
昨今、各企業で蓄積したデータを次のビジネスに活かすために、様々なBIツールや分析ツールが
オンプレミスでも、仮想環境でも、更にはクラウドでも多く提供されています。
特にこれまではWindowsやLinuxマシンにインストールし、動かしていたBIツールや分析ツールも、
ベンダー各社 サービスとして提供されるようになり、管理の容易さから見ても これから導入しようという企業も多いと思います。
その中で各種サービスでは、データソースとして多くのデータベースやファイル形式をサポートしておりますが、やはり今後主流となってくるのはAmazon S3などのクラウドストレージ上にデータを配置し、分析する手法になると想定されます。
このようなAmazon S3に対しても、Syniti Data Replicationであればコーディングすることなく、
すべてGUIベースでオンプレ/仮想/クラウドに展開されているデータベースからレコードを連携することができます。
それでは早速Syniti Data ReplicationでAmazon S3を登録する方法をご紹介します。
-
事前準備
Syniti Data Replication(旧DBMoto)をインストールしたWindowsマシンに、AWS Toolkit for .NETが必要となります。
こちらのAWS公式サイトより、インストーラを取得してインストールします。
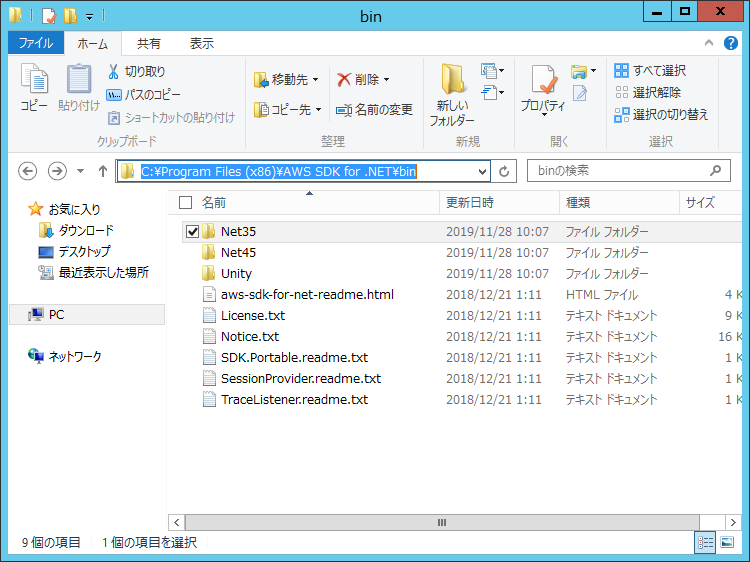
