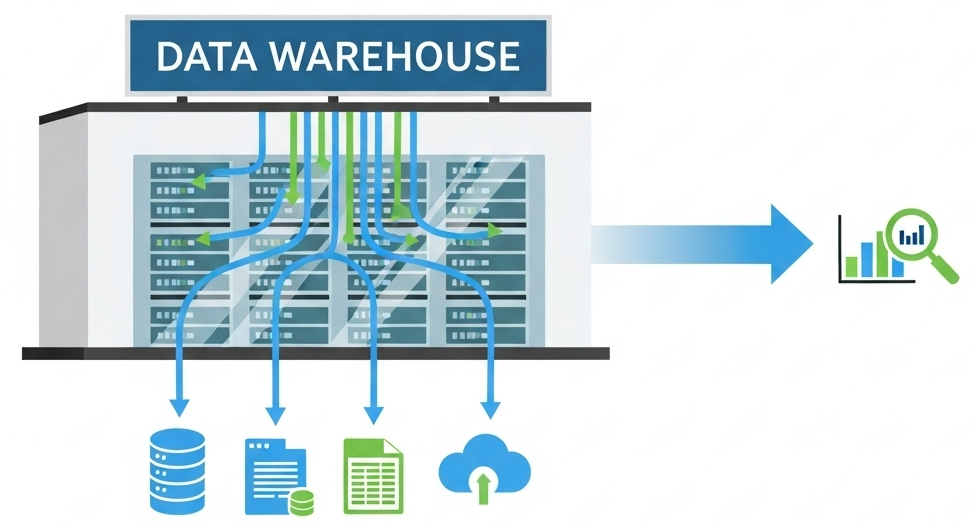
データウェアハウスは、主に4つのレイヤーから成り、それぞれのレイヤーがデータ処理パイプラインを構成するうえで重要な独自の役割を担っています。
データソースレイヤー
データソースレイヤーは、とれたての生の情報が集められた、データウェアハウスの基盤となるレイヤーです。これは、ビジネスの目的に応じ、従来型のシステム向けにはリレーショナル データベースのような構造化されたデータ群であったり、より最新型のシステム向けには、JSONファイルのような半構造化データや、画像、音声、センサーデータなどの非構造化データであったりします。
データステージングレイヤー
データステージングレイヤーは、ソースシステムから収集された生データの一時的な格納庫の役割を果たします。この段階では、データはまだ検証も標準化もされてなく、クリーンな状態ではありません。ステージングレイヤーが、生データをより精製されたデータレイヤーに移行する前のバッファーとなり、重複排除、フォーマット化、エラーの修正などを行える場を提供します。
データストレージ(ウェアハウス)レイヤー
データウェアハウスの中核となるレイヤーで、構造化され、統合されたフォーマットのデータが永続的に保存されます。前段階のステージングレイヤーで処理されたデータがここで整理整頓され、長期的な使用目的で格納されます。時系列に則ったデータの一貫性がここで確立され、いつでも分析可能な状態となります。
データアナリティクス(プレゼンテーション)レイヤー
構造化されたデータをユーザーが分析やレポートに利用できるようにする最終段階のレイヤーです。ダッシュボードやレポーティングツール、その他のユーザーインターフェースとここで統合され、ビジネスユーザーがストレージシステムを直接処理しなくてもデータを可視化して理解できる場を提供します。
データウェアハウス アーキテクチャの種類
データウェアハウスのアーキテクチャには単純なものから複雑なものまでいろいろあり、組織の規模、ビジネス目標、技術的ニーズなどに応じて、多種多様なアプローチでアーキテクチャが実装されます。ここでは、もっとも一般的なアーキテクチャ モデルを紹介します。
単一ティア アーキテクチャ
複数のレイヤーが論理的に(多くのケースでは物理的にも)単一のティアに統合され、実装されます。データの冗長性を排除できる利点がある反面、さほど高度な拡張性と柔軟性は期待できず、パフォーマンスのボトルネックを生じさせるリスクがあります。
2ティア アーキテクチャ
データソース/データステージング レイヤーとデータウェアハウス/プレゼンテーション レイヤーを論理的にも物理的にも切り離して実装するアーキテクチャです。中小規模のビジネスに広く採用されており、データとストレージの管理力により優れています。スケーラビリティと大規模データの処理面では多少の制約がともないます。
3ティア アーキテクチャ
データソース、ステージング、ストレージ、プレゼンテーションのすべての主要レイヤーを物理的、論理的に区別して実装する、もっとも一般的で安定したアプローチです。レイヤーを切り離すことで、拡張性、柔軟性、パフォーマンスのすべてを高次元で実現することができます。
最新のデータウェアハウス アーキテクチャ事情
最新のデータウェアハウスは、近年のITトレンドを敏感に取り入れたものが主流で、一般的に以下の特長を備えています。
クラウドネイティブ アーキテクチャ ― オンプレミスの制約を取り払い、簡易スケーリング、あるいはスケーリング オンデマンドを可能にします。料金は使用分だけを払うことができるので、初期投資を大幅削減できる「サーバレス」アーキテクチャとしての利点があります。また、すべてのデータをAWS S3やAzure Blobなどのストレージを使用する「データレイク」に保管できる点でも、コスト効率に長けています。
リアルタイム プロセシング ― 最新のデータウェアハウス アーキテクチャはContinuous Data Ingestion(継続的なデータ取り込み)を可能にすることで、オンデマンドの即時分析を実現しています。
AIとMLの統合 ― 大規模言語(LLM)モデルとの統合が進み、アナリティクスが機能的にも速度的にも強化され、より的確なビジネスの意思決定が可能になっています。
