
前回、ご紹介した通りELTアーキテクチャでは従来のETLとは異なり、データベースやデータウェアハウス上でTransformation変換を行うことで効率的な処理を実現しています。
しかし、データベース上で処理を行うということはそれぞれのデータベースの特性に合わせてコードを実装する必要があるということです。従来のETLツールではブラックボックスとなっている専用の変換エンジンで行われていたことを、データベース上で実行するために1から10までコーディングしていく必要が有ります。
このような方法では、処理を効率化できたとしても開発に時間がかかりすぎてしまいます。この問題を解決するために、ELTなプロセスを開発することに特化したStambiaでは各データベースやデータウェアハウス上で効率的な処理を実装できるコネクタやテンプレートを豊富に用意し、GUIから対応付けや実施したい処理をプロジェクトに合わせてデザインするだけでコードを自動生成できます。
連携可能なテクノロジ(データソース)一覧
|
|
|
標準的なものとしては各データベース、データウェアハウスごとに以下のような機能を提供するテンプレートを用意しています。
標準機能※ファイルなどの一部テクノロジに関してはサポートしていない機能があります。
| 機能 | 概要 |
| リバース(データ接続) | データベースの構造に合わせた専用のメタデータでの接続 |
| DDL /DML 操作 | Insert, Update, Select, Delete, Create, DropといったDML/DDL操作をデータベース上で実行 |
| 統合処理 |
|
| ステージング | データ変換、相互化などを行うためにデータベースをステージング領域として使用
|
| リジェクト(除外) | 除外ルール定義し、統合の要件に満たないまたは除外するデータを検出
|
| レプリケーション | データベースの複製のサポート |
このような基本的な処理を行うためのテンプレート以外にも、それぞれのテクノロジに合わせた拡張機能用のテンプレートも用意されています。
拡張機能(例:Oracle)
| 機能 | 概要 |
| 低速変更ディメンション 統合(SCD: Slowly Changing Dimension Integrations) | SCDを使用し統合を実施 |
| ロード方式 |
|
| テーブルの分析 | 統合時にデータのロードを最適化するために、ANALYZE TABLEまたはDBMS_STATS.GATHER_TABLE_STATSを使用してワーキングテーブルおよびターゲットテーブルを分析 |
