

CloudBerry Backupは膨大なデータを難なく処理しますが、そのためのインターネット接続の可用性にまったく不安がないというわけではありません。当然ながら、数十テラバイト(あるいはそれ以下でも)のデータのアップロードには、高速通信の帯域幅をもってしても相当に時間がかかるわけで、標準以下の接続の場合は言うまでもありません。しかも、インターネットプロバイダの多くはユーザーに通信データ量の制限を課すため、数テラバイト以上のデータのアップロードは決して容易ではありません。この問題には他の解決策を考えたほうが合理的です。
ありがたいことに、Amazonではとても便利で整然とした解決策を提供してくれております。Amazon Snowballというサービスです。それは端的に言えば、80TBまでデータを保存できる巨大ボックスです。

その仕組みはいたってシンプルで、簡単に言えば、Amazonにボックスをリクエストし、それにデータをアップロードしてAmazonに送り返し、あとは、Amazonのデータストレージの割り当てられた部分にそのデータがアップロードされるのを待つだけです。単純明快なプロセスです。もちろん、細かな技術的な課題はところどころありますが、相対的に簡単な作業です。Amazon Snowballに関する詳細は下記サイトをご参照ください。
https://aws.amazon.com/snowball/
Amazon Snowballの概要がわかったところで、ここからはCloudBerry Backupがそのプロセスにどのように機能するのかについて述べます。ボックスの手配や発送はAmazonを通じて行われますが、ローカルマシンからSnowballへのデータ送信は、バックアップソフトウェアを利用して行われます。つまり、通常のバックアップ処理同様、バックアッププランを作成し、データの送信先がクラウドストレージではなくSnowballになるだけです。そのようなプランの設定方法や、諸々の手順を、以下に説明します。