デフォルトのインストールでは、以下のフォルダパスへ展開されます。
C:\Program Files (x86)\AWS SDK for .NET\bin
- Syniti Data Replicationへの登録
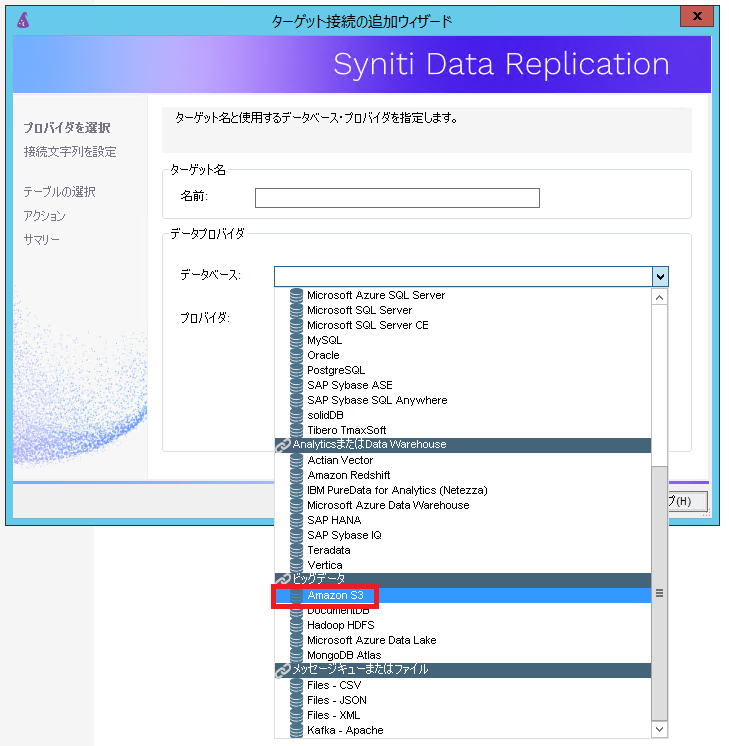
まず、ターゲット接続追加ウィザードにて、 Amazon S3を選択します。
 次に、各種パラメータを追加していきます。
次に、各種パラメータを追加していきます。
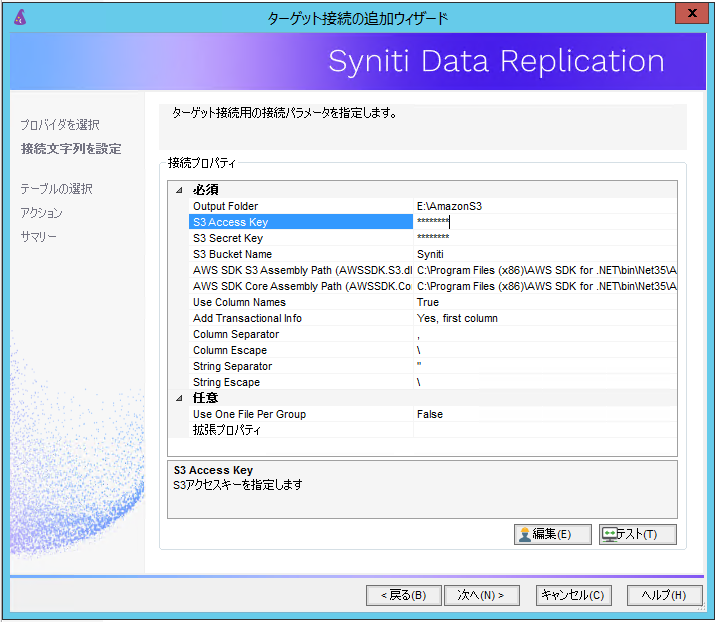
入力が必要となる項目は、以下の6つとなります。
Output Folder : レプリケーションで生成する一時ファイルをエクスポート先を指定します。
S3 Access Key : AWSアカウントのアクセスキーを指定します。
S3 Secret Key : AWSアカウントのシークレットキーを指定します。
S3 Bucket Name : レプリケーション先のS3バケット名を指定します。
AWS SDK S3 Assembly Path (AWSSDK.S3.dll) : AWSSDK.S3.dllのパスを指定します。
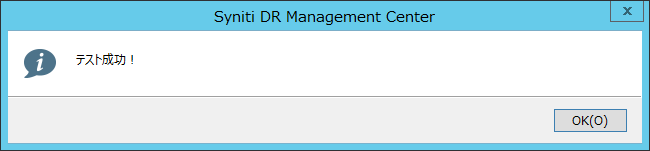
AWS SDK Core Assembly Path (AWSSDK.Core.dll) : AWSSDK.Core.dllのパスを指定します。ここまで入力し、テストを実行することで、Amazon S3と正しく接続が行えていることが確認できます。
