
「EspressReport Enterprise Server (ERES)」でのユーザがシステムを利用開始(データ接続)してから最終的なアウトプット(レポートの公開・配信)を得るまでの作業プロセスを可視化します。
続きを読む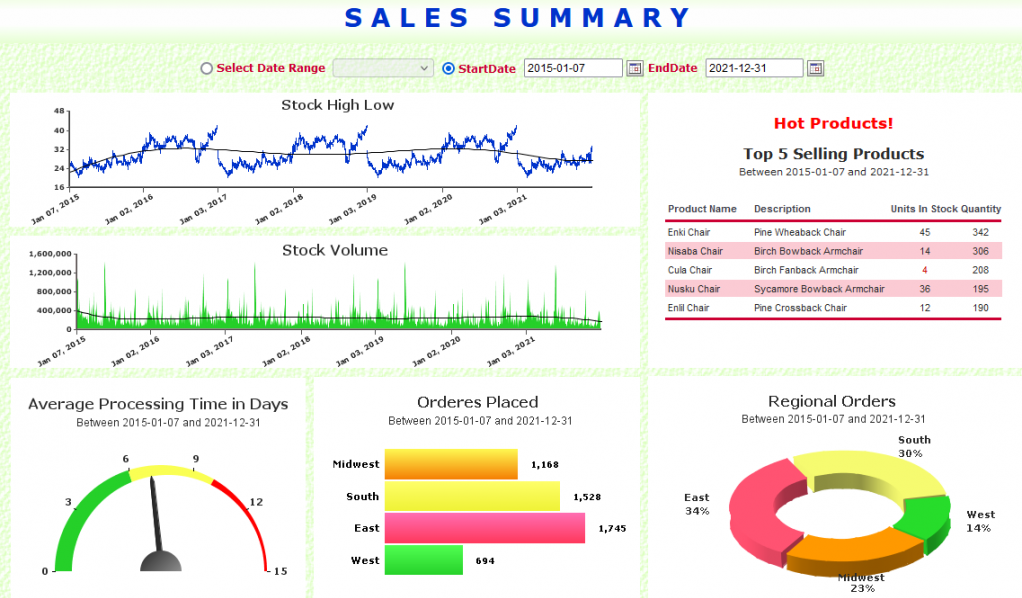


-
メールマガジン登録
- 海外の ”クラウド・コンピューティング”の最新技術などを中心に、注目のコラム、ウェブサイト、企業の公開情報等をご紹介します。
バックナンバー [climbクラウド・ナウ]
- 海外の ”クラウド・コンピューティング”の最新技術などを中心に、注目のコラム、ウェブサイト、企業の公開情報等をご紹介します。
製品・カテゴリで絞る
- EspressChart (150)
- EspressReport (74)
- EspressReport ES (74)
- EspressDashboard (58)
- Espressシリーズ共通項目 (93)
- 事例紹介 (15)
- 3rdパーティ情報等 (6)
- BI/Dashboard (33)
- プログラミング (11)
- リリースノート (23)
- Java (12)
-
新着情報
- EspressReport Enterprise Server (ERES)でのシステムを利用開始から最終的なアウトプットまでの作業プロセス
- Espressシリーズ Version 7.2 update 0 リリース:2026/5/7
- データウェアハウスについて
- ビッグデータに対応するEspressシリーズの分析・可視化したダッシュボードサンプル集
- KPIダッシュボードがビジネスに不可欠な理由
- Java EEからJakarta EEへ
- Excelデータを活用してEspressReport ESでレポートを作成・配信する方法
- KPIの謎解き:重要業績評価指標の選び方・活用法・成功への道
- ITダッシュボードを使用して効果的なKPI設定をするには
- データビジュアライゼーションおよびセルフサービスBIツール導入の成功のために
関連リンク
- EspressChart 動的なWebチャートを作成・配信するJavaツール
- EspressDashboard KPIプレゼンテーションとWeb配信のためのダッシュボードツール
- EspressReport 動的なWebレポートを作成・配信するJavaツール
- EspressReport ES (Enterprise Server) エンタープライズ対応の情報配信レポーティング・ツール
- Webセミナー録画集 過去にオンライン配信したWEBセミナーの録画一覧
- 【Espress】YouTubeサイト Javaグラフ・レポート・ダッシュボードツール動画集
- サイトマップ
- サンプル・ギャラリ(Quadbase)
- 総合FAQサイト
タグ・トップ50
KPI (16)API (9)Crystal Reports (8)Java Report (7)チャート作成 (5)JSON (4)Javaチャート (4)マップ(地図) (4)BigQuery (4)Jakarta EE (3)Java EE (3)主要業績評価指標 (3)業務効率化 (3)Javaグラフ (3)MySQL (2)Android (2)マーケティング (2)会計 (2)マネジメント (2)アプレット (2)Google Analytics (2)GA4 (2)データ公開 (1)ビジネスインテリジェンス (1)BIダッシュボード (1)HeatWave ML (1)Jason (1)Key Performance Indicator (1)HeatWave (1)アドホック クエリ (1)Adhoc query (1)プログラム (1)azure (1)営業 (1)経営 (1)Java11 (1)Applet (1)QuickDesiner (1)コロナ (1)Google Analytics 4 (1)アナリティクス (1)ga4分析 (1)SOQL (1)グーグルアナリティクス (1)Webチャート (1)Javaアプレット (1)Azure Synapse Analytics (1)IBM Cloud (1)OpenShift (1)アラーム (1)

 RSSフィードを取得する
RSSフィードを取得する