データの送信には、それに適したマシンを使用することが重要になります。それにより、処理やメモリー、ネットワーキングの要件に対応可能となります。ワークステーションの仕様については、下記サイトをご参照ください。
http://docs.aws.amazon.com/snowball/latest/ug/specifications.html#workstationspecs
ジョブの作成
プロセスの全体像が把握できたら、Snowballを発注しましょう。Amazon Web Servicesのサイトにアクセスしてください(必ず、正しい地域を選択してください)。そこでは、いわゆるインポートまたはエクスポートのジョブを作成することができます。
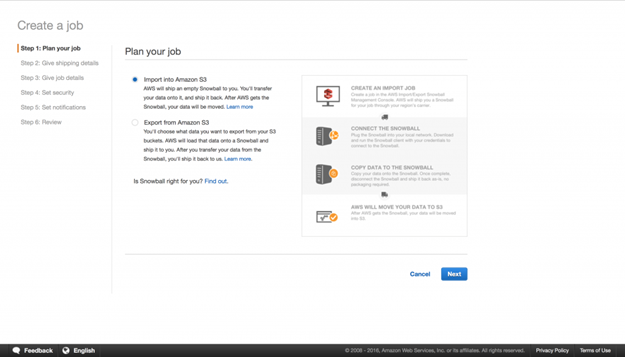
次に住所を記入し、Shipping speed(配達期間)を選択します。
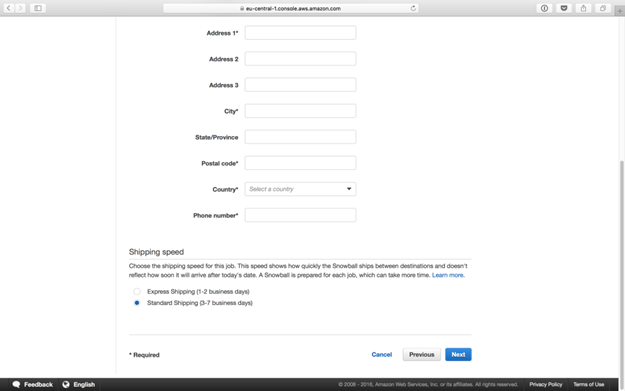
そして、ジョブの詳細を記入します。ジョブ名、バケット、Snowball容量を指定できます。すべて記入したら、Nextをクリックします。
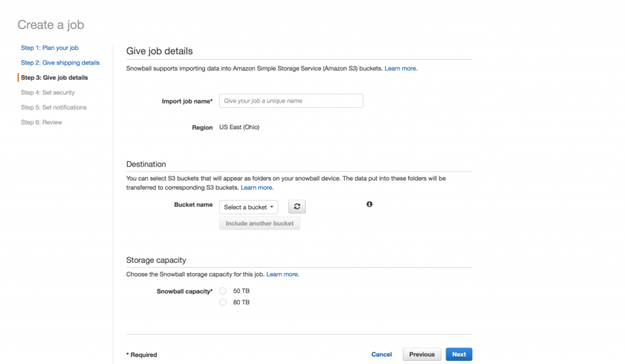
ステップ4では、セキュリティの詳細を設定します。
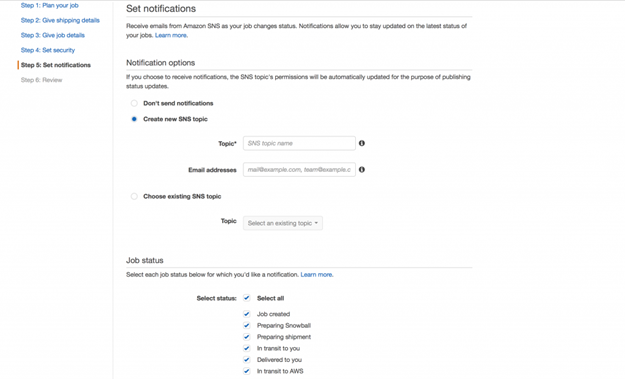
次に、通知の条件をニーズに合わせて調整することができます。
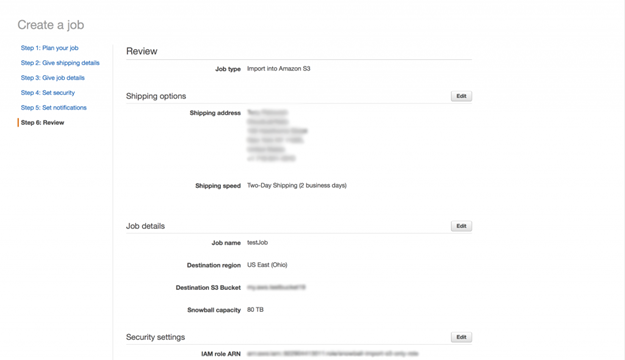
最後に忘れてならないのが、確認作業です。すべての情報に間違いがないかどうか慎重に確認し、問題がなければCreate jobをクリックします。
ジョブを作成したら、あとはボックスの到着を待ちます。ボックスが届いたら、データのバックアップが開始できます。
CloudBerry BackupとSnowballの連携
バックアップのプロセスを段階を追って記述すると下記のようになります。
-
