


Amazon S3は、多くのクラウドおよびハイブリッド環境におけるオブジェクトストレージの基盤です。ここでは、そのアーキテクチャ、ストレージクラス、そしてバックアップ、分析、長期保存への適用方法について解説します。
現代のIT環境において、クラウドサービスはデータの保存、アクセス、保護の方法において中心的な役割を果たしています。オブジェクトストレージシステムの中で、S3プロトコルは事実上の標準となっています。物理インフラを管理する代わりに、S3は事実上無制限の規模でデータを保存・取得する、シンプルでAPI駆動型の方法を定義しています。
一般的にオブジェクトストレージについて話す場合でも、「S3」と言えばAmazon S3を指すことが多いのです。AWSはAmazon Simple Storage Service(Amazon S3)を通じて、最も広く採用されているS3互換オブジェクトストレージを提供しています。早期導入とエコシステム統合により、Amazon S3はS3互換ストレージの標準実装として広く認識されています。
AWSは数百のサービスを提供していますが、ここでは特にAmazon S3に焦点を当てます。S3ストレージの定義、技術的な動作原理、AmazonによるS3モデルの実際の実装方法を解説します。さらに、ストレージクラス、実践的な導入手順、一般的なユースケースについても取り上げます。
目次
S3ストレージとは?
S3ストレージを理解するには、S3プロトコルと特定の製品を区別することが役立ちます。この区別により、「S3とAWSの違い」に関する一般的な混乱が解消されます。
S3プロトコルは、オブジェクトストレージ向けのRESTベースのAPIです。これは、PUT、GET、DELETE、LISTといった限定された操作セットを用いて、HTTP経由でデータがどのように保存、アドレス指定、アクセスされるかを定義します。このプロトコルは、以下のいくつかの核心的な概念を中心に構築されています:
- バケット(Buckets):論理的なコンテナとして機能します
- オブジェクト(Objects):データとメタデータを含みます
- オブジェクトキー(Object keys):バケット内のオブジェクトを一意に識別します。
ファイルシステムやディレクトリという概念はネイティブには存在しません。フォルダのように見えるものは、単にキーのプレフィックスに過ぎません。この「フラット」な設計が、従来のストレージと比較してS3が優れたスケーラビリティを発揮する理由の一つです。
S3プロトコルはステートレスであり、標準的なWeb技術に基づいているため、クラウドおよびオンプレミスプラットフォームを横断して、オブジェクトストレージ向けに最も広くサポートされているインターフェースとなっています。
では、実用的な観点からS3ストレージとは何でしょうか? S3ストレージは、S3互換のAPIを公開するオブジェクトストレージシステムです。データは階層構造内のファイルやボリューム上のブロックとしてではなく、独立したオブジェクトとして保存されます。オブジェクトは通常不変と扱われ、データを変更するには既存のオブジェクトを修正するのではなく、新しいオブジェクトを作成する必要があります。これは意図的な設計であり、大規模環境での整合性を簡素化します。
S3ストレージは主に非構造化データ(バックアップ、アーカイブ、メディアコンテンツ、アプリケーション資産、ログ、VMイメージ、分析データセット、機械学習トレーニングデータなど)に使用されます。オブジェクトサイズは、小さな設定ファイルから数テラバイト規模のブロブまで多岐にわたります。
ほとんどのS3互換システムは、プロトコルに一般的に関連付けられる機能(アクセス制御ポリシー、メタデータとタグ付け、オブジェクトバージョン管理、ライフサイクルルールなど)も実装しています。これらの機能が、S3を単なるストレージではなく自動化に実用的なものとしています。
AmazonはAmazon Simple Storage Serviceを通じてS3プロトコルを実装しています。AWSはこれを物理インフラを抽象化した完全管理型サービスとして提供します。データはAWSリージョン内の複数システムに冗長的に保存され、高い耐久性と可用性を実現します。AWSはコアプロトコルを拡張し、複数のストレージクラス、ライフサイクル自動化、暗号化オプション、広範なAWSエコシステムとの統合を提供しています。こうした拡張にもかかわらず、アクセスは依然として同じS3 APIを経由します。これがAmazon S3が一般的にリファレンス実装と見なされる理由です。
S3ストレージはどのように機能しますか?
