
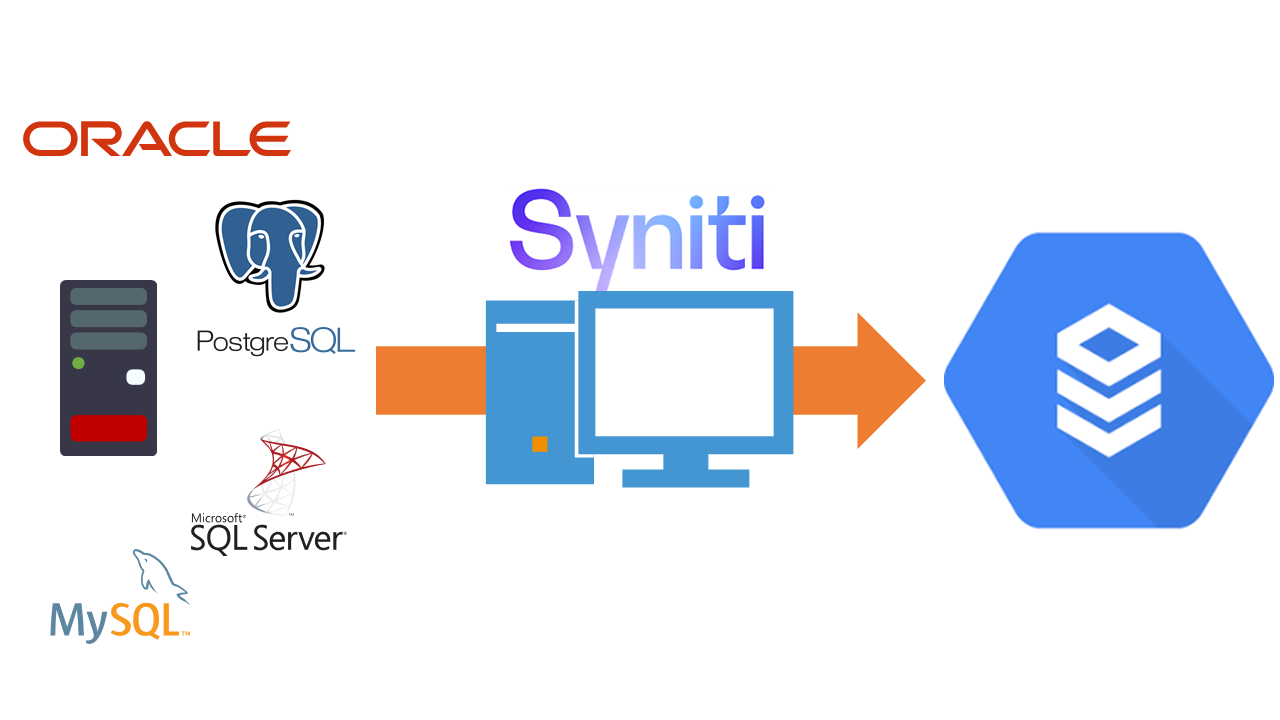
昨今、データ活用が注目され、企業が保有しているデータを分析用のプラットフォームへ移動する需要が増えています。
このようなデータプラットフォームに対して、Syniti Data Replication(以下Syniti)を利用することで、あらゆるRDBMSからDWHなどのデータプラットフォームへ開発を行うことなく手軽にデータ連携が可能です。
※Synitiがサポートしているデータベースについては、こちらをご覧ください。
本ブログでは、Google Cloud Platform(以下GCP)が提供しているGoogle BigQueryへのレプリケーションを紹介します。
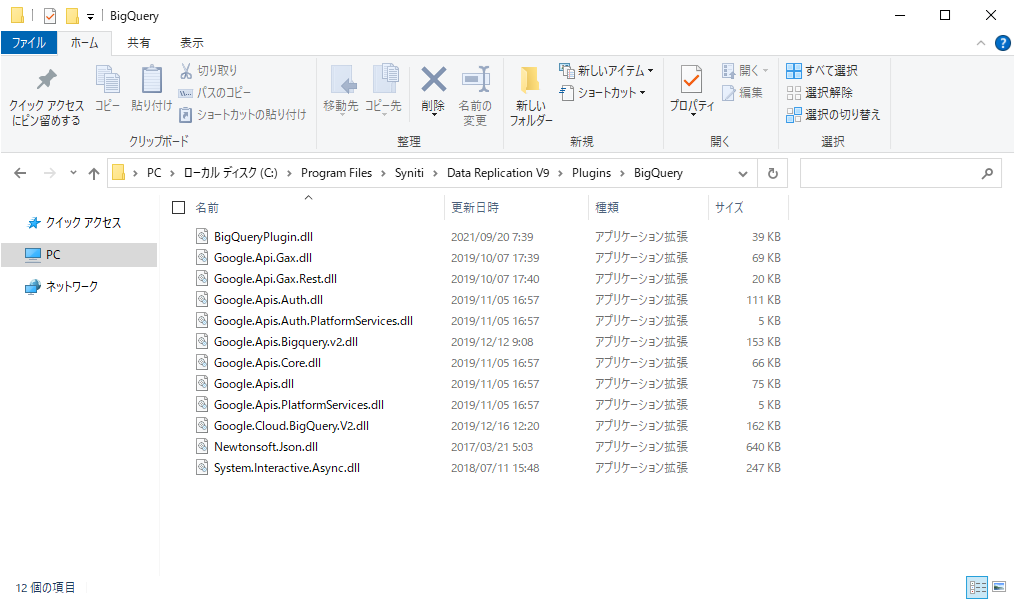
まず、Synitiのインストールフォルダに、Google BigQueryへ接続するためのdllファイルを配置する必要があります。
