
AWSのマネージドKubernetesサービスであるEKSは、ハイパースケーラーであるAWSで最も急成長しているプラットフォームの1つです。Snapchat、Adobe、VMwareなどの企業は、Kubernetesコントロールプレーンの管理という運用上の負担をなくすためにEKSを採用し、AWSにアップグレード、パッチ適用、高可用性の処理を任せ、アプリケーション開発に専念しています。しかし、EKSの採用が加速するにつれ、重大なギャップが浮上してきました。
Kubernetesには、ネイティブのエンタープライズ向けバックアップおよび災害復旧機能がありません。当初は些細な運用上の懸念事項だったものが、重要なスケーリングワークロードを実行するエンジニアリングチームにとって、深刻な問題へと発展しています。
これほど急速に普及しているにもかかわらず、Kubernetesのバックアップとリカバリが依然として困難なのはなぜでしょうか?
Kubernetesには、常に変化する構成要素を持つ動的なシステムであること、スケールアップとスケールダウンを繰り返すこと、ボリュームが接続と切断を繰り返すこと、永続ストレージ、Secret、ネットワーク設定などの情報がコンポーネント全体に分散していることの4つの課題が残っています。
Kubernetesの導入は驚異的なスピードで加速しています。一部のレポートによると、企業の約96%が現在このプラットフォームを利用しています。これはクラウド史上最速のサービス導入事例の一つと言えるでしょう。
しかし、Kubernetesのパワーとバックアップの制限間のギャップは停滞したままです。これは、組織がEKSのバックアップチームを大々的に採用し、エラーが発生しやすいCLIを作成する必要なく、プラットフォーム固有の複雑さに対処できるソリューションを待ち望んでいることを意味します。
EKSのバックアップが自動的に処理されないのはなぜですか?
EKSはKubernetesコントロールプレーンの複雑なオーケストレーションを処理しますが、AWSの責任共有フレームワークにより、アプリケーションデータの保護については依然としてユーザーの責任となります。ワーカーノード、それらが実行するワークロード、および関連するすべてのストレージ構成は、保護と可用性の維持のためにユーザーが管理する必要があります。
つまり、クラウドのダウンタイム、単純な設定ミス、サイバー攻撃など、原因を問わず、クラスター内で稼働しているすべてのコンポーネント(運用データベース、コンテンツ管理システム、分析エンジンなど)が破損または削除されるリスクにさらされているということです。
多くの場合、Kubernetesネイティブのバックアップ機能を実現するためにVeleroのようなオープンソースツールに頼っています。Veleroは従来のツールよりもKubernetesリソースをよく理解していますが、運用上のオーバーヘッドは依然として残ります。カスタムリソースの管理、メタデータ用のS3バケットの維持、スケジューリング、監視、障害復旧などを処理するためのコントロールプレーンの構築などが必要です。
現在のバックアップツールがまだ解決できていない主な問題とは?
Kubernetesは、スナップショットを取得できる単なるデータベースではありません。EKSのようなマネージドプラットフォームでは、クラスタの状態はetcdに保存されますが、etcdはAWSによって完全に管理されており、バックアップやリストアのために直接アクセスすることはできません。代わりに、Kubernetes APIを介して再構築する必要がありますが、実際の実行状態は、コンテナ、ボリューム、ネットワークポリシー、カスタムリソースとして数十のノードに分散して存在します。真のバックアップとは、この分散システム全体をある時点において整合性をもってキャプチャすることです。
多くの組織がEKS上でステートフルなワークロード(データベース、WordPressサイト、分析プラットフォーム、社内サービスなど)を実行しています。このような環境では、相互接続された多くの要素を扱うことになります。
- ・コンテナ(多くの場合、ステートフルストレージを含む)を実行するポッド
- ・チームとサービスを分離する名前空間
- ・永続ボリュームと永続ボリュームクレーム
- ・耐久性のあるストレージ(多くの場合、EBSによってバックアップされている)
- ・認証情報やトークンなどの機密設定を保存するシークレット
これらのデータはすべて、アプリケーションコンテナの外部に存在するものの、クラウドストレージと密接に連携しているEBSボリュームに格納されることが多いです。リソースは非常に動的であり、ポッドやノードは必要に応じて常に状態が変化し、スケールアップとスケールダウンを繰り返します。
このような分散アーキテクチャの特性上、小さな予期せぬクラスタ障害が連鎖的に大規模な本番環境の停止につながる可能性があります。企業は手動によるリカバリプロセスやエラーが発生しやすいスクリプトに頼ることはできません。
実際にEKSクラスターのバックアップを取っているのは?
