

2026年、ハイブリッド環境全体でデータ量は増え続けており、ランサムウェアや厳格な復旧目標がバックアップ戦略にプレッシャーをかけています。システムの可用性を維持する責任を負っている場合、従来のバックアップだけでは、もはや復旧に関する期待に応えられない可能性があります。継続的データ保護(Continuous data protection :CDP)は、データの変化を継続的に捕捉することで、ほぼ任意の時点からの復旧を可能にし、データの損失や破損から保護するという、より高度なアプローチを提供します。
ここでは、継続的データ保護の概念と、それがお客様の環境にもたらすメリットについて解説します。また、その仕組みや、従来のバックアップとの違いについても見ていきます。
CDPが実際に記録するもの
継続的データ保護(CDP)は、継続的バックアップとも呼ばれ、データに加えられたあらゆる変更を継続的に記録・保存し、事実上、継続的なバックアップ機能を提供するバックアップ技術です。CDPは、すべてのデータ変更をリアルタイムで記録するため、データ損失をほとんど、あるいは全く生じさせることなくシステムを復元することが可能です。
本質的に、CDPとは、ストレージへの書き込みのすべてを、発生した瞬間のタイムスタンプ付きで記録したジャーナルです。このジャーナルは、多くの場合、プライマリデータとは別の場所(別のディスク、ノード、あるいはサイト)に保存され、保存ポリシーに従ってトリムされます。復旧が必要な場合は、ベースイメージ(以前の時点の完全なコピー)を指定し、ジャーナルを再生またはロールバックして、任意の時点の状態に戻します。
これが教科書的な定義です。実際には、「CDP」と呼ばれるものには2つの種類があり、その区別は非常に重要です:
ツルー(True) CDP
すべての書き込みは、ブロックレベルの変更として、あるいはI/Oフィルタドライバ層で、リアルタイムに捕捉され、ログに記録されます。復旧の粒度は実質的に1回の書き込みであり、データベースの用語で言えば1つのトランザクションに相当します。Zerto、Veeam CDP for VMware、Dell RecoverPointはこれに該当します。
ニアーCDP
すべての書き込みを逐一捕捉する代わりに、システムは頻繁に(通常は数分おきに)スナップショットを取得し、そのスナップショットの連鎖を復旧タイムラインとして扱います。任意の瞬間に復元することはできませんが、最も近いスナップショット時点への復元は可能です。ほとんどのストレージアレイ、ZFS、およびVMwareのスナップショットベースのバックアップは、この方式で動作します。操作性はツルーCDPと似ていますが、ストレージ容量やオーバーヘッドの計算は大きく異なります。
よく聞かれる質問への回答として:いいえ、CDPはスナップショットと同じではありませんが、スナップショットベースの製品は、しばしば「CDP」として販売されています。スナップショットは、定期的かつクラッシュ一貫性のある特定の時点の状態です。ツルーCDPは連続的なデータストリームを提供するため、リカバリポイントは、対象とする最後の書き込みのタイミングと同じくらい正確になります。スナップショットの間隔がRPOの目標を満たすのであれば、CDPに近い方式の方がシンプルで安価です。満たさない場合は、ツルーCDPが必要です。