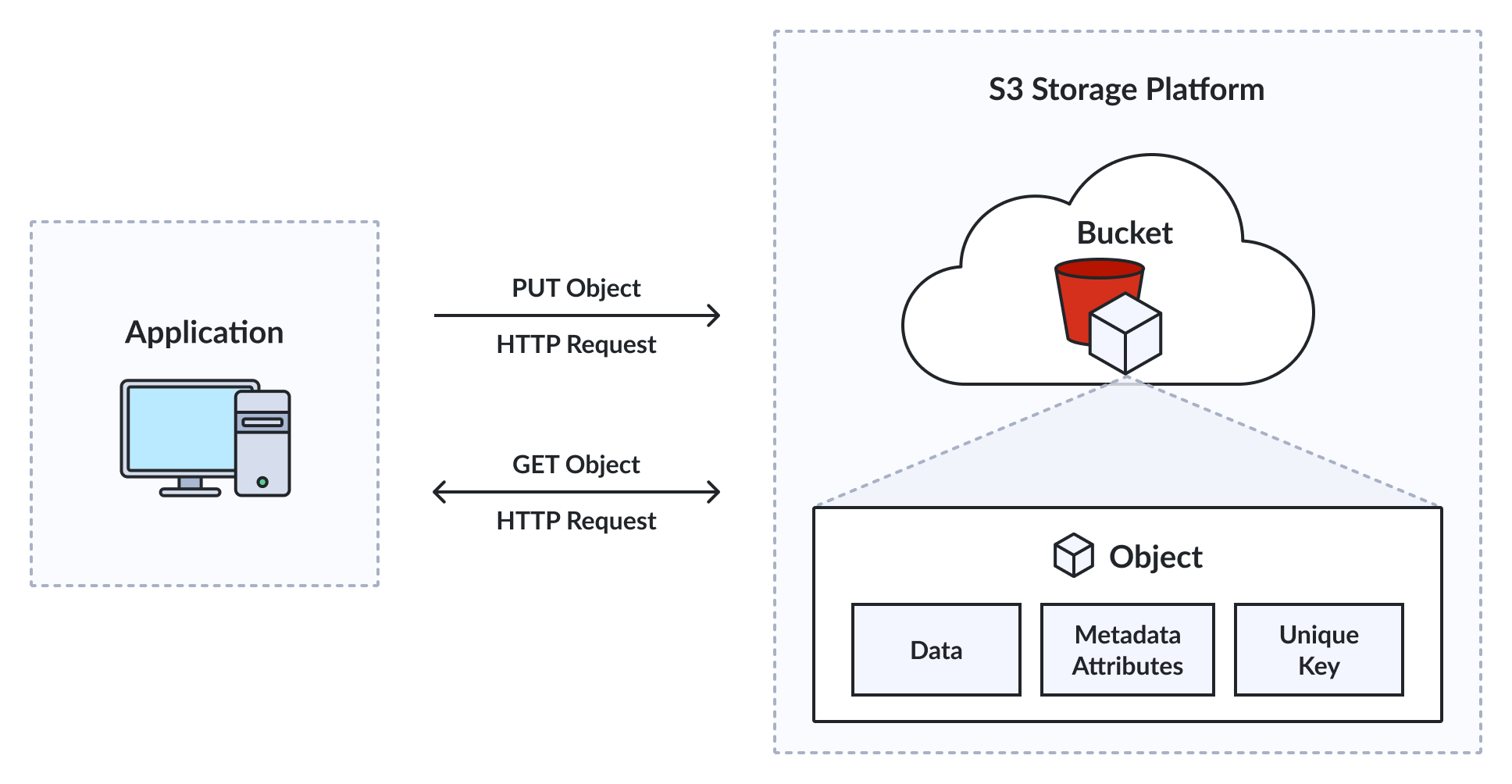
アプリケーションはステートレスなHTTP呼び出しを通じてS3とやり取りします。各オブジェクトは、データ本体、メタデータ属性、およびバケット内でそれを識別する一意のキーで構成されます。オブジェクトはファイルシステム階層や物理的な位置に依存しないため、ストレージプラットフォームは必要に応じてインフラストラクチャ全体に分散配置します。この処理はアプリケーションに対して透過的です。
このモデルは大規模かつ非構造化ワークロードに最適です。アプリケーションはオブジェクトの読み書きを並行して実行でき、ストレージシステムはデータ増加に応じて拡張されるため、ボリューム管理や容量計画を気にする必要はありません。
S3はオブジェクトロックによる不変性もサポートします。有効化すると、オブジェクトは定義された保持期間中または無期限に修正・削除できなくなります。これがS3がバックアップやコンプライアンスデータに選ばれる主な理由です。オブジェクトのバージョン管理は過去のバージョンを保持することで保護層を追加し、誤削除や上書きからの復元を可能にします。
コア構成要素
バケットは最上位のコンテナです。すべてのオブジェクトはバケットに属し、バケットに対してアクセスポリシー、暗号化、ライフサイクルルール、レプリケーション設定を適用します。S3の設計上の多くの決定はバケットレベルから始まります。
キーはバケット内のオブジェクトを一意に識別します。キーはファイルパス(例: logs/2024/jan/access.log)のように見える場合がありますが、実際のディレクトリ階層を表すものではありません。スラッシュはオブジェクト名の一部であり、論理的な整理に使用されます。
リージョン(Amazon S3内)は、データが物理的に保存される地理的位置を表します。バケットは特定のAWSリージョンに作成され、レプリケーションを設定しない限りデータはそのリージョンに留まります。リージョンの選択は、レイテンシ、コスト、コンプライアンス態勢、災害復旧設計に影響を与えます。
Amazon S3のストレージクラスとは?