デフォルトでは、以下のパスにファイルを配置する必要があり、ファイルについてはこちらよりお問い合わせください。
C:\Program Files\Syniti\Data Replication V9\Plugins\BigQuery
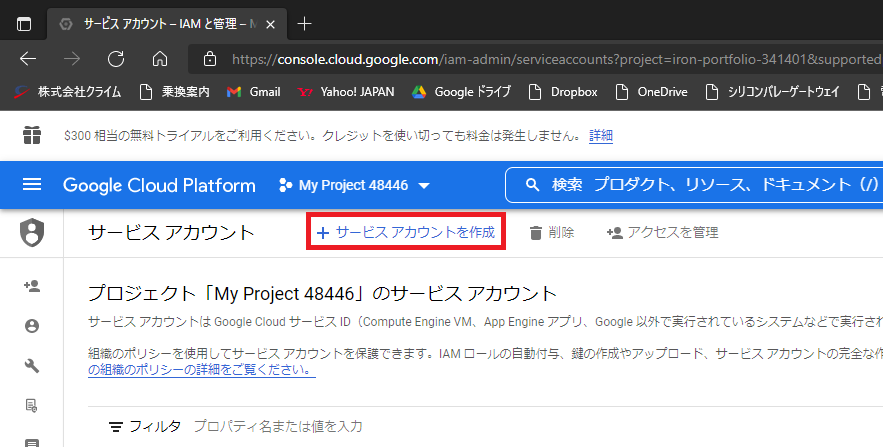
配置が完了したら、次にGoogle BigQueryへのサービスアカウントキーを取得します。
GCPのWebコンソール画面にて、「サービスアカウントを作成」をクリックします。
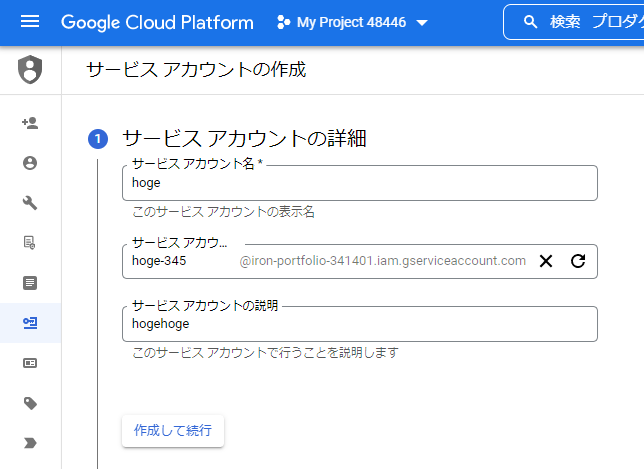
任意のサービスアカウント名を指定し、「作成して続行」をクリックします。
サービスアカウントに対して、BigQuery > BigQueryデータオーナーとBigQueryジョブユーザーのロールを付与します。
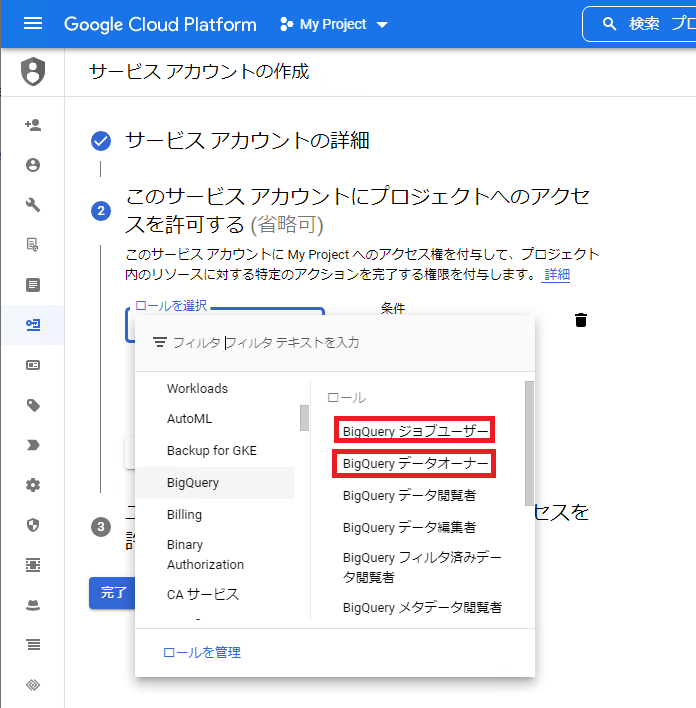