内部の仕組み
ツルーCDPには、書き込みをインターセプトする方法、ジャーナルを格納する場所、そして確定的に復旧するための十分なメタデータの3つが必要です。インターセプタが興味深い部分です。これはいくつかの場所に配置できます:
ストレージアレイ内(DataCore SANsymphony、SANベースのスプリッターを備えたDell RecoverPointなど)。アレイはすべてのI/Oを監視しているため、ジャーナルへの分岐処理は低コストで、ホストからは透過的に行われます。
ハイパーバイザー内(VMware向けVeeam CDPはVAIOフィルタードライバーを使用、ZertoはホストごとにVirtual Replication Applianceをインストール)。すべてのVM書き込みは、ゲストへの確認応答(ACK)が返される前にジャーナルにミラーリングされます。
ホストOS内(旧式のEMC RecoverPointホストや一部のデータベース専用レプリケーターを含む、様々なホストベースのエージェント)。カーネルドライバまたはフィルタとして動作し、物理サーバーや、アレイがブラックボックスである場合に有用です。
ジャーナル自体は、タイムスタンプをキーとする差分ログに過ぎず、通常は元のホスト、ボリューム、オフセットに関するメタデータが含まれます。保持期間はスライディングウィンドウ方式です。変更がウィンドウの外に出ると、破棄されるか、ベースイメージに統合されます。実際の導入環境のほとんどでは、ウィンドウは数時間から数日です。これは「開発者が昨日そのクエリを実行した」というケースはカバーできますが、「開発者が先月そのクエリを実行した」というケースまではカバーできません。
リカバリは逆の操作です。タイムスタンプを指定すると、システムはベースイメージ上にジャーナルエントリを適用する(フォワードリプレイ)か、現在の状態からエントリを元に戻す(リバースリプレイ)ことで、ボリュームの状態を再構築します。データベースのワークロードでは、これはアプリケーション独自のクラッシュ一貫性保証と組み合わされます。つまり、2つのコミットの間にあるタイムスタンプまでボリュームを復元し、その後、データベースの回復ロジックに自身のredo/undoログを再実行またはロールバックさせて、トランザクション一貫性のある状態に戻します。
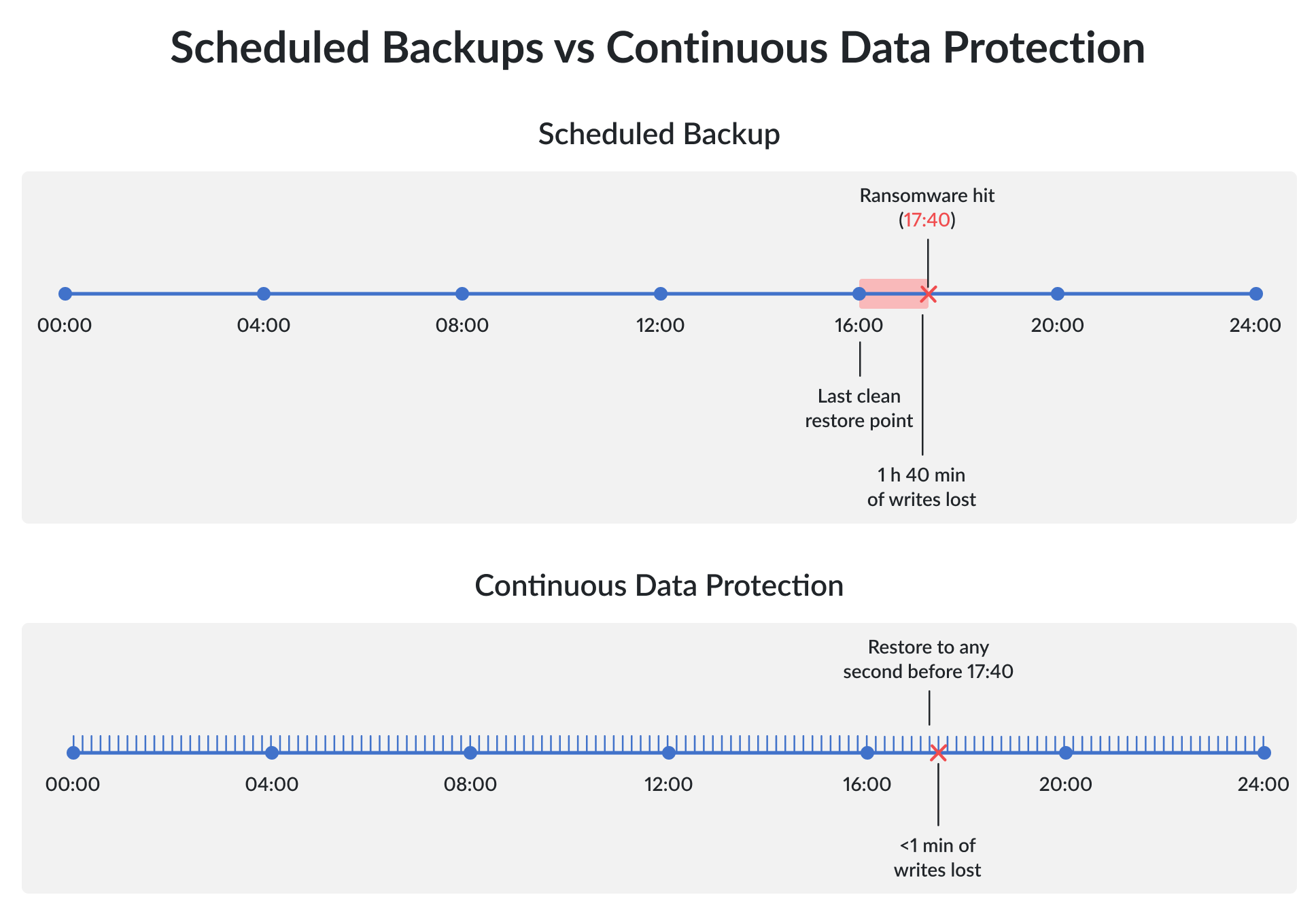
図1. 定期的なバックアップでは、最後の正常な復元ポイントとインシデント発生時点との間のデータ損失は回復不可能です。ツルーCDP(継続的データ保護)は、継続的なジャーナル処理のオーバーヘッドを代償として、そのギャップを実質的にゼロにまで縮小します。
CDP 対 従来のスケジュール型バックアップ
従来のバックアップとCDPは、同じ課題を異なるアプローチで解決します。スケジュール型バックアップでは、予測可能なストレージコストで、比較的少数の復元ポイントを提供します。一方、CDPは、設定された保持期間内であれば事実上無制限の復元ポイントを提供しますが、その代償としてデータパスへの負荷がはるかに高くなります。
この2つは互いに代替となるものではありません。多くの本番環境では、RPOの目標が厳しい最優先のワークロードに対してCDPを実行し、その下位層では、データ保持、長期的な復元ポイント、およびCDPでは対応できない種類の障害(後述)に対処するために、スケジュールされたバックアップを実行しています。