ここ数ヶ月、N2WSのEKS開発チームは、EKSバックアップのバックエンドを深く掘り下げ、EKSクラスターのバックアップはkubectl get podsや簡単なVeleroの実装では行えないと理解しました。
これはCRD、ポーリングループ、スナップショット検証、再試行、エッジケースなどを含む複雑なプロセスです。さらに、本番環境レベルのEKSバックアップシステムをレビューした際に、どのリソースがバックアップされていないのかを確認しました。
EKSバックアップシステムの構築から得られた5つの重要な教訓
1.EKSのバックアップは「単一作業」ではない
根本的には、多くの異なるシステムを同時に調整する必要のある、オーケストレーションの問題があります。
- ・AWS EKS API(クラスターの状態、認証情報、リージョン)
- ・Kubernetes API(CRD、名前空間、RBAC)
- ・Veleroカスタムリソース(バックアップ、リストア、バックアップリクエストの削除)
- ・メタデータ用のS3
- ・データ用のEBSスナップショット
- ・何がいつ、なぜ起こったのかを追跡する独自のシステム
Veleroは強力なツールではありますが、完全な制御プレーンというよりはあくまでもツールとして機能します。組織は包括的なバックアップ戦略を管理するために、これらのコンポーネントを連携させる必要があります。
2.バックアップユニットは必ずしもクラスタとは限らない
場合によってはバックアップユニットが、以下のようになります。
- ・クラスター全体(システム名前空間を除く)
- ・個別の名前空間
- 時には両方がバックアップユニットとなりますが、重複したバックアップを避けるために、慎重な調整とスクリプト作成が不可欠です。
つまり、名前空間の重複排除が非常に重要になり、同様にバックアップすべきでないものをいつバックアップすべきかを判断することも重要になります。EKSバックアップツールは、重複したバックアップを回避する必要があります。
3.Veleroのバックアッププロセス
Veleroのバックアップは、以下のようないくつかのフェイズを経て進行します。
- ・New
- ・InProgress
- ・WaitingForPluginOperations
- ・Unknown (fun one)
- ・Completed
- ・PartiallyFailed
- ・Failed
Veleroのステータスが「Completed」であっても、バックアップが完全に成功したとは限りません。EBSスナップショットが存在し、アクセス可能であることを確認する必要があります。そのためには、AWS APIにクエリを実行してスナップショットの状態を個別に検証する追加の手順が必要です。
4.メタデータ vs. データ:EKSはストレージメカニズムを全く異なる方法で扱います
- ・Kubernetesマニフェスト → S3に保存
- ・ボリュームデータ → EBSスナップショットにキャプチャ
- ・実行ステータス → メモリ内に保持
- ・監査可能性 → 監査ログはデータベースに保存
構成、データ、運用履歴の間に明確な境界を維持するため、これらのストレージモデルには意図的に違いがあります。これらの違いがなければ、トラブルシューティングはほぼ不可能になります。
5.リトライ処理は必須です
現実では、以下のような事象が発生する可能性があります:
- ・クラスターが消える
- ・フェーズは不明
- ・スナップショットは部分的に成功する
運用環境に構築されたシステムは、上記のような不安定性を想定し、即座に対応する必要があります。つまり、システムは、