最後に、作成されたサービスアカウントを選択、「新しい鍵を作成」よりJSON形式のアクセスキーファイルをダウンロードし、Synitiインストールマシンの任意のフォルダに保管します。
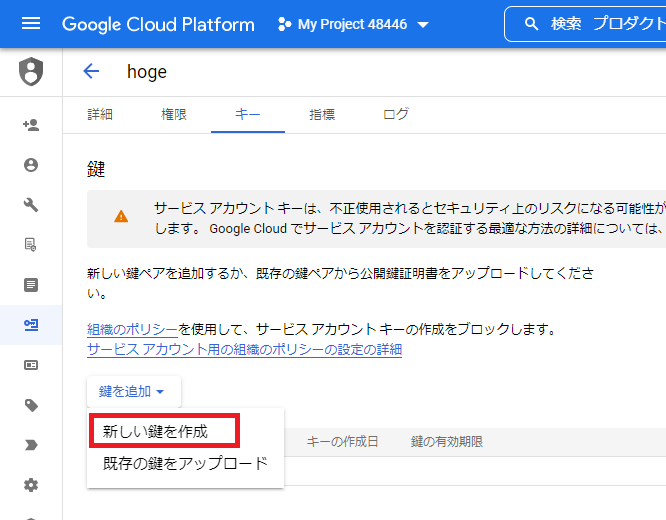
ここまで完了したら、SynitiのコンソールからGoogle BigQueryとの接続を定義します。
接続の指定は、すべてGUIから行います。
データベース項目では、Google BigQueryを指定します。
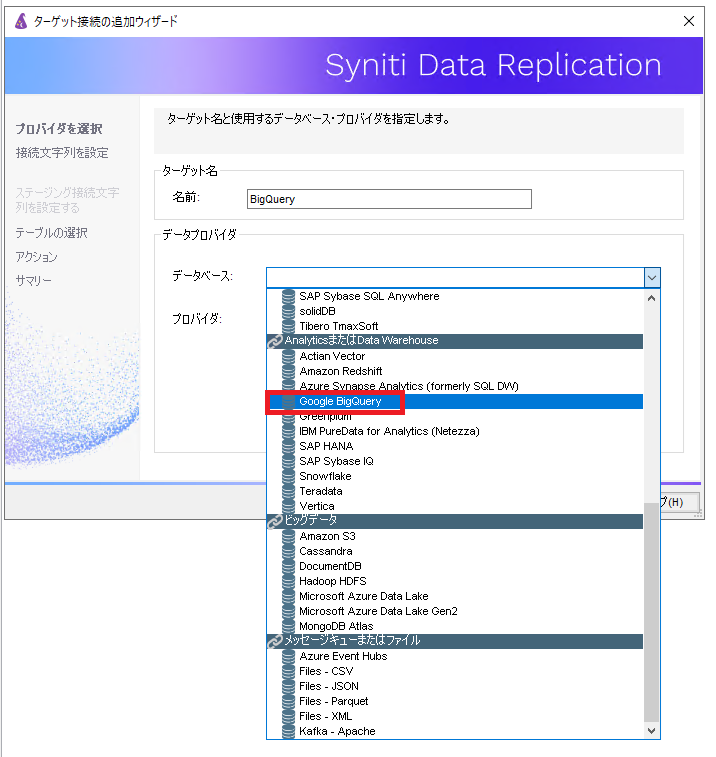
プロバイダ、アセンブリ項目は自動入力されるため、変更する必要はありません。
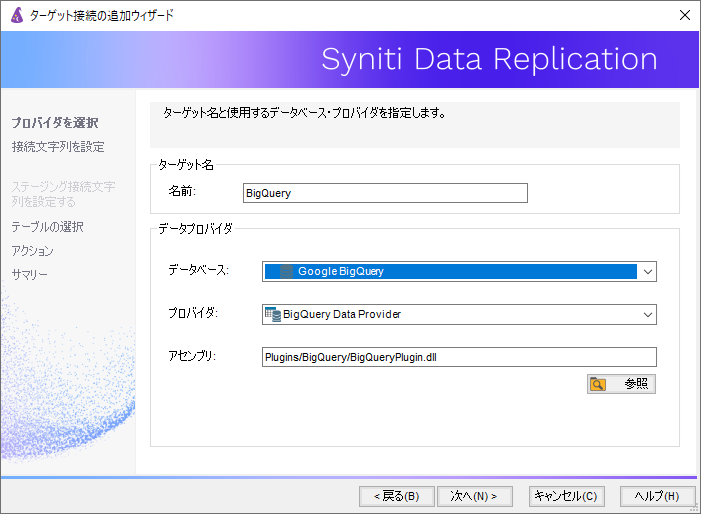
次に、BigQueryへの接続に必要なパラメータを入力します。
Project ID項目:データ連携先のプロジェクトID