CDP 対 同期レプリケーション
この2つは、どちらも継続的なデータ転送を伴うため、常に混同されがちです。しかし、これらは異なる問題を解決するものです。
同期レプリケーションは、2つ以上のサイトに同時にデータを書き込み、すべてのコピーが確認するまで書き込みを承認しません。ノードがダウンしても、もう一方のコピーはすでに存在しているため、RPOはゼロとなり、RTOはフェイルオーバー機構がトラフィックを稼働中の側へ切り替えるのにかかる時間(通常は数秒)となります。同期レプリケーションでは、論理的な破損からデータを保護することはできません。不正なクエリ、誤ったデプロイ、あるいはランサムウェアによってプライマリにゴミデータが書き込まれた場合、セカンダリにも同じゴミデータが即座に反映されてしまいます。
CDPは、同じタイムラインを捉える別の視点です。CDPは別の場所にライブコピーを保持するのではなく、同じコピーの「タイムマシン」を保持します。暗号化が17:40に開始されたため、17:39:52の状態に戻す必要がある場合、レプリケーションでは何も得られませんが、CDPならまさにその状態を復元できます。
実際には、両方が必要です。ハードウェア障害やサイトレベルの障害には同期レプリケーションを、オペレーターのミス、アプリケーションのバグ、悪意のある書き込みにはCDPをそれぞれ活用します。アクティブ-アクティブのSANアーキテクチャでは、通常、StarWind Virtual SANやDataCore SANsymphonyがレプリケーションを担当し、その上にCDP対応のバックアップ層(Veeam CDP、Zerto、またはSANsymphony独自のCDP機能)を配置します。
実際に、費用はどれくらいかかるのか
CDPは無料ではありませんし、マーケティング資料では実際のコストについて詳しく説明されることはほとんどありません。費用を左右する主な要因は以下の3つです:
ジャーナルストレージ:ジャーナルは、保持期間中、すべての変更内容を保持します。1時間あたり40GBのデルタを書き込む2TBのデータベースを保護し、24時間の保持期間を設定する場合、変更データだけでもジャーナルには約40 × 24 = 960GBが必要となり、さらにメタデータのオーバーヘッドや圧縮による節約分(通常30~50%)が加わります。書き込みパターンが予測できないVM群があると、容量計画はさらに複雑になります。
書き込み増幅:保護対象の書き込みはすべて、プライマリボリュームとジャーナルの少なくとも2つのターゲットに書き込まれます。ジャーナルが別のノードやサイトに存在する場合、ツルーCDPでは同期パス上のネットワークトラフィックとなり、ニアCDPでは数分ごとにバースト状のトラフィックが発生します。レイテンシに敏感なワークロード(OLTPデータベース、VDI)では、設計を承認する前に、代表的なワークロードでのオーバーヘッドを測定する必要があります。適切にチューニングされていないCDP環境では、30%以上のレイテンシオーバーヘッドが発生する可能性があります。
