
ビジネスの成長に伴い、データ量も増加することが予想され、場合によっては指数関数的に増えることもあります。そのため、このデータを整理し、理解することが不可欠となります。本記事では、データウェアハウスとは何か、その仕組み、それを支えるアーキテクチャモデルに加え、実務上のメリットや課題について考えてみました。
データウェアハウスとは?
データウェアハウスとは、企業が複数のソースからのデータを単一の整理されたリレーショナルデータベースに統合し、データに基づいた経営判断を下せるようにするシステムです。これは特にビジネスインテリジェンスにおいて有用であり、過去データと現在データの両方に迅速かつ構造化された形でアクセスできることが、意思決定プロセスにおいて決定的な違いをもたらします。
通常、データウェアハウスの構築は、以下の2つの最も一般的なアプローチから始まります。各アプローチにはそれぞれの強みがあり、ビジネスニーズ、利用可能なリソース、プロジェクトの範囲に基づいて選択されます。
ボトムアップ:特定の事業領域に合わせたデータマートを作成することから始め、それらをより大規模なデータウェアハウスに統合していきます。
トップダウン:まずデータウェアハウス全体の設計から始め、そこからより小規模で専門的なデータマートを開発していきます。
データウェアハウスの主要構成要素
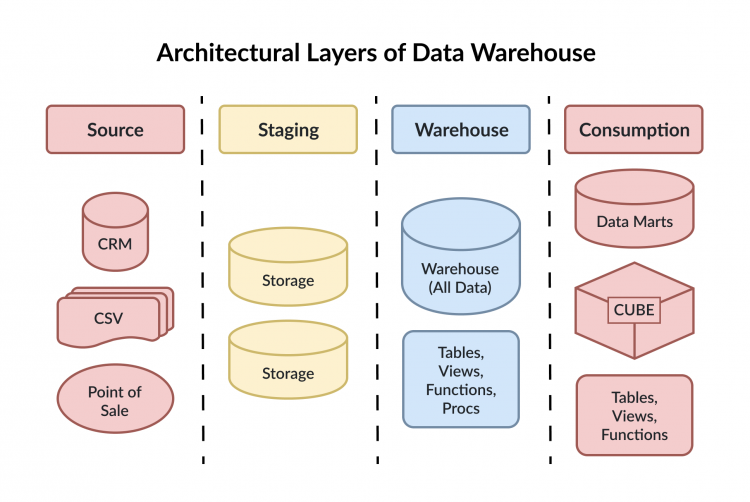
データウェアハウスは通常、4つの主要な層で構成されており、各層はデータ処理パイプラインにおいて特定の役割を果たします。
データソース層
ソース層は、すべての生データが起源となる、あるいは生成される基盤となる層です。ビジネスの特性に応じて、従来のシステムでは構造化データ(リレーショナルデータベースなど)、現代のシステムでは半構造化データ(JSONファイルなど)や非構造化データ(画像やセンサー出力など)となる場合があります。
データ・ステージング層
ステージング層は、ソースシステムから収集された生データの一時的な保存場所として機能します。この段階では、データはまだクリーニング、標準化、または検証されていません。この層は、生データとより高度な処理を行う層との間にバッファを提供し、データがパイプラインの次の段階へ進む前に、重複排除、フォーマット調整、エラー修正などの処理が行われるようにします。
データストレージ(ウェアハウス)層
これは、データが構造化され統合された形で永続的に保存される中心的な層です。ステージング層での処理後、データは長期利用のためにここで整理されます。この層は、データの一貫性、履歴性、および分析への準備状態を確保し、信頼性と安定性を提供します。
データ分析(プレゼンテーション)層
この最終層では、構造化されたデータがレポート作成や分析のためにユーザーに提供されます。多くの場合、ダッシュボード、レポート作成ツール、またはその他のユーザーインターフェースが含まれており、ビジネスユーザーは基盤となるストレージシステムを直接操作することなく、データの探索、可視化、解釈を行うことができます。
データウェアハウスアーキテクチャの種類
データウェアハウスアーキテクチャは複雑さが異なるため、組織の規模、目標、技術的な要件に応じて、実装方法が異なることがよくあります。以下に、最も一般的なアーキテクチャモデルを挙げます。
単層アーキテクチャ