- レプリケーションジョブ作成と実行
Amazon S3へのレプリケーションジョブも、他のデータベースと同じようにGUIから作成することができます。
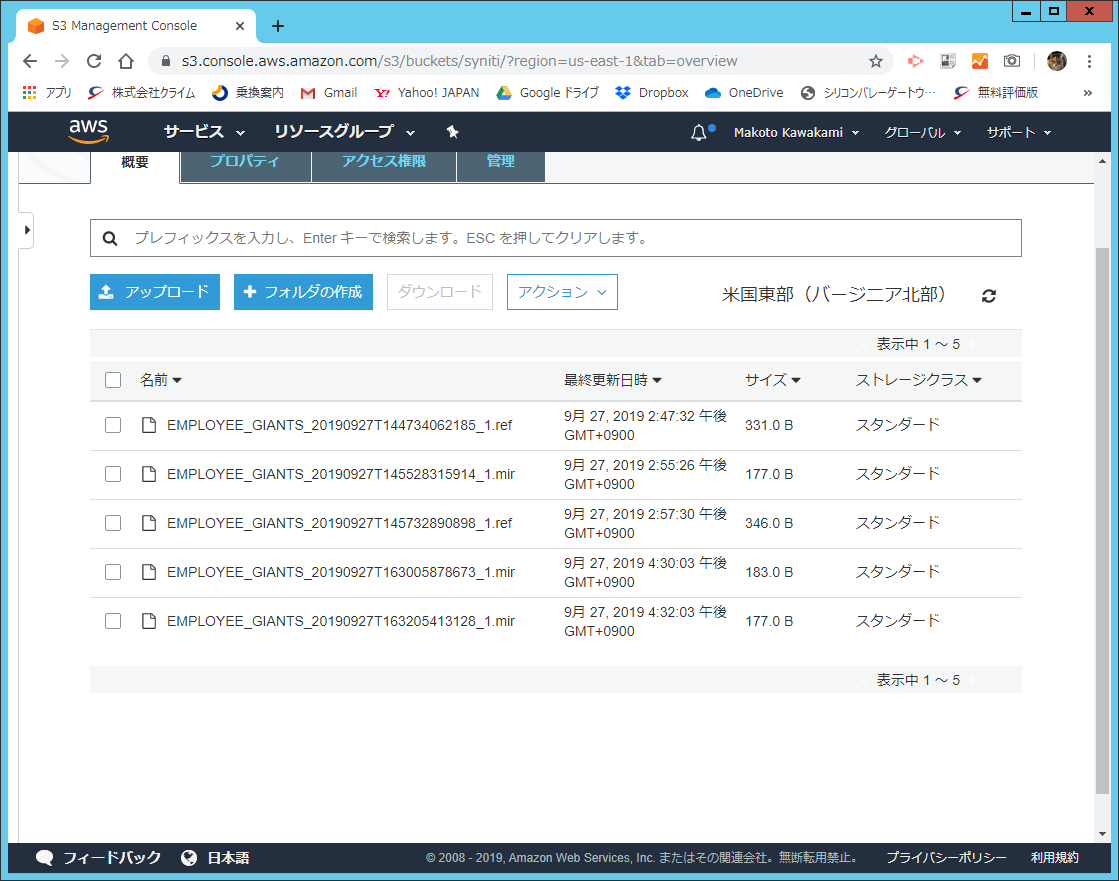
レプリケーションが成功すると、ターゲットのAmazon S3バケット内にフラットファイルが確認できます。
「.ref」という拡張子がついているファイルが初期リフレッシュで生成されたファイル、
「.mir」という拡張子がついているファイルがミラーリングで生成された差分のデータとなります。
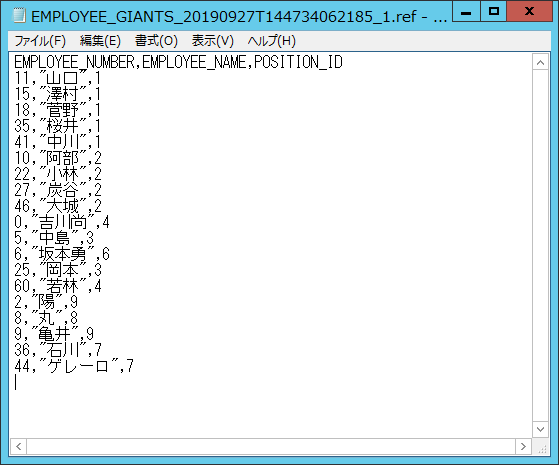
 フラットファイルの中身を確認すると、以下のようにレコードデータが確認できます。
フラットファイルの中身を確認すると、以下のようにレコードデータが確認できます。
- Syniti Data Replicationへの登録
このように、Syniti Data Replicationを使用することで、プログラム開発することなくGUIからの操作のみで、データベースに格納されているテーブルデータをAmazon S3へレプリケーションし、別アプリケーション(BIや分析ツール/サービス)から利用することが可能です。

 RSSフィードを取得する
RSSフィードを取得する


