


ハードウェアは故障する。電源装置は焼損し、光ファイバーは切断され、ハードドライブは故障する。高可用性(HA)は、これらの物理的な障害からエンドユーザを保護します。
これは自動フェイルオーバーに焦点を当てたシステム設計です。障害発生時には、トラフィックが即座に健全なコンポーネントへ迂回し、インフラストラクチャの障害にもかかわらずビジネスプロセスを継続させます。停止と再起動を伴う災害復旧(DR)とは異なり、HAはアプリケーション層に対して障害を不可視化することを目指します。
目次
高可用性アーキテクチャ
高可用性(HA)には完全な依存関係チェーンが必要です。単一のファイアウォールの後ろに配置された冗長アプリケーションクラスターは無意味です。高可用性アーキテクチャは2つの核心概念に依存します:
●冗長性:システムの重要な部分にはすべて複数のコピーが存在します。これらのコピーは連携して動作するため、1つのコンポーネントが故障しても別のコンポーネントが既に利用可能です。これにより単一障害点を排除し、システムを中断なく稼働させ続けます。
●自動フェイルオーバー:システムは障害を検知し、健全なコンポーネントへ自動的に切り替えます。このプロセスにはITスタッフの手動操作が不要です。結果として復旧が迅速に行われ、ユーザーは障害発生に気付かない場合もあります。
人間がボタンを押す必要がある場合、それは高可用性ではありません。それは災害復旧(Disaster Recovery)です。
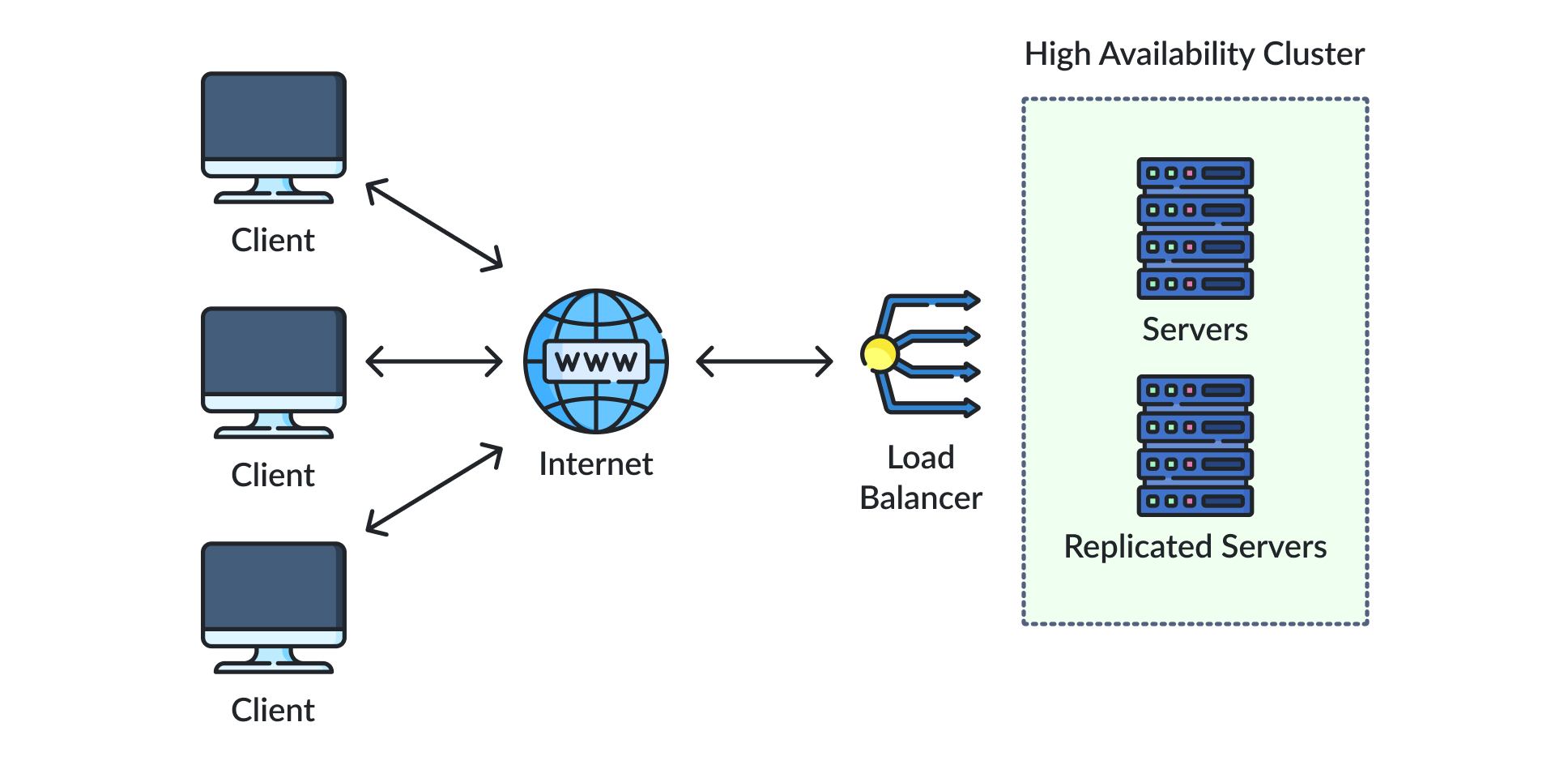
図1:シンプルなHA構成
冗長性の階層
ストレージのHAがなければ、コンピューティング・クラスタリングは効果を発揮しません。データが単一のSAN上に存在し、そのSANが故障した場合、コンピューティングクラスタは実行すべきものが何もなくなります。このため、共有ストレージまたは同期ミラーリング(StarWind Virtual SANやVMware vSANなど)が必須となります。同様に、ネットワークレベルではマルチパシングが必要です。単一のケーブルやスイッチの故障は、接続の切断ではなくパケットの損失に留まるべきです。
したがって、適切な冗長システム設計のためには、IT環境の複数レベルにわたり高可用性を実装しなければなりません:
コンピューティング層
このレベルでは、複数のサーバーをクラスタリングすることで高可用性を実現します。これらのサーバはワークロードを共有し、互いの健全性を監視します。1台のサーバが障害を起こした場合、ワークロードは自動的にクラスタ内の別のサーバーに移行され、アプリケーションの実行を継続させます。
ストレージ層
ここでは、ストレージノード間でデータを分散することで高可用性を実現します。これにより、1台のストレージデバイスまたはノードが故障してもデータへのアクセスが維持されます。アプリケーションはデータの可用性に依存するため、ストレージの高可用性は全体的なアーキテクチャにおいて重要な要素です。
ネットワーク層
ネットワーク層では、複数のネットワークパスを使用することで高可用性を実現します。これは冗長化されたスイッチ、ファイアウォール、ルーター、およびネットワークリンクによって行われます。あるネットワークパスが障害を起こした場合、トラフィックは自動的に別のパスにリダイレクトされ、接続の問題を防止します。
「9(ナイン)」のコスト。稼働時間対予算
可用性は「9(ナイン)」で測定され、1年間におけるシステムの稼働率(%)を表します。経営陣はしばしば「ファイブナイン」(99.999%)を要求しながら、それを達成するために必要な予算を実際に承認しません。