複数の層が論理的、そして多くの場合物理的にも単一の層に統合されたシンプルなアーキテクチャです。このシンプルなアーキテクチャにより、データの冗長性を排除することができます。構築は容易ですが、このアーキテクチャは拡張が難しく、柔軟性に欠け、パフォーマンスのボトルネックが発生する可能性があります。
2層アーキテクチャ
2層アーキテクチャでは、データソース/データステージング層と、ウェアハウス/プレゼンテーション層が論理的および物理的に分離されています。このアーキテクチャは中小企業で広く採用されています。データおよびストレージ管理の面で優れていますが、拡張性や大量のデータ処理に関しては依然として制限があります。
3層アーキテクチャ
これは最も一般的で堅牢なアプローチです。データソース、ステージング、ストレージ、プレゼンテーションというすべての主要な層を物理的および論理的に分離します。これらのコンポーネントを分離することで、このアーキテクチャは優れたスケーラビリティ、柔軟性、およびパフォーマンスを実現します。
最新のデータウェアハウスアーキテクチャ
最新のデータウェアハウスアーキテクチャは、IT分野全般における最近のトレンドをすべて取り入れています。これには以下が含まれますが、これらに限定されるものではありません:典型的なアーキテクチャには、ソース層、ステージング層、ストレージ層、およびプレゼンテーション層が含まれます。構成によっては、一部の層が統合されたり、複数のシステムに分散されたりする場合があります。
- クラウドネイティブアーキテクチャ: オンプレミスの制約を取り除くことで、クラウドネイティブデータウェアハウスは容易なスケーリングとオンデマンドでの拡張を可能にします。つまり、「サーバーレス」アーキテクチャにより、実際に使用している分のみを支払うことができ、多額の初期費用を削減できます。さらに、クラウドネイティブアーキテクチャでは、通常AWS S3やAzure Blobなど比較的安価なストレージ上に存在するデータレイクに、すべてのデータを効率的に保存することが可能です。
- リアルタイム処理: 最新のデータウェアハウスアーキテクチャでは、継続的なデータ取り込みが可能であり、オンデマンドでの即時分析を実現します。
- AIおよびMLの統合: LLMモデルの進歩により、これらを統合することで分析をさらに加速させ、より適切なビジネス判断を下すことが可能になりました。
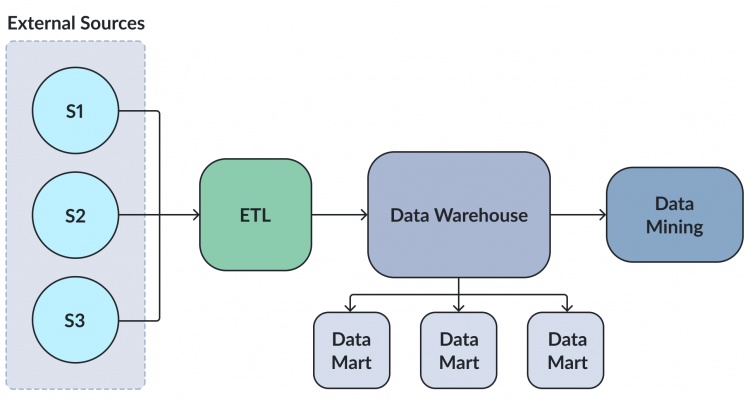
適切に設計されたデータウェアハウス・アーキテクチャのメリット
適切に構築されたデータウェアハウスは、情報に基づいた事実に即した意思決定を行う能力を変革し、強化する、ビジネスにとっての戦略的資産です。データウェアハウスが適切に設計されていれば、システム全体は以下のことが可能になります:
最新の分析機能との統合:最新のデータウェアハウスを導入することで、LLM(大規模言語モデル)を活用し、データ分析と意思決定の質を向上させることができます。
パフォーマンスの向上:高速なクエリ処理により、迅速かつ正確なレポート作成と分析が可能になります
データ品質の向上:データ品質が向上すれば、ビジネス運営に活用できるデータの質も向上します
拡張性:適切に設計されたデータウェアハウスは、ビジネスの成長に合わせて拡張が可能です
課題と留意点
データウェアハウスの導入は、どの組織にとっても重要な一歩であり、大きなメリットが期待できる一方で、それに伴う課題を認識しておくことが重要です。導入事例の多くに共通する課題もあれば、選択した具体的なアーキテクチャやアプローチによって異なる課題もあります。
