
AIモデルの長期的な成功は、そのモデルを駆動するデータの品質に直接的に依存しています。AIデータパイプライン全体において、ワークロードの強度やデータの種類は多様化し、オブジェクトのサイズも変動します。AIデータパイプライン全体でデータを効率的に管理することは、AIイニシアチブがコスト効果的で技術的に実現可能であることを確保するために不可欠です。各ステップで最適なストレージを選択することで、組織はAIプロジェクトを長期的な成功に導くための最適なポジションを確立できます。
AIデータパイプラインとは?
AIデータパイプラインは、AI駆動型のユースケースを支援するために、テクノロジースタック内でデータが移動するフレームワークです。これには、AIモデルのトレーニングと運用にデータを提供するために使用されるツールとプロセスが含まれます。このパイプラインは通常、それぞれ異なるストレージ要件を持つ6つのフェーズから構成されます:
- アーカイブ
- ロー(生)データの取り込み
- データの前処理
- トレーニング
- 微調整
- 推論/展開
各フェーズでは、データ量、アクセスパターン、パフォーマンス要件が異なります。したがって、パイプラインの各フェーズに最も適したストレージタイプを選択することが適切です。 次のセクションでは、異なるパイプラインフェーズをレビューし、各フェーズに最適なストレージの簡単な概要を提供します。
AIデータパイプラインの各フェーズにはどのようなストレージが必要ですか?
1. ローデータ (raw data)の取り込み: 多数のソースから収集された大量のデータが、AIワークフローに供給され、その基盤となるデータとして活用されます。
理由: このフェーズのデータは、画像、動画、センサー出力、テキストなど、半構造化データと構造化データの両方を含むため、ペタバイト規模のデータが生成されます。オブジェクトストレージは、大規模な非構造化データをコスト効率よく処理できるため、このフェーズに最適です。また、並列データ取り込みをサポートし、下流プロセス用のデータ前処理ツールとの統合性も高いです。
ストレージ容量: 大容量
ストレージの種類: オブジェクトストレージ
2. データ準備: ローデータはクリーニング、ラベル付けされ、モデルトレーニングに使用される形式に変換されます。
理由: このステップでは、頻繁なデータ読み書きと低遅延が要求されるため、高性能ファイルストレージが最適です。データ容量は通常、フェーズ1で取り込んだデータのサブセットですが、アクセスパターンが密集しているため、オブジェクトストレージが通常提供するよりも高速な入出力(I/O)が必要です。
ストレージ容量: 中
ストレージの種類: 高性能ファイルストレージ
3. トレーニング: データセットを処理して、パターンを認識し予測を行う機械学習モデルを開発します。
理由: トレーニングデータは、通常、 ローデータの一部であり、高頻度かつ高速でアクセスする必要があります。GPU クラスターやアクセラレーターは高速な I/O を必要とするため、高性能ファイルストレージまたはインメモリストレージソリューション(並列読み取りをサポートするもの)が最適です。
ストレージ容量: 中
ストレージの種類: 高性能ファイルストレージまたはインメモリストレージ。インメモリストレージは、デバイスのメインメモリ(RAM)にデータを格納し、データ処理を高速化します。この技術は、データをディスクドライブに格納する従来のデータストレージ手法とは対照的です。
4. ファインチューニング(微調整): これは、前工程で訓練されたモデルを特定のタスクやデータセットに適応させ、その性能を向上させ、特定のユースケースに最適化するプロセスです。
理由: ファインチューニングはリソース集約的なプロセスであり、低遅延、高スループット、およびデータへの高速アクセスが要求されるため、インメモリ/CPUまたはGPU、または高性能ファイルストレージを使用すべきです。新しい入力データはオブジェクトストレージ( ローデータ)からファインチューニングのストレージ先へ配信可能です。
ストレージ容量: 小
ストレージの種類: 高性能ファイルストレージまたはインメモリストレージ