Snowballを電源につなぎ、コンピュータに接続します。任意でカスタムIPアドレスも設定できます。
-
CloudBerry Backupにバックアッププランを作成します。これは通常のプロセスと本質的に変わりありません。初期バックアップにAWS Snowballを使用する点だけが特別です。
-
いわゆるS3アダプタをダウンロードしてから、それを起動し、CloudBerry Backupがボックスと連携できるようにします(AWS Snowballは独自のファイル管理システムを持ちます)。
-
バックアップを完了させ、ボックスをAmazonに送り返します。ボックスに保存されたデータが、指定のAWSバケットに移されたら、CloudBerry Backupを起動し、データがクラウドに保存されていることを認知させます。それにより、以後のバックアッププロセスでクラウドのバックアップデータが使用されます。
プロセスは以上の通りで、いたって単純であり、数分で設定可能です。では、さらに詳しい手順を、ステップごとに見て行きましょう。
ボックスの設定
まず、電源の入っていないボックスをコンピュータに接続します。方法は数通りあります。Snowballをローカルネットワークに接続する方法の詳細は、下記サイトを参照してください。
http://docs.aws.amazon.com/snowball/latest/ug/getting-started-connect.html
ボックスの電源を入れると、そのE-inkスクリーンに下記の情報が表示されます。
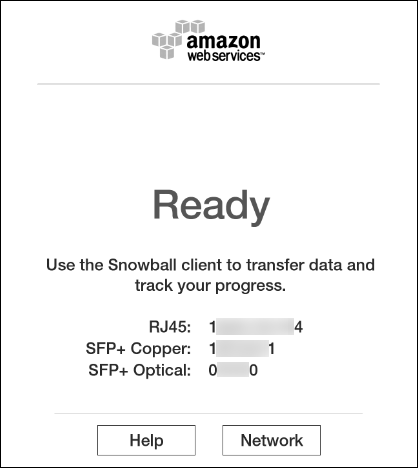
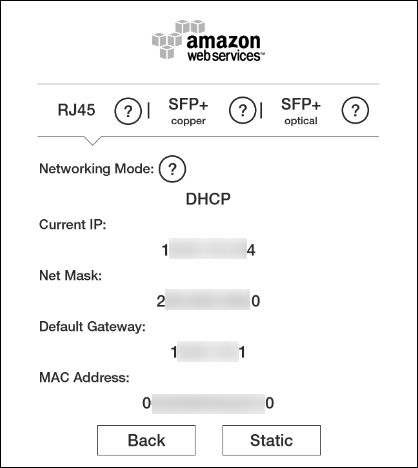
Snowballは自動的にIPアドレスを取得します。Networkボタンをクリックすると、IPアドレスが表示されます。ネットワーク設定は手動で変更することもできます。詳細は前述の記事をご参照ください。
バックアッププランの作成