復旧は瞬時ではありません:これはよく忘れられがちな点です。CDPはRPOをほぼゼロに近づけることができますが、RTOは依然として、復旧したボリュームを起動し、再マウントし、アプリケーションを復旧させるのにかかる時間そのものです。単一のVMであれば数分ですが、20ノードのデータベースクラスタであれば数時間かかることもあります。RPOとRTOの両方をほぼゼロにする必要がある場合は、CDP単独ではなく、CDPとアクティブ-アクティブレプリケーションの組み合わせを検討する必要があります。
CDPの複雑さが正当化される場合
CDPが真価を発揮するのは、ごく限られたシナリオに限られます。それ以外のケースでは、定期的なバックアップと不変ストレージを組み合わせることで、わずかなコストで同等のメリットの大部分を得ることができます。
CDPが真に費用対効果を発揮するワークロード:CDPがおそらく過剰なワークロード:アーカイブデータ、読み取りが主体の参照システム、開発/テスト環境、および毎日のスナップショットでRPO目標が達成されるあらゆるケース。毎晩変更されるデータマートに対して、書き込みごとのジャーナリングに費用をかけるのは無駄である。
●トランザクションの1分間の損失が直接的な金銭的損失につながるOLTPデータベース(請求、取引、発券など)。
●単一の復元ポイントを見逃しただけで数時間に及ぶ照合作業を余儀なくされる、ERPやEHRシステムを実行するVM。
●ランサムウェアからの復旧が「いつ起こるか」ではなく「必ず起こる」問題となる業界の、本番用ファイル共有。これらについては、ストレージのオーバーヘッドは明らかにその価値があります。インフラコスト自体のX倍もの損失から身を守るための保険となるからです。
現場からの実践的なメモ
新しいCDP対応のバックアップ戦略を導入する前に知っておくべきいくつかのポイント:
実際に懸念している障害パターンに合わせて、保持期間を設定してください。多くの人はデフォルトで24時間としますが、有効な保持期間は問題に気付くまでに要する時間によって異なります。ランサムウェアは通常、数時間以内に検出されます。バグのあるアプリケーションによる緩やかな論理的破損は、表面化するまでに数週間かかる場合があります。その期間内に確実に問題を検知できると断言できないのであれば、その期間は短すぎます。
CDPには不変ストレージを組み合わせてください。CDPのジャーナルは、保護対象と同じプラットフォーム上に存在する(ストレージパフォーマンス向上のため)ことが多いため、十分な執念を持った攻撃者であれば、プライマリデータと共にジャーナルを削除できてしまう可能性があります。その対策として、一定期間変更や削除ができないストレージに書き込む第2層のバックアップが必要です。Veeam Hardened Repositoryなどがこれに適しています。CDPは迅速かつ直近の復旧を目的としていますが、不変バックアップはCDP自体が侵害された際のフォールバックとなります。
ジャーナルを暗号化してください。保護対象のすべてのボリュームに対する変更がそこに記録されていますが、一部の製品ではデフォルトで平文のまま保存されています。ジャーナルの保存先がネットワーク経由でアクセス可能な場合は、転送中および保存時の両方で暗号化してください。ほとんどのエンタープライズ向けCDP製品はこれをサポートしていますが、デフォルトで有効になっているわけではありません。