Amazon S3は、異なるアクセスパターンとコストプロファイル向けに設計された複数のストレージクラスを提供します。その考え方は、単に安価なストレージを提供するのではなく、データの実際の使用方法に応じてコストを最適化することにあります。ストレージクラスはバケットレベルまたはオブジェクトレベルで割り当てることができ、ライフサイクルポリシーにより、アクセスパターンの変化に応じてデータを自動的に階層間で移動させることが可能です。
S3 Standardは、頻繁にアクセスされ、レイテンシーに敏感なワークロード向けに設計されています:アクティブなアプリケーションデータ、ウェブサイト、分析、コンテンツ配信など。データはリージョン内の複数のシステムに冗長的に保存されます。
S3 Standard-Infrequent Access (Standard-IA)は、Standardと同じ耐久性とミリ秒単位のアクセスを提供しますが、GBあたりのストレージ価格が低くなっています。その代わりに、GBあたりの取得料金と128 KBの最小オブジェクトサイズ料金が発生します。さらに30日間の最低保管期間が設定されています。30日以内にオブジェクトを削除した場合でも、30日分の料金が請求されます。このためStandard-IAはバックアップコピーや月に数回アクセスするデータには最適ですが、迅速に削除または上書きされる可能性のあるデータには不向きです。
S3 Glacier および S3 Glacier Deep Archiveは、長期保存とコンプライアンス対応向けに設計されています。Amazon S3で最も低いストレージコストを提供しますが、データ取得は即時ではありません。Glacierの取得には数分(Expedited)から数時間(Bulk)を要し、Deep Archiveの取得はデフォルトで12時間以上かかります。両サービスとも90日間(Glacier)または180日間(Deep Archive)の最低保管期間が設定されています。これらの階層は、保持義務があるもののほとんどアクセスしないデータ(監査ログ、法的保持、規制アーカイブなど)に最適です。
Amazon S3 の基本操作
Amazon S3 を利用するには、規模や自動化の必要性に応じて主に 2 つの方法があります。
AWS マネジメントコンソールは、バケットの作成、リージョンの選択、権限、暗号化、ストレージクラスなどの設定を行うための Web インターフェースを提供します。これは最も迅速に操作を習得できる方法であり、小規模なアップロードや実験には十分対応できます。
手動テストを超える用途では、AWS CLIとSDKが標準的な手段となります。CLIを使用すれば、バケットの作成、アップロード/ダウンロード操作、ライフサイクルポリシー、クロスリージョンレプリケーションを繰り返し可能な方法でスクリプト化できます。本番環境では、S3はほぼ常にAPI駆動で運用されます。バックアップソフトウェア、CI/CDパイプライン、災害復旧プラットフォーム、大規模データ転送ワークフローと統合されるのです。
Amazon S3の主な特徴
Amazon S3の特性の一部はオブジェクトストレージモデルそのものに由来し、他の特性はAWSが大規模でサービスを運用する方法に反映されています。これらが組み合わさって、S3が実環境で提供する価値を形成しています:
耐久性。Amazon S3はオブジェクトをリージョン内の複数のストレージシステムに冗長的に保存します。ハードウェア障害は自動的に処理され、管理すべきレプリケーションスクリプトは存在しません。AWSは、スタンダードストレージの設計目標として99.999999999%(11の9)の耐久性を公表しています。
可用性。分散アーキテクチャにより、個々のコンポーネントが障害を起こしてもデータへのアクセスを維持します。スタンダードストレージは、1年間で99.99%の可用性を実現するよう設計されています。
サーバーサイド暗号化(SSE)。S3はデフォルトで保存中のデータを暗号化します(SSE-S3)。AWS KMS管理キー(SSE-KMS)の使用や、独自のキー提供(SSE-C)も可能です。これにより、アプリケーション変更なしで基本コンプライアンス要件を満たせます。
