クラウドの拡張性、適応性、費用対効果を活用するために、多くの組織がアプリケーションをクラウドに移行していることは紛れもない事実です。そのため、デジタル資産の中断のない可用性と保護を確保するために、堅牢なクロスクラウド・ディザスタリカバリ(DR)システムを確立することが極めて重要です。
続きを読む

クラウドの拡張性、適応性、費用対効果を活用するために、多くの組織がアプリケーションをクラウドに移行していることは紛れもない事実です。そのため、デジタル資産の中断のない可用性と保護を確保するために、堅牢なクロスクラウド・ディザスタリカバリ(DR)システムを確立することが極めて重要です。
続きを読むパブリック クラウド、プライベート クラウド、オンプレミス リソースを組み合わせた構成のクラウド コンピューティング アーキテクチャを、ハイブリッド クラウド アーキテクチャと呼びます。ハイブリッド クラウドでは、データとアプリケーションを異なるタイプのリソースから共有できるようにすることで、個々のデプロイメントの特長を活かしたアーキテクチャの最適化が可能になります。
続きを読む日本では、DXと言えばクラウド、というイメージが定着している感があります。「クラウド」と名のつくものを導入すればデジタル化が達成されるかのような印象を持たせるテレビコマーシャルもよく見かけます。そのようなITサービスの広告が、いったい何をもって「クラウド」と言っているのか、あらためてCM動画などを検索して見直してみると、どうやら「インターネット」のことなのではないかという気がしてきました。
続きを読む
エンタープライズ・ハイブリッド・クラウド環境は、ITインフラを確立するための業界標準となっています。エンタープライズ・ハイブリッド・クラウドは、パブリック・クラウドとプライベート・クラウドの両方を組み合わせることで、最終的に企業のITリソースの管理を簡素化できるため、ますます人気が高まっています。
続きを読む急速に変化するデジタルの世界では、ビジネスを円滑に運営し、必要不可欠なアプリやサービスを滞りなく稼働させるために、ストレージ・ソリューションが欠かせません。ストレージの領域で著名なプレーヤは、従来型ストレージ・エリア・ネットワーク(SAN)と、それに対応する仮想SAN(Virtual SAN: VSAN)の2つのです。これらのソリューションはデータの保存、管理、アクセスのバックボーンとして機能するが、そのアプローチと機能は異なります。ここでは、仮想SANと従来型SANシステムのニュアンス、主な特徴、比較分析について掘り下げ、ストレージ・インフラについて十分な情報に基づいた決定を下すのに役立つことを期待します。
続きを読む今日のデジタル環境において、企業は重要なデータを保護し、ビジネスの継続性を確保するために、クラウドベースのサービスに大きく依存しています。Microsoft Azure Active Directory(Azure AD)は、Microsoftクラウド・サービスのIDおよびアクセス管理プラットフォームとして重要な役割を果たしています。このブログでは、組織のデジタル・アイデンティティを保護するために、Azure ADのバックアップがいかに重要である理由を探ります。
続きを読む
データ保護に関連するイミュータブル(不変)・データ保管庫(IDV:immutable data vaults )のコンセプトを考えるとき、最初に思い浮かぶのは「データは安全でセキュアなのか」ということです。通常、データは安全かつセキュアなのだろうか?私たちは安全でセキュアなデータのコピーを持つことがいかに重要であるかを知っています。しかし、一般的に後回しにされがちなのは、イミュータブルデータをどのように復元するか、そして復元にかかる労力と時間です。安全なデータ保管と信頼性の高い高速リカバリの両方を保証する保管庫ソリューションは、最良の選択肢です。