ビジネス変化への適応: ビジネスが進化するにつれて、データ要件も変化します。合併、新製品ラインの立ち上げ、レポート要件の更新、ユーザー行動の変化など、あらゆる要因がウェアハウスの変更を必要とする可能性があります。
データ統合の複雑さ: システムが進化するにつれ、新しいデータ型やデータソースが導入される可能性があり、継続的な調整が必要となります。明確な統合戦略がなければ、データのサイロ化、不整合、エラーが発生し、下流のプロセスが複雑化する恐れがあります。
データ品質: データ品質の低下は、手動入力時のミス、部門間の定義の相違、あるいは旧式のシステムに起因する可能性があります。堅牢なデータウェアハウス設計では、データがシステムに入力される際のクリーニング、検証、および整合化を考慮に入れる必要があります。
拡張性とパフォーマンス: データウェアハウスの設計が不適切だと、パフォーマンスのボトルネックや、データ量の増加に伴う拡張性の問題が生じます。最適化が行われない場合、クエリ速度の低下、ストレージコストの増加、システムの応答性の低下を招く可能性があります。
ビジネスに最適なアーキテクチャを設計する方法
自社向けにデータウェアハウスを構築・設計しようとしている方に向けて、設計プロセスで考慮すべきポイントをいくつかご紹介します:
堅牢で自動化されたプロセスを設計する。 データを最新かつクリーンで利用可能な状態に保つためには、自動化され信頼性の高いETL(抽出、変換、ロード)またはELT(抽出、ロード、変換)パイプラインが不可欠です。
明確なビジネス目標を定義する。データウェアハウスが解決すべき具体的な課題を特定します。自社のデータと、それがビジネスインテリジェンスにどのような影響を与えるかを理解します。
データの監査を行う。データソース、フォーマット、データ量を把握します。
導入モデルを選択する ツールやプラットフォームを調査し、オンプレミス、完全なクラウド、あるいはハイブリッドアプローチのいずれを採用するかを決定します。
スケーラビリティを計画する。潜在的なボトルネックを特定し、それらを克服する方法を検討します。
人気的なクラウドデータウェアハウスソリューション
Azure Synapse Analytics – SQLとSparkを併用するチームに適しています。
Amazon Redshift – すでにAWSを利用しているチームに最適です。
Google BigQuery – 大規模な分析ワークロードに最適です。
Snowflake – 高いパフォーマンスとマルチクラウド対応で知られています。
Databricks – ML/AIワークロードや非構造化データの処理に最適です。
結論
現代のデータウェアハウスは、単なる情報の保管場所にとどまりません。それは、データ主導の時代において組織に力を与える、極めて重要な戦略的資産です。適切な技術と手法によって慎重に設計・運用されれば、データウェアハウスは組織全体に真の価値をもたらす強力なツールとなります。一方、適切な計画がなければ、単なる活用されないシステムの一つに終わってしまうリスクがあります。成功の鍵は、アーキテクチャをビジネス目標と整合させ、データ品質を維持し、最新かつ拡張性の高いソリューションを採用することにあります。

 RSSフィードを取得する
RSSフィードを取得する
