

多くの組織は、自らがデータ駆動型であると信じています。しかし実際には、多くの組織が実際のデータのごく一部、具体的にはテーブルに収まる「整理された」データの一部だけで運営されています。ガートナーによる「企業データの80~90%は非構造化データである」という統計は、ここ数年話題になっていますが、今でもおおむね正確です。メール、契約書、PDF、チャットの履歴――これらはいずれもSQLデータベースには収まりません。
変化したのはその比率ではありません。LLM(大規模言語モデル)とRAG(リソースアシストドジェネレーション)パイプラインによって、ようやくこのデータを活用できるようになったということです。つまり、多くのチームがこれまで行ってきたように、このデータを無視し続けることはできなくなったのです。ダッシュボードやレポート作成のパイプラインは、依然として残りの10~20%のデータに基づいて構築されています。
構造化データ、非構造化データ、半構造化データが実際に何を指すのか、各データタイプでチームがどこで行き詰まるのか、そしてデータの活用目的に合わせてストレージをどう選択すべきか、詳しく見ていきましょう。
構造化データとは?
構造化データとは、固定されたスキーマ(あらかじめ定義されたフィールド、行、列)で保存された情報のことで、通常はリレーショナルデータベースやトランザクション型ビジネスシステム内に格納されています。ERP、CRM、財務記録、ホテル予約システム、製品カタログなどを考えてみてください。これらはすべて構造化データで動作しています。
チームが構造化データを好む主な理由は、その一貫性です。すべてのレコードが同じ形式であるため、最小限の前処理で検証、フィルタリング、結合、レポート作成を行うことができます。そのため、ほとんどのダッシュボードや分析ワークフローの背後には構造化データが存在しています。誰かが「第3四半期の売上高はいくらだったか?」と尋ねたとき、その答えは構造化データから得られます。
このレイヤーの形態は業界によって異なりますが、根底にあるロジックは同じです。小売業界では、SKU、取引金額、店舗IDといったデータが、「何が、どこで、いつ売れたか」という問いを瞬時に解決します。製造業では、シフトごとの生産量、機械の稼働率、不良品数といったデータがOEEダッシュボードに情報を提供します。物流業界では、出荷ID、運送業者コード、配送チェックポイントといったデータが、リアルタイム追跡を可能にします。
その限界は、その硬直性にあります。構造化データは、スキーマが安定しており、最も価値のある情報が個別の予測可能なフィールドとして提供される場合に効果を発揮します。単に「何が起きたか」だけでなく、「なぜ起きたのか」を理解する必要が生じた瞬間、リレーショナルテーブルの限界が露呈し始めます。チームが犯しがちな過ちの一つは、構造化データだけを「真の」データとして扱うことです。構造化データは扱いが最も容易であるため、選択バイアスが生じます。つまり、チームはクエリ可能なデータを中心にワークフローを構築し、それ以外の要素を黙って無視してしまうのです。
非構造化データとは何か?
非構造化データは、あらかじめ定義されたスキーマに従いません。テキスト、画像、音声、動画、またはドキュメントとして届き、誰かが処理に労力を費やすまで、その元の形式のまま残ります。メール、PDF、スキャンした契約書、プレゼンテーション資料、サポートの会話記録、通話録音、チャットの履歴。これらは、組織が実際に生成するデータの大部分を占めています。
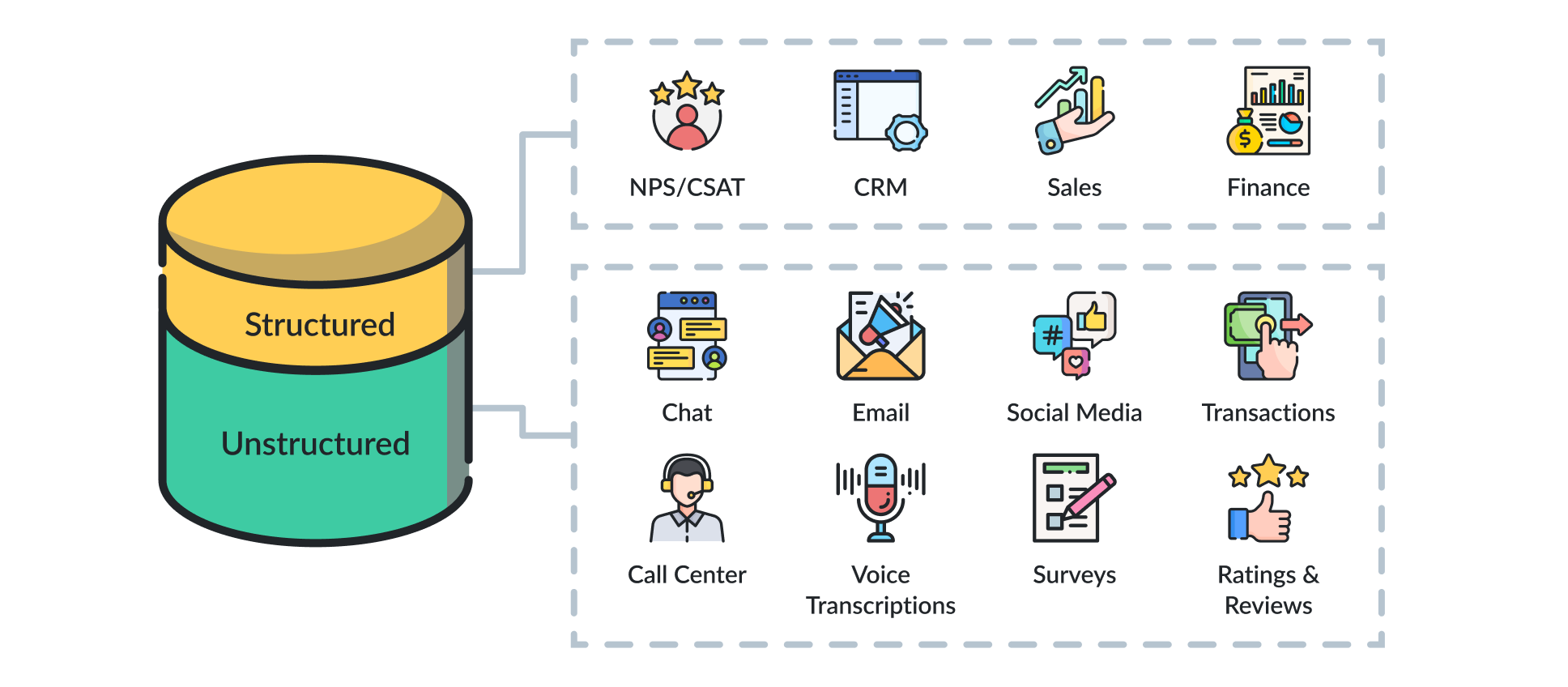
図1:構造化データ形式と非構造化データ形式の違いを示す視覚的な比較
