DBMotoにおいて、SQL Serverから差分データをレプリケーションする場合、
SQL Serverのディストリビューターを使用するか、トリガーを使用します。
SQL Server StandardやEnterpriseエディションの場合、ディストリビューター/トリガー双方ともサポートしておりますが、Webエディションや無償版のExpressエディションについてはディストリビューター自体がサポートされていないため、トリガー方式のみの対応となります。

DBMotoにおいて、SQL Serverから差分データをレプリケーションする場合、
SQL Serverのディストリビューターを使用するか、トリガーを使用します。
SQL Server StandardやEnterpriseエディションの場合、ディストリビューター/トリガー双方ともサポートしておりますが、Webエディションや無償版のExpressエディションについてはディストリビューター自体がサポートされていないため、トリガー方式のみの対応となります。
CloudBerry Backupによる SQLServerの自動 バックアップのステップを紹介します。
続きを読むDBMotoではグループやレプリケーションごとに細かくメール通知の設定を行えます。
この設定では、メッセージのステータスによる通知可否を指定する他に、フィルタに一致するもののみを通知するように指定できます。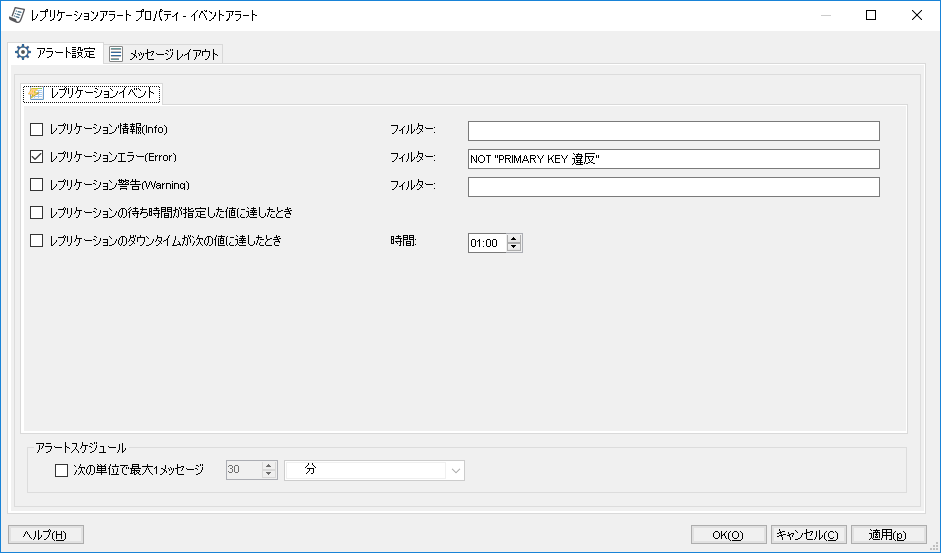
エンタープライズ・レベルの企業は、Oracleプラットフォームをミッション・クリティカルなアプリケーションで使用しています。昨今、このOracleプラットフォームをVMwareおよびHyper-V環境で運用されることが多くなりました。その仮想化されたOracleデータベースのバックアップ・リストア手法を紹介します。
異種データベース間の双方向レプリケーションツールDBMotoでは、スクリプトを使用することでカラムの結合・分割を行いながらデータを同期することも可能です。今回の記事では双方向レプリケーションにおいてカラムの結合・分割を実現するサンプルスクリプトとその設定方法をご紹介いたします。