典型的なアーキテクチャには、データソース、ステージング、ストレージ、プレゼンテーションのレイヤーが含まれますが、設定方法によっては、レイヤーを部分的に組み合わせたり、逆に複数システムに分散させたりするバリエーションがあります。
![]()
的確なデータウェアハウス アーキテクチャ設計がもたらす効果
データウェアハウスを正しく設計、構造化することで、企業は確かなデータにもとづく迅速かつ的確な意思決定が可能になり、そのビジネス効果は計り知れません。データウェアハウスは、企業にとって、ビジネス戦略上の重要な資産となるものです。適正に設計されたデータウェアハウスには、以下の効果が期待できます。
パフォーマンスの改善 ― 必要なデータを必要な形で迅速に引き出せるので、レポーティングとアナリティクスの即応性と正確性が向上します。
データ品質の向上 ― データの質が上がれば、それにもとづいて動くビジネスの質も上がります。
スケーラビリティ ― データウェアハウスが正しく設計されていれば、将来のスケーリングが保証され、ビジネスの成長をサポートできます。
最新アナリティクスの統合 ― LLMモデルを活用した最新のデータアナリティクスで、ビジネスの意思決定がいっそう研ぎ澄まされます。
課題および検討事項
データウェアハウスの導入は、企業にとって非常に大きな一歩となります。そこから得られる効果も絶大であると同時に、思わぬ壁に直面する可能性もあり、入念な計画が求められます。実装方法によって直面しうる課題は異なりますが、すべての実装方法に共通した典型的な課題もあり、あらかじめ検証しておく必要があります。たとえば、以下の課題が挙げられます。
データ統合の複雑化 ― システムが拡大していくにつれ、新しいデータタイプやデータソースが追加されることは珍しくなく、データウェアハウスには継続的な調整が必要になります。明確な統合戦略をあらかじめ策定しておかないと、データのサイロ化やミスマッチが生じ、問題が複雑化は避けられません。
データ品質 ― データは人的な入力ミスであったり、部門ごとの定義の不統一であったり、旧式システムの併用などによって、簡単に品質が損なわれてしまいます。データの品質を保つには、データがシステムに入る段階でクリーニングや整合性の検証などを確実に実施する強力なガバナンスが求められます。
スケーラビリティとパフォーマンス ― データウェアハウスの設計に不備があると、パフォーマンスのボトルネックとなり、スケーラビリティを阻害して将来の成長の足かせになりかねません。適切な最適化が行われないと、データクエリの速度が低下し、ストレージ費用が増し、システムの反応も劣化します。データウェアハウスの導入時には、準備段階から将来を見据えた戦略的な設計が必要になります。
ビジネスの変化への適応 ― ビジネスが進化するとデータ要件も変わってきます。事業の合併や新製品の導入、レポーティング ニーズや顧客動向の変化など、データ要件に影響しうる要因は多く、すべての企業にとって、将来的にデータウェアハウスの調整が必要になるリスクは低くありません。
適正なアーキテクチャ設計とは
では、データウェアハウスのアーキテクチャを的確に設計するにはどうすればよいでしょうか。ここでは、設計段階で検討しておくべき重要事項を5つ紹介します。
1. ビジネス目標を明確に定義する ― データウェアハウスに何を求めているのか、データウェアハウスでどのような問題を解決したいのかを、あらかじめ明確にする必要があります。まず、自社のデータを十分に理解し、それがビジネスインテリジェンスにどのように活用できるのかを整理することが先決です。
2. データを監査する ― データソース、フォーマット、ボリュームについて詳細を記録し、データをいつでも監査できるように目録を準備しておく必要があります。データは企業にとって重要な資産であり、財産目録が必要になるのは当然と言えます。
3. デプロイメント モデルを選択する ― 利用可能なツールやプラットフォームを調べ、オンプレミス環境に実装するのか、完全にクラウド化するのか、両方にまたがるハイブリッド アプローチを採用すのかを決定します。
4. スケーラビリティを考慮する ― 潜在的なボトルネックを特定し、克服方法を事前に確認しておく必要があります。