これを大規模に扱うのは実に困難です。クエリを実行するのも難しく、ガバナンスを確立するのはさらに困難です。メールのやり取り、サポートチャット、通話記録には、実際に何が問題だったのか、なぜ顧客が離れてしまったのかが記されています。構造化データは「何かが変化した」ことを示し、非構造化データは「それが何を意味していたのか」を教えてくれます。
こうしたデータは、何かが故障したり監査が入ったりするまでは、つい無視されがちなものです。医療分野では、医師の診療記録、放射線画像、退院要約など、数字に臨床的な意味を与える「物語」の層にあたります。金融サービスでは、コンプライアンス審査の基盤となる監査報告書、規制当局への提出書類、顧客とのやり取りです。人事分野では、フィールドにきれいに収まらない履歴書、業績評価の記述、面接メモなどが該当します。
その難しさは紛れもない事実です。非構造化データはクエリが難しく、ガバナンスがさらに難しく、大規模な環境でのセキュリティ確保はさらに困難です。これは「ダークデータ」と直接結びついています。Splunkによると、企業データの約55%は「ダーク」な状態であり、収集・保存されているものの、決して利用されることはありません。問題は、非構造化データの扱いが難しいということだけではありません。チームが自らが何を持っているのかさえ、往々にして把握していないという点にあります。
半構造化データ:現代のシステムを動かし続けるフォーマット
半構造化データは、この2つの間にあるものです。リレーショナルテーブルには収まりませんが、生のドキュメントやメディアでもありません。固定されたスキーマによって形状が強制されていなくても、タグ、キー、メタデータ、または階層構造を持ち、機械が読み取れるようになっています。JSON、XML、APIレスポンス、イベントログ、クリックストリームデータ、IoTメッセージ、テレメトリストリーム、そしてAvro、Parquet、ORCのようなカラム型フォーマットは、すべてこのカテゴリーに分類されます。
その柔軟性こそが、これほど広く普及している理由です。半構造化データは、事前に厳格な構造を定義する必要なく、サービス、API、ワークフローの間を自由に移動できます。だからこそ、クラウドネイティブツール、イベント駆動型システム、オブザーバビリティスタックはすべて、半構造化データを大量に生成します。
エンジニアリングチームは、それを資産として意識することさえなく、絶えず生成しています。Eコマースでは、クリックストリームイベントや進化し続ける商品カタログのペイロードです。エネルギーや製造業のような業界では、IoTセンサーのログであり、その規模と変動性が大きすぎて、リレーショナルデータベースでは処理できません。SaaSやゲーム業界では、分析や実験のためのユーザーやプレイヤーの行動イベントが該当します。
根深い問題はスキーマドリフトです。強制的な構造がないため、上流の誰かがフィールド名を変更したり、ネストされたオブジェクトの順序を入れ替えたり、データ型を変更したりすることがあり、多くの場合、事前の警告はありません。下流のシステム(dbtモデル、Sparkジョブ、ML特徴量パイプライン)は、何の前触れもなく失敗する可能性があります。ベンダーがJSONペイロードを微調整し、取り込みパイプラインが適切に検証を行わなかった場合、問題は静かに進行します。気づく頃には、数週間分のデータが破損したり失われたりしている可能性があります。このようなデータを扱うチームは、(時には痛い教训を経て)スキーマレジストリやスキーマオンリード戦略(AvroやProtobufなどのツールを使用)を「あれば便利なもの」ではなく、「必須のもの」として扱うことを学びます。
 RSSフィードを取得する
RSSフィードを取得する