プラン作成の前に、クラウドストレージ設定を開き、Amazonのジョブ作成で指定したバケットと同じバケットが選択されていることを確認してください。
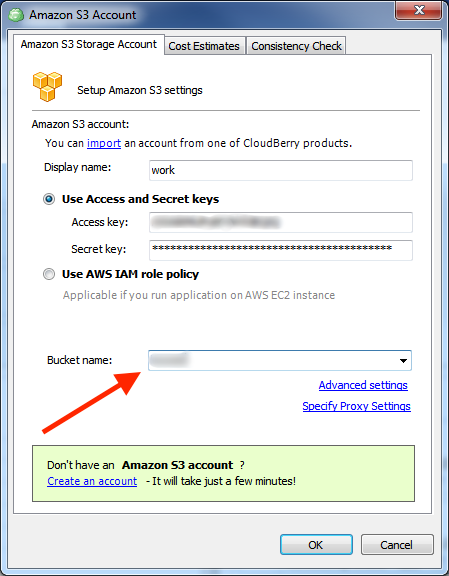
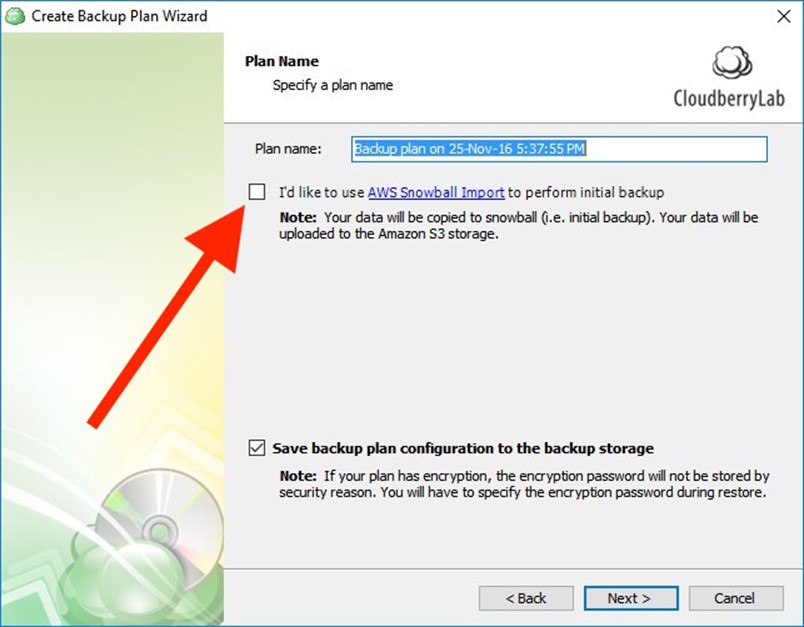
次に、バックアッププランの作成に進みます。通常の手順にしたがって作成してください。プラン名指定時にI’d like to use AWS Snowball feature to make initial backupのチェックボックスを選択してください。
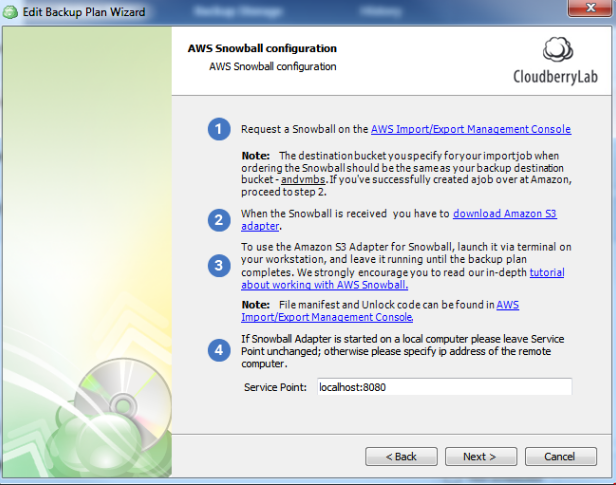
プランの設定を続行します。ほどなくAWS Snowballの設定ステップに進み、そこでさらに詳しい手順が示されます。②のリンクをクリックしてAmazon S3アダプタをダウンロードしてください。
ダウンロードが完了したら、ファイルを解凍し、コマンドウィンドウを起動します。Amazon S3アダプタを含むフォルダを指定し、下記のコマンドを実行します。
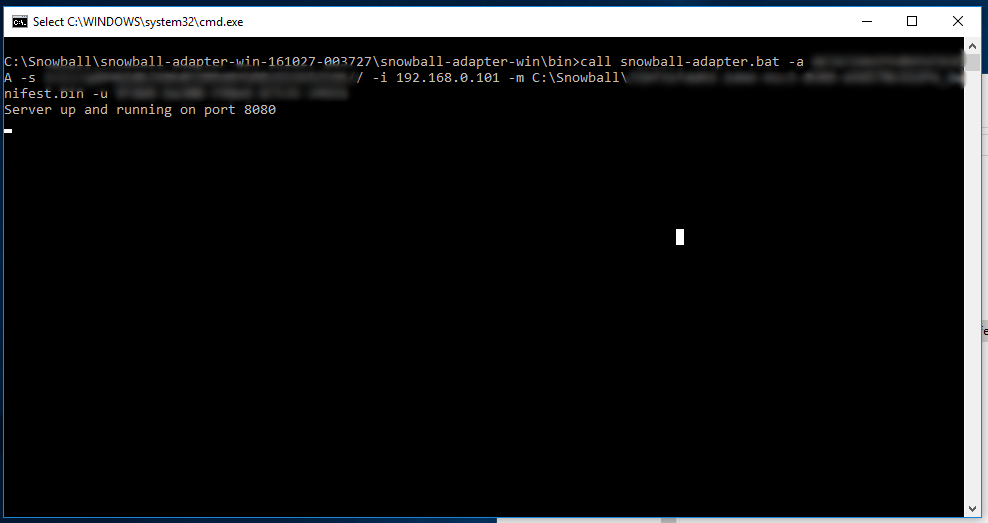
上記において、使用可能なコマンドライン引数は以下の通りです。
-
-a アクセスキー
-
-s セキュリティキー
-
-I IPアドレス(ボックスで参照可)
-
-m マニフェストファイルへのパス(下図の通り、AWSコンソールで参照可能)
-
-u アンロックコードへのパス(下図の通り、AWSコンソールで参照可能)
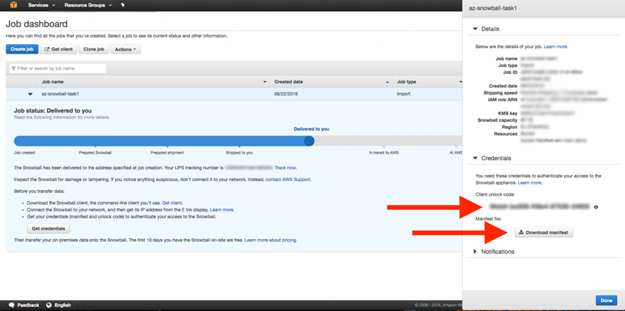
すべて適正にセットされれば、端末に下記のようなメッセージが表示されます。
“Server up and running on port 8080”
ここでは、まだコマンドプロンプトを閉じないでください。プロセスを通じてコマンドは継続的に実行されます。CloudBerry Backupに戻り、バックアッププランの設定を完了します。そして、バックアッププランを実行します。