5. 推論/展開: 最終化されたAI/MLモデルは、アプリケーションやエンドユーザーがアクセスして利用可能な生産環境に統合されます。
理由: 展開時、モデルは生産環境で使用可能となり、モデルファイルと参照データへの可能な限り高速なアクセスが求められる場合があります。データをインメモリ/CPUまたはGPUに格納することで、遅延を最小限に抑え、高速なリアルタイム予測と応答性の高いユーザー体験を実現します。
ストレージ容量: 中
ストレージの種類: インメモリ/CPUまたはGPU
6. アーカイブ: 古いデータセット、モデル、プロンプト出力、およびログデータは、長期保存、コンプライアンス、または将来の再トレーニングの必要性に備えて保存されます。
理由: オブジェクトストレージはアーカイブデータに最適なソリューションであり、長期保存、スケーラブル、コスト効率に優れ、安全なストレージを提供し、必要な際にアーカイブされたコンテンツを容易にアクセス可能に保ちます。
ストレージ容量: 大容量
ストレージの種類: オブジェクトストレージ
クラウドオブジェクトストレージがAIワークフローの経済性とスケーラビリティを向上させる方法
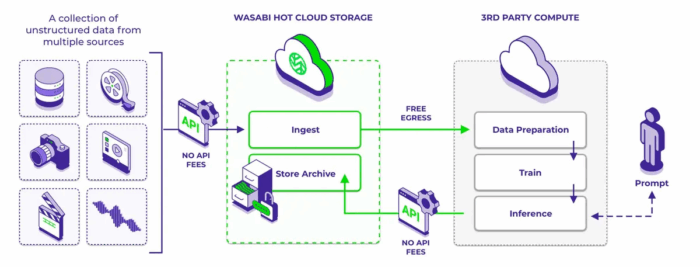
AIデータパイプラインの特定のフェーズ(データ準備、トレーニング、生産など)では高性能なストレージが不可欠です。しかし、AIワークフローのすべてのデータをこれらのプレミアムストレージ層に保存することは、多くの場合不要で高コストかつ持続不可能です。 クラウドオブジェクトストレージは、AIデータパイプラインの複数のフェーズの要件とよく一致する、スケーラブルで経済的な代替ソリューションを提供します。
オブジェクトストレージは、生データの取り込みとアーカイブの出力の両方で大規模なデータ容量に対応するのに特に適しています。この ローデータは、モデル訓練や微調整時に新しい入力データとしてアクセスすることも可能です。これらの段階では、超低遅延や継続的な読み書き活動が不要な大規模なデータ量が処理されるため、コスト効率とスケーラビリティが重要です。オブジェクトストレージは、これらのフェーズで利用される AI インフラストラクチャツール(クラウドベースのコンピューティングサービスなど)とシームレスに統合可能です。
ただし、すべてのクラウドオブジェクトストレージソリューションが同じように作られているわけではありません。多くのプロバイダーは、読み取り、書き込み、データ転送(エグレス)などのデータアクセス料金を課しています。これにより、特にAIワークロードにおいてデータが頻繁に再利用または再処理される場合、予測不能で大きなコストが発生する可能性があります。Wasabi Hot Cloud Storageは、転送料金やAPIリクエスト料金のない「予測可能な料金体系」により、これらの制限を解消し、組織がAI予算を管理しやすくします。これは、再トレーニングやリアルタイム推論のような反復的なワークフローにおいて、データへの頻繁なアクセスが不可避な場合に特に重要です。
さらに、アーカイブなどの段階では、コールドストレージのようなオプションを検討する組織もあります。しかし、AIシステムはモデル更新のために継続的なデータアクセスに依存するため、コールドストレージからデータを取得する時間とコストを考慮すると、これは適切な選択ではありません。コストやパフォーマンスを犠牲にせずに即時アクセスを維持できるオブジェクトストレージプラットフォームを選択することは、AIオペレーションの持続とスケールアップの鍵となります。
AIデータパイプラインの構築で成功を収める
成功かつスケーラブルなAI戦略を構築するためには、組織はAIデータパイプラインの各段階を支えるツールとインフラストラクチャを慎重に評価する必要があります。AIワークフローは継続的にデータを生成し再利用するため、高性能であるだけでなく、コスト効率が高く、長期にわたって持続可能なソリューションが求められます。堅固なストレージ基盤を構築することは、AIの取り組みが長期的な価値を生み出し、一時的な実験に終わらないようにするための鍵となります。









 RSSフィードを取得する
RSSフィードを取得する