続きを読む.jpg)
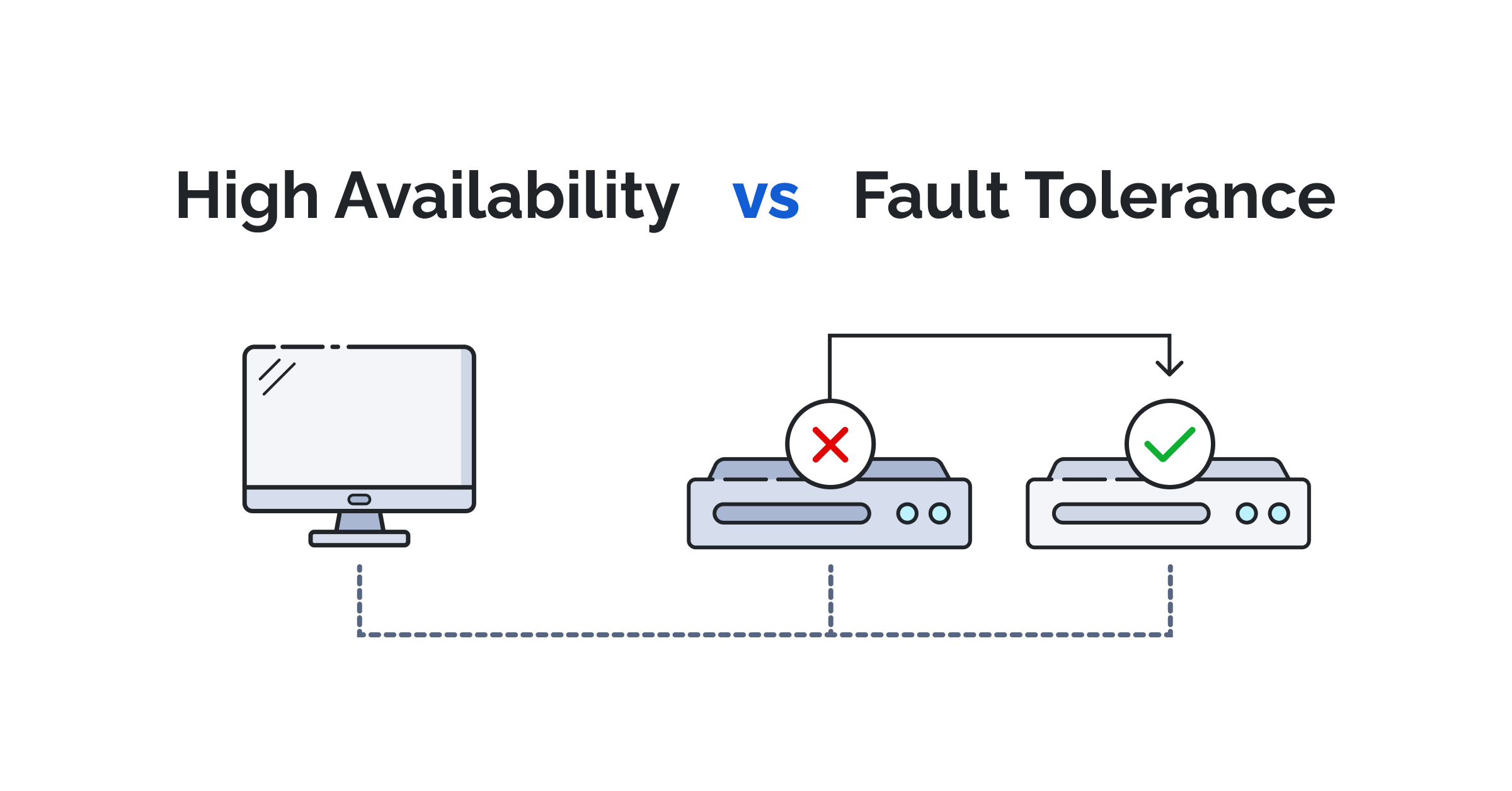
IT運用を常にオンラインに保つという困難な状況において、高可用性(ディザスタ・リカバリ: HA:High Availability)とディザスタリカバリ(DR:Disaster Recovery)という対照的な方法論を理解することは最も重要です。ここでは、アプリケーション回復力のダイナミック・デュオである HA と DR について検証していきます。高可用性とは何か、その利点と欠点、そして高可用性とDRの両方を採用すべき理由について説明します。
続きを読む 
RAID 5は、ディスクのストライピングとパリティの両方を使用するハードディスクドライブのデータバックアップ技術です。RAIDのレベルの1つ: RAIDとは、Redundant Array of Independent Disksの略で、元々はInexpensive Disksの略です。RAIDは1980年代に開発され、複数のバージョンがありますが、RAID 5はその一つに過ぎませ。IBMは1980年代からRAID 5の特許を持っています。
続きを読むハイブリッド・クラウド・インフラは、オンプレミスのITコンピューティングとクラウドベースのリソースを組み合わせたもので、企業がITの目標を達成し、ビジネス・ワークフローを促進するのに大いに役立ちます。プライベート・クラウドとパブリック・クラウドの両方の利点を組み合わせることで、ハイブリッド・クラウドは両方の長所を提供します。
続きを読む仮想化にはさまざまな種類があり、それぞれに利点と目的があります。ここでは、最も一般的な仮想化の種類をいくつか紹介します:
サーバ仮想化:サーバの仮想化により、ユーザは物理サービスをより小さな仮想サーバに分割し、サーバのリソースを最大限に活用することができます。これにより、ユーザはサーバ・リソースの複雑な詳細を管理する必要がなくなり、リソースの共有、利用、スケーラビリティが向上します。各仮想サーバは、物理マシン上の他の仮想サーバとは独立して、独自のオペレーティング・システムとアプリケーションを実行します。VMwareのvSphere、マイクロソフトのHyper-Vがこれに含まれます。
続きを読むMicrosoft 365 SharePoint、OneDrive、Teams、グループは異なるコンソールで管理され、しばしば異なる管理者、場合によってはパワーユーザによってさえ管理されることもあります。 これらの権限とレポートに対する一元的な可視性がなければ、企業はガバナンスの問題を抱えたまま、企業データを誤った社内外のチームに公開してしまうかもしれません。適切なガバナンスの必要性には、レビュー、監査、修復ができることが不可欠です。ここでは、これらの課題をレビューし、是正する方法を考えてみます。
続きを読む
デジタル時代において、データは世界中の企業にとって最も価値のある資産の1つとなっています。Amazon Web Services (AWS)やMicrosoft Azureなどのクラウドプラットフォームへの移行が進む中、これらのプラットフォーム上のデータバックアップのセキュリティはかつてないほど重要になっています。しかし、バックアップ管理者はこれらの貴重な「データ貯蔵庫」を保護するために十分なことをしているかどうかです!?
続きを読む RSSフィードを取得する
RSSフィードを取得する