
Reference Architectureとは?
リファレンス アーキテクチャ(reference architecture)とは、ごく簡単に言えば、IT環境のシステム構成を文書化したもので、諸々のハードウェア、ソフトウェアなど、何をどう組み合わせて、どう設定したのか、経験則にもとづく最善策を担当者が記録し、社内でその知識を共有するための文書です。言うなれば、システム構成・インフラ設定のベストプラクティス(best practice)です。


Reference Architectureとは?
リファレンス アーキテクチャ(reference architecture)とは、ごく簡単に言えば、IT環境のシステム構成を文書化したもので、諸々のハードウェア、ソフトウェアなど、何をどう組み合わせて、どう設定したのか、経験則にもとづく最善策を担当者が記録し、社内でその知識を共有するための文書です。言うなれば、システム構成・インフラ設定のベストプラクティス(best practice)です。
 クラウドベースのバックアップにより、あらゆる規模の組織、特に中小企業(SMB)が、収益に大きな影響を与えることなく、増大するストレージ要求を克服することが可能になりました。 続きを読む
クラウドベースのバックアップにより、あらゆる規模の組織、特に中小企業(SMB)が、収益に大きな影響を与えることなく、増大するストレージ要求を克服することが可能になりました。 続きを読む

「データが大事なら、バックアップしろ」は、誰もが経験上知っているはずの鉄則です。そして、バックアップされたデータは、以前は物理メディアに保存されてきました。ハードドライブ、NAS(ネットワークHDD)、テープなどです。その後、クラウドプロバイダが最低99.5%の可用性と、ギガバイト単位で低価格のストレージサービスを提供するようになってからは、もっぱらクラウドがバックアップ保存先の主流になりました。
 特に一般的なものはありませんが、スケジューリングに関して正しいアプローチはあります。
特に一般的なものはありませんが、スケジューリングに関して正しいアプローチはあります。
現在も現役で使用されているユーザーも多いであろうWindows Server 2008/R2、SQL Server 2008/R2の延長サポートも終了まで1年(Windows 2008/R2は2020年1月まで、SQL 2008/R2は2019年7月まで)を切りました。
期限までにバージョンアップするか、有償のカスタム延長サポートを購入するか、はたまたサポートがないことを承知で使い続けるかを判断する必要がありましたが、2018年7月に新しい選択肢が追加されました。
AWS上に存在するデータとワークロードを定期的にバックアップする必要があります。
理由は以下の通りです。
Amazon Web Services(AWS)クラウドコンピューティングには、従来のオンサイトインフラストラクチャモデルと比べて、利便性、スケーラビリティ、コスト、セキュリティなどの多くのメリットがあります。
ストレージスナップショットは、2つの異なる方法で作成できます。
最初の方法は差分スナップショットと呼ばれます。 このタイプのスナップショットの背後にある基本的な考え方は、スナップショットが作成されると、システムが実際に差分ディスクを作成するということです。
その時点から、すべての書き込み操作は、プライマリストレージではなく差分ディスクに向けられます。
プライマリストレージが変更されないようにして、必要に応じてシステムを元の状態に戻すことができます。
ラスベガスで8/26~8/30に開催されたVMworld2018の概要をご紹介いたします。
VMWorldは今回で15回目となり、世界各国から2万人以上、日本からはおよそ380名が参加しました。
今回のテーマは “Possible begins with you”でした。

ジェネラルセッションの様子です。
今回はプライベートクラウドと併せて用途別に様々なパブリッククラウドを使用する、
『マルチクラウド』という単語がよく聞こえてきました。
VMworld2018のVeeamのセッションの概要です。
次にリリース予定のUpdate 4で追加予定機能が紹介がメインでした。

EC2のバックアップソリューションをあなたは本当に必要としますか?多くのユーザーはサービスとしてサーバーを手に入れると、サーバーの管理も全て含まれていると決め込みます。従来のデータセンターと比較すると、AWSはハードウェアの問題をすべて対処します。つまり、ハードウェアの障害によってデータが失われることはありません。ただし、ハードウェア以外のデータ損失シナリオは対処されません: 続きを読む
最初に今回のVPNベースのリモート・バックアップ・リポジトリを作成するために必要なチェック・リストを以下に示します。
1. 2台のWindowsシステムが、別々の場所にある。仮想環境か物理環境のどちらかで。今回はWindows10をクライアント・サイドの例として使用。
2. VPNサーバと使用するリモートのリポジトリ・システム用に外部スタティックIPで、ユーザはインターネット上で直接このシステムに接続可能。
3.VPNコンフィグレーションでネットワーク・アダプタ設定変更とバックグラウンド・システム・サービスを稼働させることで両システムに管理者権限を有します。
4. SoftEther VPNのサーバとクライアントの各ディストリビューション・ソフト(今回はVPNにSoftEther VPNを使用)
5.CloudBerry Backupを活用
パート2では、EC2でディスクアレイに対してEBSスナップショットでバックアップを行う場合の課題をご紹介しました。今回は、複数のEBSボリュームにまたがり、構成されたLVMボリュームでバックアップを実行する場合についてご紹介します。
パート1では、EC2でディスクアレイ構成を行うこと自体の意味に関してご紹介しました。
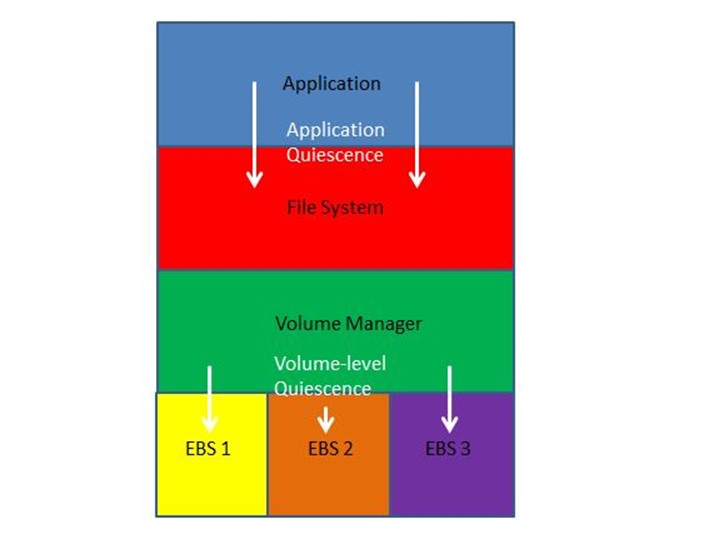
どのようにディスクアレイの一貫性を保証するか?ストレージスタックについて考える場合、それぞれの階層が他の階層の実装を認識していないことを意識する必要があります。例えばストレージの層でパフォーマンスの向上のためにキャッシュが実装されているとします。この場合、アプリケーションが開いているファイルのデータは実際にはメモリ内キャッシュに存在するかもしれません。しかし、アプリケーションはファイルシステムがキャッシュを実装しているか、またどのようにデータをキャッシュしているかは必ずしもわかりません。つまり、アプリケーションがデータを保存するためにはファイルを閉じるか、ファイルシステムにデータをフラッシュするための特殊なAPIを用いる必要があります。ただ、ファイルシステムとボリュームについては同じようにはいきません。
 RSSフィードを取得する
RSSフィードを取得する