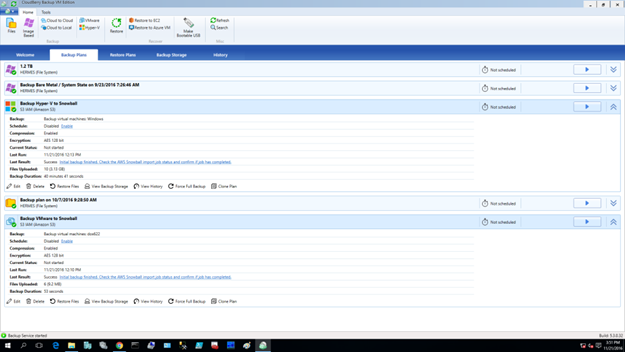
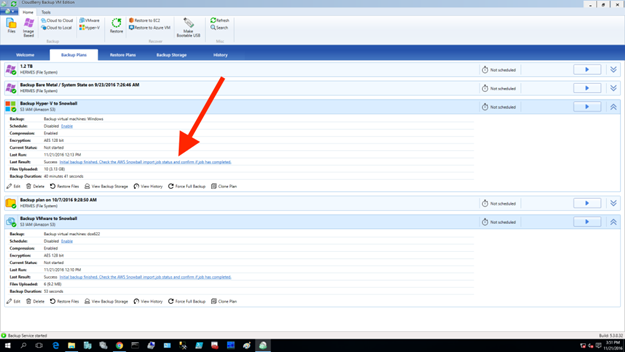
以上により、データが無事AWS Snowballに移されたら、ボックスをAmazonに送り返します。その後、データが指定のバケットに移された旨、Amazonから通知があり次第、CloudBerry Backupでそれを確認することができます。そして、Initial backup finished…のリンクをクリックします。
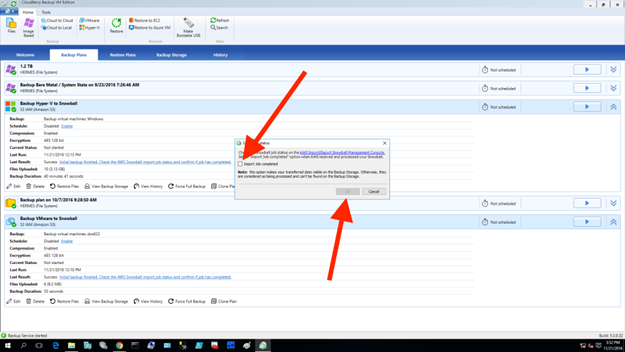
Import Job Completedのチェックボックスを選択し、OKをクリックします。
ここで注意したいのは、クラウドに送られたファイルは名前が変更されている点です。これはCloudBerry Backupの特性とファイル構造との相互作用に起因します。
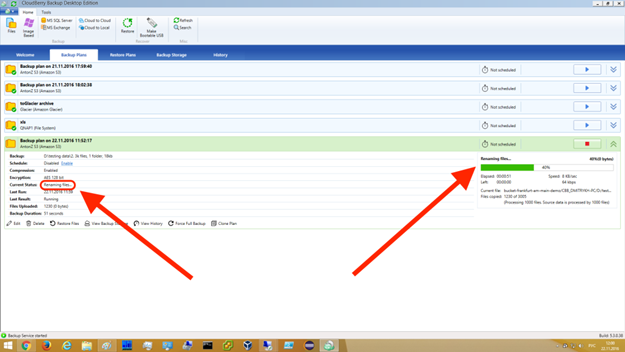
以上で、初期バックアップがAWS Snowballの力を借りて無事完了しました。これ以降のバックアップはローカルコンピューターからクラウドへ、CloudBerry Backupによって通常通り行われます。
注:クラウドにおいてファイル名がすべて変更されるまで、リポジトリを同期化しないでください。予期せぬ不具合が生じる可能性があります。
無料トライアル版
以上が、Amazon Snowballとの連携方法です。CloudBerry Backupの15日無料トライアル版をダウンロードし、是非このバックアップソリューションをお試しください。お申込みサイト









 RSSフィードを取得する
RSSフィードを取得する

東京リージョンでSnowballの利用が開始されました。
http://ascii.jp/elem/000/001/551/1551767/