以下の数値は、可用性パーセンテージが1年間の実際のダウンタイムにどのように変換されるかを示しています:
「9(ナイン)」対ダウンタイム:
- 99%(ツーナイン): 年間約3.6日のダウンタイム。重要度の低いバッチ処理には許容範囲。
- 99.9%(スリーナインズ): 年間約8.7時間のダウンタイム。大半の中小企業インフラの標準。
- 99.99%(フォーナインズ): 年間約52分のダウンタイム。中堅企業やエンタープライズ生産環境に必須。
- 99.999%(ファイブナインズ): 年間約5分のダウンタイム。銀行、医療、通信業界に必須。
厳しい現実として、99.9%から99.99%への移行にはコストが指数関数的に増加することが多く、単純な冗長化(アクティブ/パッシブ)から「本格的な」アクティブ/アクティブクラスタや地理的に分散したサイトへの移行が必要となる。99.99%から99.999%への移行にも同様の原則が適用される——こうした環境には綿密な計画、多額の投資、そして全インフラ層における完全なフォールトトレランスが求められる。
「複雑性のパラドックス」
システム設計におけるよくある見落としは、複雑性による負荷を無視することです。自動負荷分散を備えた複数サイトにまたがる分散クラスタのような複雑な高可用性(HA)システムは、新たな障害モードをもたらします。
フェイルオーバー制御ロジックが誤動作すると、ハードウェアに問題がない場合でもサービス停止を引き起こす可能性があります。これはノード間の通信が断絶し、両ノードが同一データの所有権を主張することでデータ破損を招く「スプリットブレイン」シナリオで頻繁に発生します。
これを防止するため、堅牢なHAでは通常、ネットワーク分割時に審判役として機能する「監視者」またはクォーラム機構が必要となる。
StarWind Virtual SANのようなソリューションは、複数のハートビート戦略を提供することでこの複雑性を解決します。特定の保護策(別々の物理リンク経由のハートビートなど)を用いた「監視者不要」の2ノード構成で動作可能であり、あるいは追加の軽量クラスタインスタンスや単純なファイル共有を用いた従来の監視者実装を許可し、接続を仲裁します。これにより安全なクォーラムを維持するために必要なインフラストラクチャのフットプリントが大幅に削減されます。
HAは災害復旧ではない(バックアップでもない)
高可用性(HA)の冗長化をあらゆるレベルで実装しても、機能する(かつテスト済みの)バックアップ戦略は依然として必須です。これは、HAがインフラストラクチャ障害からの保護のみを提供し、ソフトウェアの破損、人的ミス、サイバー攻撃からの保護を保証しないためです。
HAはバックアップの代わりにはなりません。
- HAはインフラ障害から保護します。RAIDアレイやサーバーの1台が故障しても、HAはデータ(仮想マシンやコンテナ)を稼働状態に維持します。
- バックアップはデータ破損から保護します。重要なデータベーステーブルを削除した場合、HAシステムはその削除を即座にミラーに複製します。結果として、高可用性ながら破損したデータが存在する状態になります。
同様に、HAは災害復旧(DR)とも異なります。HAは単一拠点内のスイッチ故障やサーバ再起動といった日常的な問題に対処します。DRは洪水や長期停電といったサイト全体の災害に対する保険です。HAは自動的かつ即時(RTO≈0)に動作しますが、DRは手動で時間がかかる場合が多く(RTO>1時間)です。
実使用例
以下は高可用性(HA)インフラの代表的な活用事例です:
医療(EHR & PACS)