5. 安定した自動プロセスを設計する ― 自動化された信頼できるExtract(抽出)、Transform(変換)、Load(ロード)またはExtract、Load、Transform(つまりETLまたはELT)パイプラインを設計することが、データを常に利用可能な状態に保つためには不可欠です。
代表的なデータウェアハウス ソリューション
Amazon Redshift ― すでにAWSを活用している企業にとっては有効な選択肢となります。
Google BigQuery ― 大規模なアナリティクス ワークロードに適しています。
Snowflake ― パフォーマンスとマルチクラウド サポートで高い評価を得ています。
Databricks ― ML/AIワークロードと非構造化データの処理に強いという評価が定着しています。
Azure Synapse Analytics ― すでにSQLとSparkを活用しているユーザーに適しています。
まとめ
最新のデータウェアハウスは、単なる情報リポジトリにとどまらず、データドリブンが求められる現代のビジネス環境で企業戦略を支える重要なアセットとなるものです。正しく準備され、考え抜かれたアーキテクチャ設計が、適切なテクノロジーとプラクティスでサポートされれば、データウェアハウスは組織全体に価値をもたらすビジネスの強力な武器になります。逆に言えば、準備が不十分だと、効果を発揮できないリスクがあります。データウェアハウスを導入するからには、ビジネス目標に合致した的確なアーキテクチャを設計し、データ品質を維持し、スケーラブルなソリューションを確立してビジネスへの効果を最大限に高めましょう。
 データウェアハウスのためのコスト効率とパフォーマンスに優れたストレージ ソリューションをお探しの場合は、お気軽にクライムにご相談ください。たとえば、StarWind Virtual SAN(VSAN)は、Hyper-V、vSphere、KVMクラスタ向けに高可用性(HA)に優れた共有ストレージを実現します。StarWind VSANでは、ハイパーバイザーホストのローカルストレージを利用して、仮想マシン(VM)向けに共有HAストレージを確保できるので、抜群の費用対効果が期待できます。詳しくは、クライムサポートまで。
データウェアハウスのためのコスト効率とパフォーマンスに優れたストレージ ソリューションをお探しの場合は、お気軽にクライムにご相談ください。たとえば、StarWind Virtual SAN(VSAN)は、Hyper-V、vSphere、KVMクラスタ向けに高可用性(HA)に優れた共有ストレージを実現します。StarWind VSANでは、ハイパーバイザーホストのローカルストレージを利用して、仮想マシン(VM)向けに共有HAストレージを確保できるので、抜群の費用対効果が期待できます。詳しくは、クライムサポートまで。
関連したトピックス
- Azure Synapse Analytics(旧 SQL DW)へのレプリケーションを検証してみました[Syniti DR]
- データ分析基盤へもSyniti Data Replication(旧DBMoto)で簡単レプリケーション! Google BigQueryへの接続方法
- Parquetで連携し、より効率的なデータ分析を簡単に実現【Gluesync】
- ビッグデータ分析のためのデータウェアハウスAmazon Redshiftの特長と利点
- Syniti ReplicateによるRFCを使用したSAPシステムからのデータレプリケーション
- Gluesync for Google BigQuery: Google BigQueryとのシームレスなデータ同期を実現する最速のソリューション
- Microsoft SQL Server の高可用性: Always On 可用性グループとフェールオーバー クラスター インスタンスの比較: 選択基準と適用タイミング
- Snowflake Target Connectorのサポートで:Gluesyncとのシームレスなデータ統合へ
- Amazon RedShift ターゲットエージェント:Gluesync による高性能クラウドデータウェアハウスへ
- Amazon Redshiftに対してOracle、AS/400、SQL Server、MySQLなどからデータをリアルタイムにレプリケーション[DBMoto]

 RSSフィードを取得する
RSSフィードを取得する