Service Account Key項目:GCPより生成したアクセスキーファイル(JSON形式)
Output Folder項目:レプリケーション時に生成される一時ファイル保存先
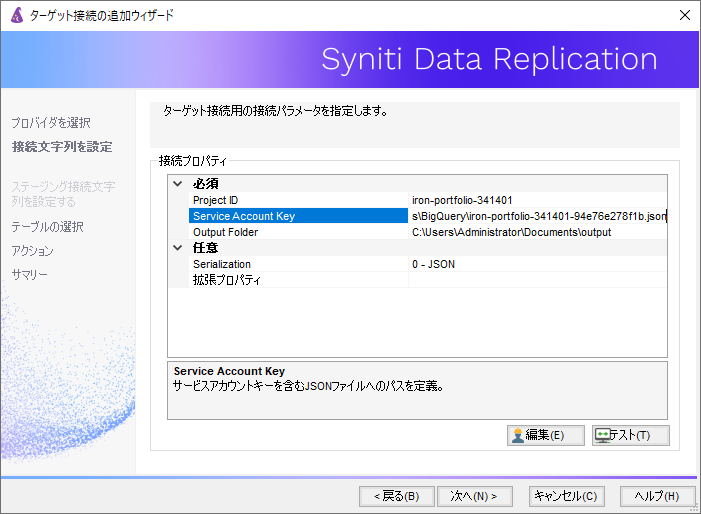
テストボタンをクリックし、SynitiマシンとGoogle BigQuery間で接続が行えるか確認も可能です。

あとは、次へボタンで進めることで、Google BigQueryとの接続設定が完了します。
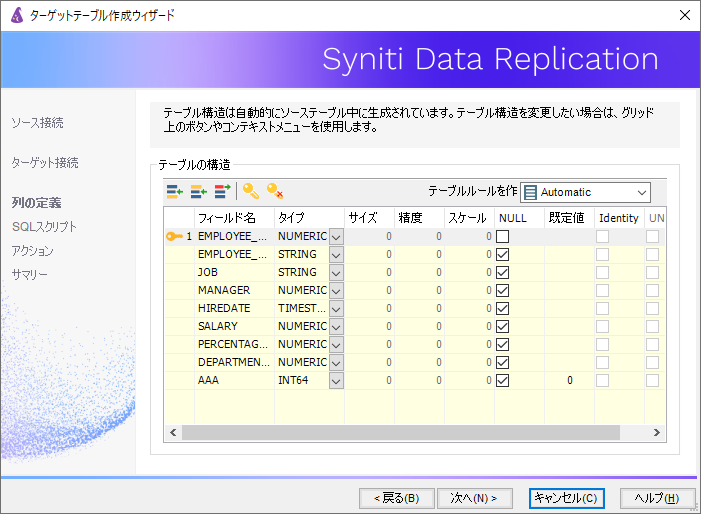
次に、SynitiのGUIより、Google BigQueryに対してレプリケーション先のテーブルをします。
連携元のソーステーブルの構成を取得し、Google BigQueryに相応しい形でテーブルが作成されます。
テーブル作成が完了すると、Google BigQuery接続のツリー内に表示されます。