実際に復元テストを実施してください。CDPダッシュボードは、レプリケーションの遅延やジャーナルの健全性について緑色のチェックマークを表示するのが大好きです。しかし、それだけでは、負荷がかかった状況下で復元が機能するかどうかはわかりません。実際の(本番環境ではない)ターゲットでの四半期ごとの復元テストを行うことで、監視だけでは見逃してしまう問題を発見できます。
StarWindとDataCoreの役割
StarWindでは、CDPに関する質問を絶えず受けます。たいていは、ランサムウェア被害のコストを試算したばかりで、昨年は何を導入すべきだったのかを知りたいという方からの問い合わせです。
簡単に言えば、私たちは多層的な構成を推奨しており、各層は互換性がないということです。
StarWind Virtual SANはCDP製品ではありません。当社のVSANは、ストレージ層においてノード間の同期アクティブ-アクティブレプリケーションを提供します。これにより、ディスク、ノード、またはネットワークの障害に対してRPOゼロの保護を実現し、VMのフェイルオーバーを数秒で完了させます。ただし、VSANが提供しないのがポイントインタイムリカバリです。VSANボリュームにデータ破損が発生した場合、その破損は両方のコピーに同時に生じます。VSANはCDPを構築するための基盤であり、CDPの代替となるものではありません。
どちらのプラットフォーム上でVMレベルのCDPを導入する場合でも、Veeamが一般的な選択肢となっています。Veeam CDPポリシー(現在はVMwareのみ対応)では、ハイパーバイザーにI/Oフィルターをインストールすることで、RPOを数秒単位まで短縮でき、復元ポイントは日常のバックアップに既に使用しているのと同じVeeamリポジトリに保存されます。これをVeeamのHardened Repositoryと組み合わせれば、CDP、スケジュールされたバックアップ、不変ストレージを1つのワークフローで実現できます。
ミッションクリティカルな環境に対する当社の標準的な推奨構成は以下の通りです。ストレージのHA(高可用性)にはアクティブ-アクティブ構成のVSAN、最上位ワークロードのポイントインタイム復旧にはVeeam CDP、そして最終的な安全策として不変バックアップリポジトリを採用します。これにより、ハードウェア障害、論理的なデータ破損、ランサムウェアへの対策がカバーされ、どの単一レイヤーも単一障害点(SPOF)となることはありません。これはまさに、事業継続計画が求めるべき多層防御の形態です。
結論
データ損失が数分間発生するだけで、セカンドデータパスの運用コストを上回る損害が生じる場合、CDPは費用と複雑さを払う価値があります。環境内のワークロードのうち、その条件に該当するものがわずかでもあれば(通常はすべてではなく、ほんの一部です)、4時間かかっていたインシデント対応を4分に短縮できます。それ以外のワークロードについては、不変性(イミュータブル)な保存期間を設定した、適切に設計された定期バックアップであれば、運用負荷を大幅に軽減しつつ、ほぼ同等の効果を発揮します。重要なのは、どのワークロードをどのカテゴリに分類するかを正直に判断し、熟練者以外に説得されてアーカイブ層にまでCDPを導入しないようにすることです。
 RSSフィードを取得する
RSSフィードを取得する