- ・ロジックのリトライをしなくてはならない
- ・部分的な成功処理を実装しなくてはならない
- ・「このバックアップで十分だ」と判断する能力
- ・修復不能な状態である場合に、即座にエラーを返す(Fail Fast)
まとめ
Kubernetesのバックアップは、単一の機能ではなく、システム全体を保護します。つまり、Veleroのようなバックアップエンジンを提供するツールは存在し、一方でAWSは基盤となる基本要素を提供します。しかし、これらのプラットフォームはいずれも、綿密なシステム設計の必要性をなくすものではありません。Kubernetes向けのプロダクショングレードのバックアップソリューションには、以下の要素が必要です。
- ・定義されたポリシーモデル
- ・信頼性の高い実行フロー
- ・強力なシステムステータス追跡機能(実際に何が起こったかを常に把握するため)
- ・直感的なエラー処理(物事がうまくいかない様々な状況に対処するため)
- ・不確実性や部分的な結果を隠蔽するのではなく、ユーザーとコミュニケーションをとるリカバリ体験
N2WSによる信頼性の高いEKS保護
N2WSは、Kubernetesの複雑さに特化して設計されたポリシーベースのワンクリックバックアップおよびリカバリ機能を提供します。単一のコンソールで、KubernetesワークロードとRDSデータベースなどの外部AWSサービスの両方にまたがるアプリケーションスタック全体を、単一のポリシーでバックアップおよびリカバリできます。つまり、RDSバックエンドを備えたEKS上で動作するWordPressアプリケーションは、個別のコンポーネントとしてではなく、一つのユニットとして保護およびリストアできます。
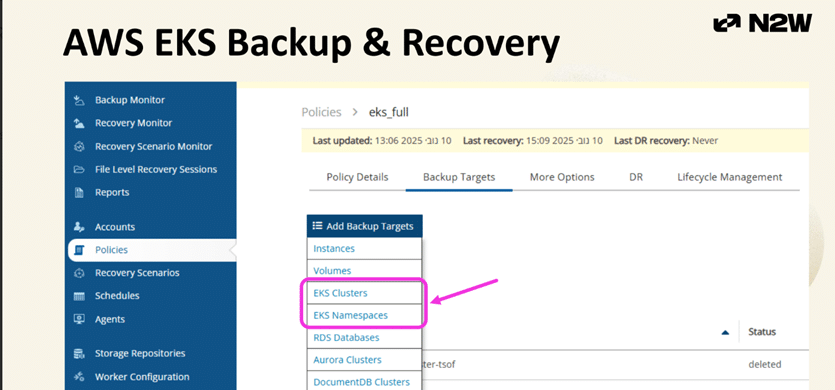
N2WSは以下をバックアップします:
- ・EKSクラスター全体
- ・すべての名前空間
- ・クラスタスコープのリソース
- ・永続ボリュームのEBSスナップショット= Kubernetesマニフェスト(S3へ)
N2Wは即座に以下へ復旧できます:
- 同じクラスターへ
- クラスター間における重要な災害復旧機能を提供する別のクラスターへ

N2WSにご興味ございましたら、ぜひクライムまでお問い合わせください。
関連トピックス
- Kasten K10 における Kubernetes のバックアップ、リカバリ、モビリティの扱い方法 (Kubernetesにおけるデータ保護)
- Zerto for Kubernetes(Z4K)、K8s環境をレプリケーション:ZertoCON 2021
- Azure Kubernetes Serviceのバックアップとリカバリは Kasten K10で
- ホワイトペーパー: Kubernetesバックアップの5大ベストプラクティス (コンテナ ネイティブ環境のデータ管理ニーズに応える)
- VeeamでOpenShift Virtualizationの仮想マシンをバックアップ?
- VMwareとKasten:Kubernetesと先端アプリケーションのためのデータ管理
- VeeamとKastenのパートナーシップが実現
- Kubernetesのマルチクラスタについて
- N2W Software社、Kubernetes(Amazon EKS)向け次世代自動バックアップ&復旧(リカバリ): Ver4.5を発表
- Kubernetesへの移行を成功させるには(続き)










 RSSフィードを取得する
RSSフィードを取得する