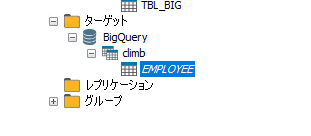
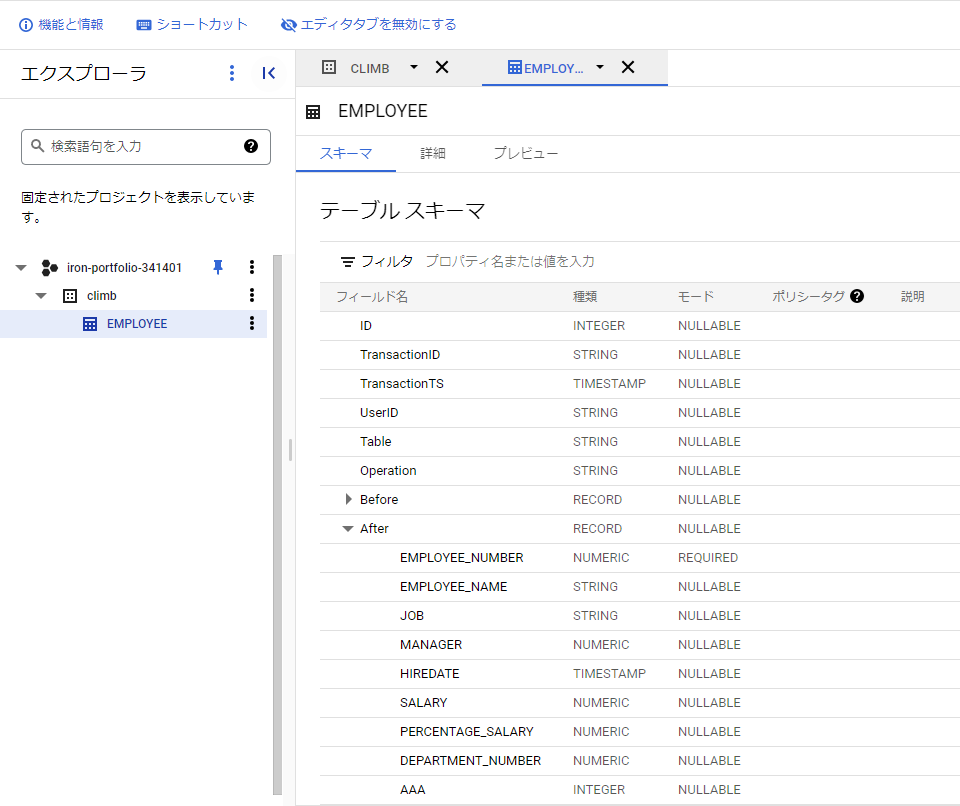
ここで、実際にGoogle BigQueryのテーブル構成を見てみましょう。
注意点としては、ソーステーブルと全く同じ構造のテーブルが作成されるのではなく、
Synitiのレプリケーションに必要なカラムがいくつか追加されていることがわかります。
実際に、ソーステーブルのレコードが格納されるのは、BeforeまたはAfter項目内となり、BeforeおよびAfterの左側にあるボタンを押すと、ソーステーブルと同じ構造が見えてきます。
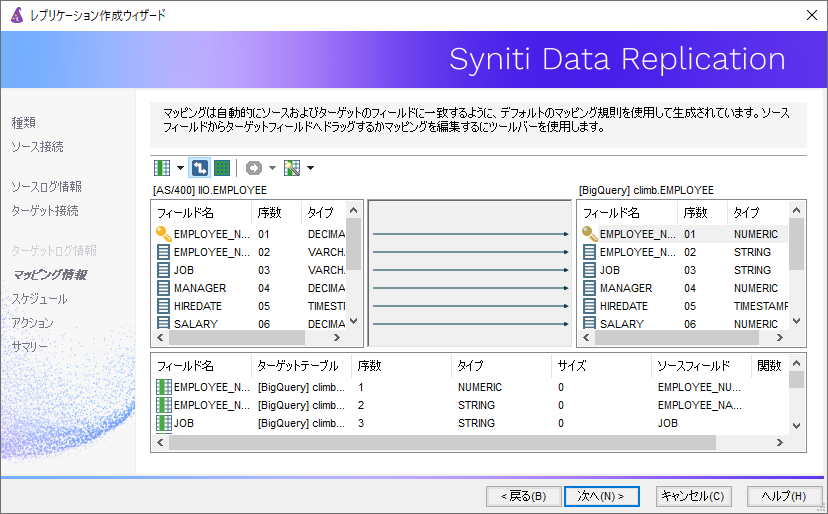
あとは、レプリケーションジョブ作成画面より、ターゲットテーブルにGoogle BigQueryのテーブルを選択することで、レプリケーションの準備は完了です。