MSSQLは、マイクロソフトが開発したWindowsプラットフォーム上で、最も一般的なリレーショナルデータベース管理システムです。このデータベースソフトウェア製品の主な機能は、他のソフトウェアアプリケーションによって要求されたデータを格納および検索することです。このブログでは、AWSでホストされているMSSQLを見て、Microsoftが提供するバックアップとリストアのプロセスに固有の3つのオプションを示します。このブログでは、MSSQL 2008 R2 Standard Editionを使用しました。ただし、MSSQLによって提供される同じバックアップおよびリストアメカニズムは、他のMSSQLバージョンにほとんど適用可能です。 続きを読む
こちらの記事では、データを暗号化しレプリケーションする方法をご紹介しました。本記事では、この暗号化したデータを復号してデータ連携を行う手法を3ステップでご紹介します。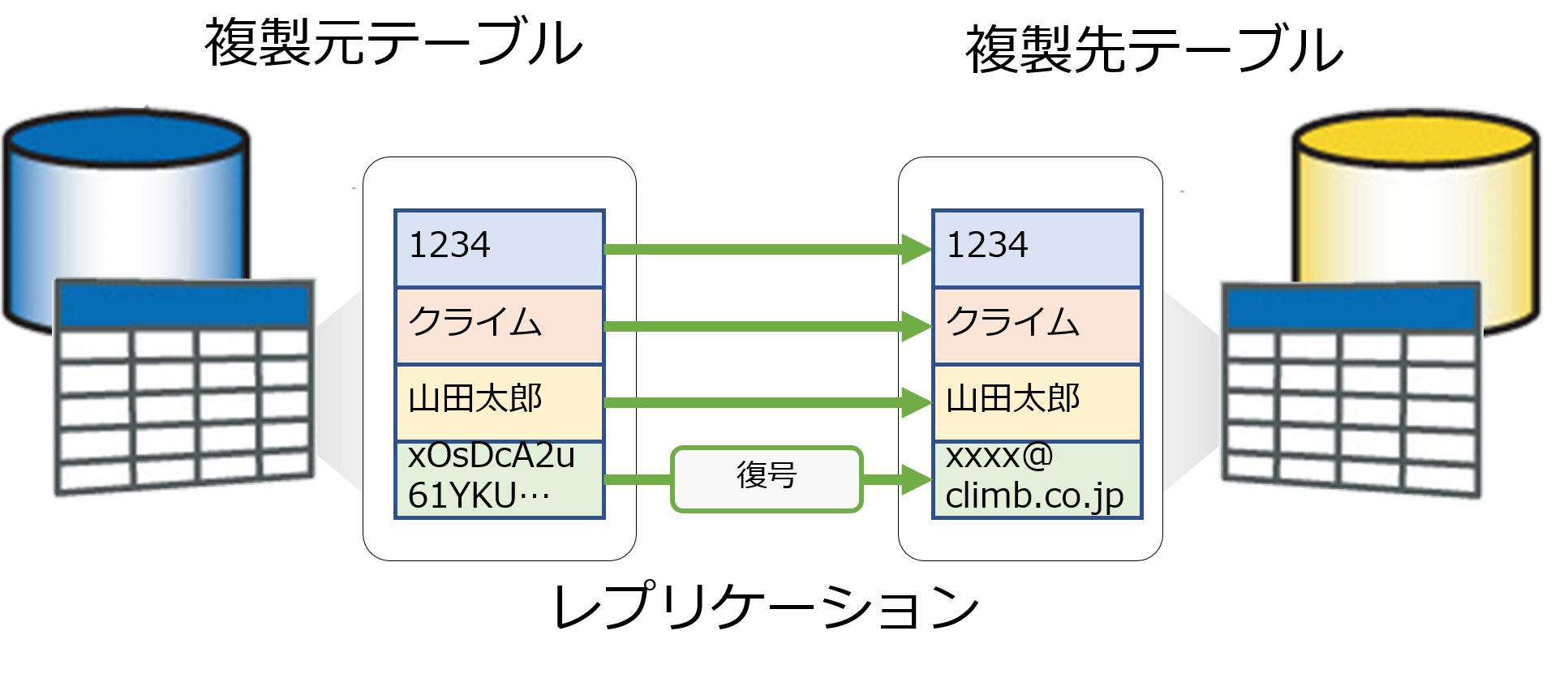 手順1. 復号関数の作成
手順1. 復号関数の作成
DBMotoは異種データベース間リアルタイムレプリケーションツールです。複製元テーブルにデータの更新があった場合、更新されたデータを複製先テーブルにリアルタイムで反映することができます。このレプリケーションの機能では、スクリプトを設定しデータを加工することも可能です。本記事ではスクリプトを活用し、テーブル内のデータを暗号化してレプリケーションを行う手法を3ステップでご紹介します。
DBMotoは2008年春からデータ連携の複製元、複製先としてInformix のサポートを開始し、2008年6月にIBMからInformix Dynamic Serverの認定を受けました。
当初はトリガー・ベースのレプリケーションのみをサポートしておりましたが、現在はInformix のトランザクションログ・ベースのレプリケーションもサポートしております。ログの参照方法としてログ・サーバー・エージェント方式を採用しているため、DBMotoサーバーにClient SDKが必要になります。
DBMoto 9.5より、Log ReaderとTrigger方式以外にLog Server Agent方式で
ミラーリング、シンクロナイゼーションを行うことができるようになりました。
Log Server Agent方式を使用することでSQL Serverのdistributorを使用し、
単一の接続ですべてのレプリケーションの変更点を読み取ります。

 RSSフィードを取得する
RSSフィードを取得する