大規模オブジェクト対応。単一オブジェクトは最大5TBまで保存可能。マルチパートアップロードにより大容量ファイルを分割し並列アップロードするため、スループットが向上し、失敗時の再開が可能です。このため、VMバックアップや大規模データベースのスナップショットがS3上で確実に機能します。
弾力的な容量。バケットは自動的に拡張します。事前計画が必要な容量やサイズ変更が必要なボリュームはありません。プロビジョニングした分ではなく、実際に保存した分だけ課金されます。
従量課金制。コストは使用したストレージ、発行したリクエスト、転送したデータに基づいて計算されます。この消費モデルにより、初期投資なしで小規模から開始し、スケーリングが可能です。ただし、高負荷時のリクエストコストには注意が必要です。累積する可能性があります。
S3の一般的な利用ケース
災害復旧。S3は重要データのオフサイトコピー先として広く利用されています。その耐久性とオンデマンドでのスケーラビリティにより、DR用にローカルストレージを過剰にプロビジョニングする必要がありません。復旧時には、規模に関わらず標準のS3 APIを通じてデータにアクセス可能です。標準-IAクラスがここで人気のある選択肢です。ストレージコストが低く、実際の災害からの復旧時における取得料金も許容範囲内です。
バックアップとアーカイブ。オブジェクトを長期間変更なしで保持できるため、バックアップワークロードはS3に自然に適合します。S3互換ストレージは、セカンダリバックアップ、コンプライアンス保持、長期アーカイブに頻繁に利用されます。数か月~数年保存が必要だがアクセス頻度が極めて低いデータには、GlacierおよびGlacier Deep Archiveが最安コストを提供します。ただし、データ取得時間の要件が選択した階層と一致していることを確認してください。数分単位でのデータ復旧が必要な場合、Glacier Deep Archiveは適切な選択肢ではありません。
データレイクと分析: S3はビッグデータや機械学習ワークフローの基盤として広く利用されています。大量の非構造化データを保存し、S3 APIを介して並列アクセスする仕組みは、Athena、Spark、Prestoなどの分析エンジンと相性が良いです。分析ワークロードはデータの読み取り頻度が高いため、ここでは通常S3 Standardが選択されます。
静的コンテンツとメディアホスティング: S3は静的ウェブサイト、メディア資産、ダウンロード可能ファイルをHTTP経由で直接保存・配信できます。CloudFront(AWS CDN)と組み合わせることで、アプリケーションサーバーから帯域幅とインフラ管理の負荷を軽減します。
ソフトウェア配布:企業はS3を利用してパッケージ、更新プログラム、アプリケーションバイナリを配布します。S3 APIのグローバルなアクセス性と大容量オブジェクトのサポートにより、分散システムへのソフトウェア配信に最適です。Standardストレージクラスは高速かつ信頼性の高いダウンロードを保証します。
クライムが提供できるものは?
クライムは、オンプレミスおよびハイブリッド環境向けの各種S3ストレージソリューションを提供します。
関連トピックス:
- VMware vCenter Operations(パフォーマンス・モニタリング・バッジ)の概要
- Veeam社、Microsoft System Centerレポーティング用拡張Generic Report Libraryの提供開始
- AWS S3オブジェクトロックでデータの安全性を確保する手法
- VMworld2018 in ラスベガス レポート② Veeamセッション
- ブロック・ストレージとオブジェクト・ストレージ:その違いは?
- VMwareユーザ・アカウントのカスタマイズ化でESXiホスト・セキュリティの改善
- KubeCon + CloudNativeCon North America 2019 に参加して
- ESX、仮想マシンのパフォーマンス監視【仮想化プラットホーム VMware vSphere】
 RSSフィードを取得する
RSSフィードを取得する







注目:規制対象データに対応するS3準拠ストレージ