Windowsのサービス一覧より、Syniti Data Replicatorサービスを起動することで、レプリケーションが開始されます。
レプリケーション後、実際にターゲットのGoogle BigQueryに作成したテーブルを見てみると、After項目内にソーステーブルの内容が記録されていることがわかります。
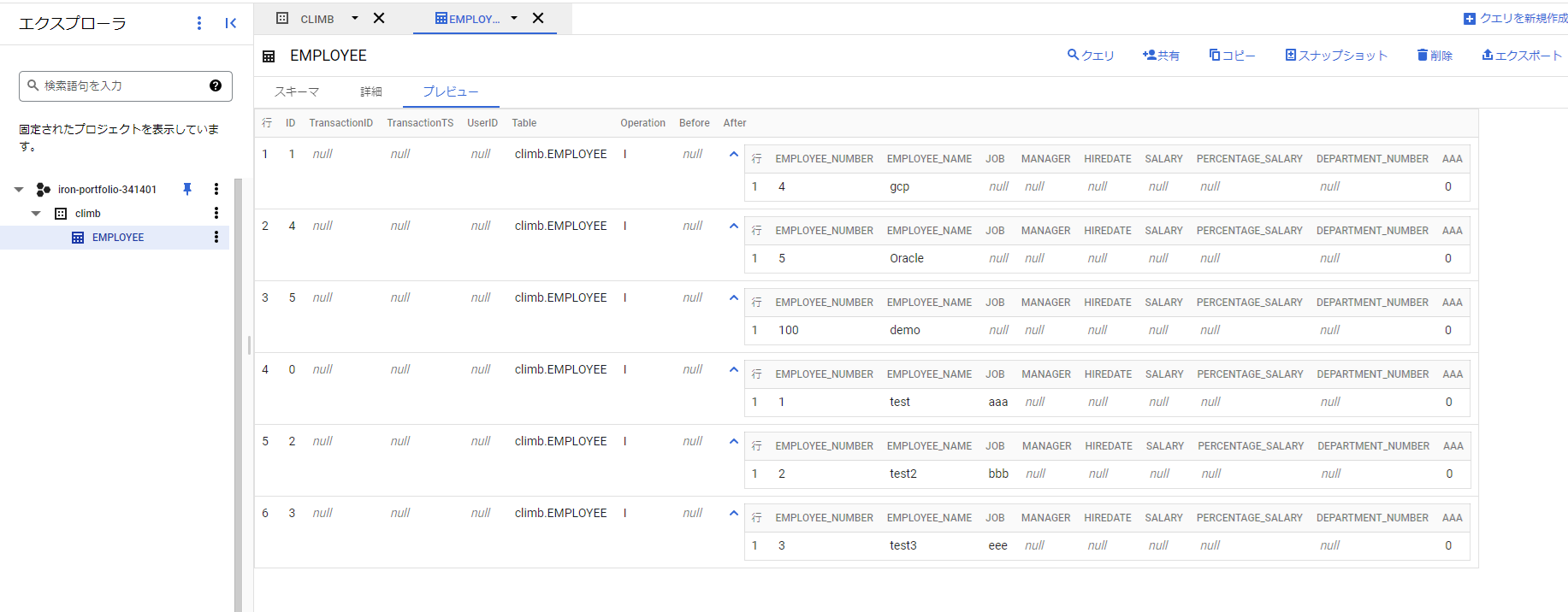
このように、Synitiを利用することで簡単にデータ分析基盤として有名なGoogle BigQueryに対して、様々なデータベースからデータをレプリケーションすることが可能です。
評価版もご用意しておりますので、こちらよりお問い合わせください。
関連したトピックス
- Google Cloud SQL と オン・プレミス・データベース間でのデータ・レプリケーション【DBMoto】
- DBMotoからSyniti Data Replicationへのアップグレード方法
- Syniti Data Replication (DBMoto) の監視方法について
- DBMoto[Syniti]の技術お問合せ時に必要な情報
- Syniti Data Replication 新機能ブログ② Amazon S3へのレプリケーション対応
- [DBMoto]API(C#, VB, C++)の開発環境構築手順 ~APIを使用してバッチからジョブを制御~
- [DBMoto/SynitiDR]Ritmoトレース取得手順(AS/400, z/OS, Linux, AIX, Windows向けDB2)
- Gluesync for Google BigQuery: Google BigQueryとのシームレスなデータ同期を実現する最速のソリューション
- Parquetで連携し、より効率的なデータ分析を簡単に実現【Gluesync】
- Google Pub/Sub ターゲットコネクタ:Gluesyncでデータストリーミング機能を強化

 RSSフィードを取得する
RSSフィードを取得する