病院は電子健康記録(EHR)と画像アーカイブ通信システム(PACS)に依存しています。ストレージバックエンドの障害は患者履歴や画像へのアクセスを遮断し、安全性を脅かします。HAはホスト障害時にも臨床アプリケーションを稼働させ続け、スタッフがITトラブルシューティングではなく治療に集中できるようにします。
製造業(SCADA & IIoT)
工場では組立ライン管理に監視制御・データ収集システム(SCADA)を使用します。サーバーのクラッシュは生産を停止させ、ライン上の材料(例:化学処理)を廃棄せざるを得ない状況を生じさせます。HAクラスタは、粉塵の多い環境や高振動環境などにおいて、制御ソフトウェアがハードウェアの不具合を生き延びることを保証することで、この「バッチ廃棄」を防ぎます。
海事・海洋(切断されたエッジ環境)
船舶や石油掘削装置は接続環境が限られており、クラウドフェイルオーバーは不可能です。航海中にナビゲーションシステムが故障した場合、乗組員はバックアップをダウンロードできません。堅牢な2ノードクラスターは自己修復機能を提供し、船舶が港に到着するまで無期限に運用を維持します。
小売・ROBO(分散サイト)
小売チェーンは遠隔オフィス/支店(ROBO)拠点で「マイクロクラスター」を運用。現地のPOSサーバーが故障すると店舗は決済処理不能に。自動化された2ノードHAクラスターは即時自己修復を可能にし、緊急のIT現場対応を要せずレジレーンを維持します。
金融サービス(トランザクションの完全性)
銀行にとって稼働時間の確保は規制順守を意味します。データベース障害は業務を停止させ、失敗したトランザクションのバックログを生じさせ、高コストな手動調整を必要とします。規制違反罰金のコストは、HAインフラへの投資額をしばしば上回ります。
教育(VDI & LMS)
学校は仮想デスクトップインフラ(VDI)と学習管理システム(LMS)に依存しています。試験中のクラスター障害は数千人の学生に影響します。HAはアクティブセッションを保護し、物理ホスト障害による学生の切断や試験データの損失を防ぎます。
映像監視(VMS)
スタンドアロンのネットワークビデオレコーダー(NVR)は、映像管理ソフトウェア(VMS)にとって単一障害点となります。HAストレージは汎用サーバー間で録画データをミラーリングし、専用エンタープライズハードウェアのコストをかけずに継続的な監視を保証します。
結局のところ、アーキテクチャを理解することは戦いの半分に過ぎません。真の課題は実装にあります。従来、「HAレベル」の耐障害性を実現するには高価な専用SANアレイが必要でした。しかし現代のアプローチでは、耐障害性をハードウェア層からソフトウェア層へ移行させることで、標準的な汎用サーバー上で高可用性を構築することが可能となっています。
中堅中小企業および遠隔オフィス向けStarWindソリューション
StarWind Virtual SAN (VSAN) – エッジおよび中小企業環境向けに、StarWind VSANは高価な物理SANの必要性を排除します。2台のサーバー間でデータを同期的にミラーリングし、単一の共有ストレージプールとして提供します。重要な点として、2ノード構成における「スプリットブレイン」シナリオを効果的に処理し、1つのノードがダウンした場合でも、データ破損なくもう一方のノードが透過的に引き継ぐことを保証します。
結論
高可用性は、冗長化のコストとダウンタイムのコストのバランスを取ります。StarWindのような現代的なツールは、専用ハードウェアの必要性を排除することで実装を簡素化しますが、その原則は厳格です:単一障害点を排除し、復旧を自動化し、クラスタとバックアップを混同してはなりません。
関連トピックス:
- None Found
 RSSフィードを取得する
RSSフィードを取得する