| 変更データキャプチャ(CDC) | CDCによりテーブル上の全ての変更を追跡し、保存 |
拡張機能(例:Azure SQL Database)
| 機能 | 概要 |
| 低速変更ディメンション 統合(SCD: Slowly Changing Dimension Integrations) | SCDを使用し統合を実施 |
| ロード方式 |
|
| 変更データキャプチャ(CDC) | CDCによりテーブル上の全ての変更を追跡し、保存 |
拡張機能(例:Hadoop Hive)
| 機能 | 概要 |
| 統合方式 |
|
他にもAmazon Redshiftの場合にはS3バケットを介したデータのロード、SAP HANAの場合にはINPORT FROM、リモートソースを介したデータのロードなどそれぞれのデータベースの機能を活かしてデータ統合が可能です。
テンプレートの利用方法
このように大量のテンプレートがあるとそれを使いこなせるか心配されるかと思います。どのテンプレートを使用するのが良いのか、データベースごとにテンプレートを自分で選ばなければいけないのかといった点です。しかしStambiaで開発を行うのであればそのような心配は無用です。登録したデータソース(メタデータ)をドラックアンドドロップし、データの対応付けであるマッピングを作成するとそのマッピングでデータ統合を行うために必要なテンプレートが自動的に選択されます。また、このテンプレートには処理を行う際に指定可能なオプションがあらかじめ用意されており、Distinctで重複を排除するなどの指定も可能です。
マッピング例:
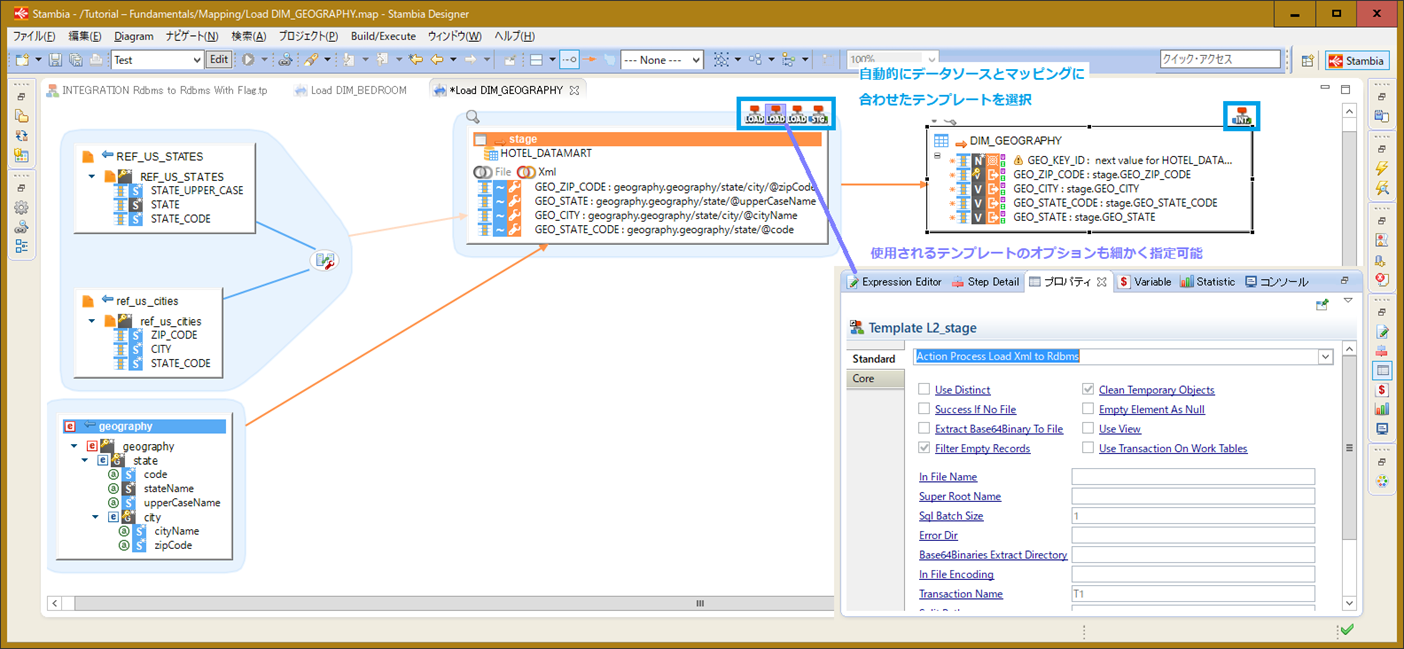
このように、簡単に利用できるテンプレートですが、テンプレート内で行われている処理はブラックボックス化されていません。専用のエンジンを用いるETLツールですと、用意されたものでしか処理が行えないというケースもありますが、Stambiaのテンプレートはユーザが自身で変更することも可能です。これによりテンプレート内の一部の処理のみを変更し、環境やデータ統合プロジェクトに合わせてカスタマイズすることもできます。
テンプレートプロセス例(XML to RDBMSのロード処理)
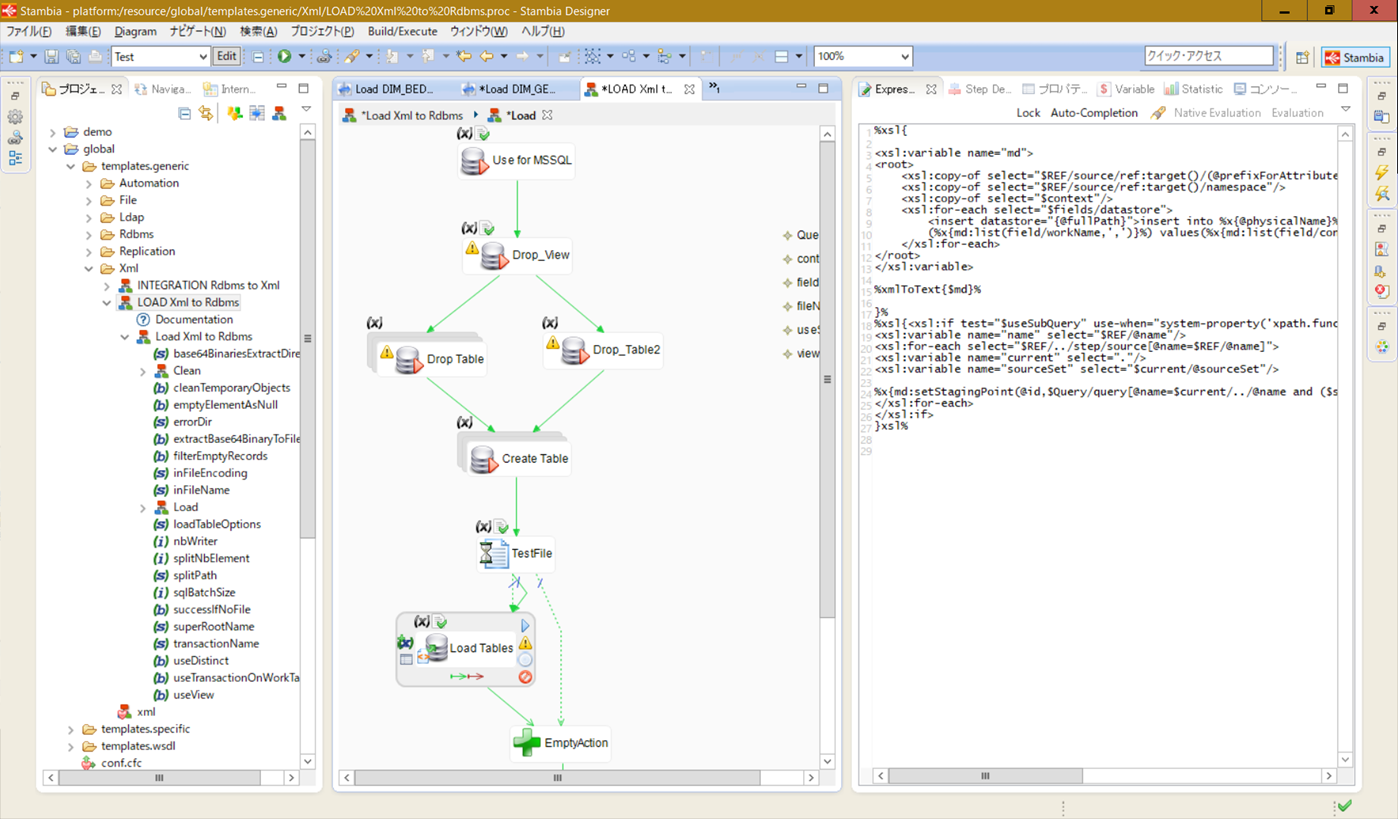
また、作成したマッピングを組み合わせて一連のプロセスとすることも当然可能です。プロセスはマッピング実行順序を指定するだけではなく、スクリプトやファイル、Eメール操作などと組み合わせることもできますので他のアプリケーションなどと連携して処理も簡単に構成できます。
データ統合プロセス例
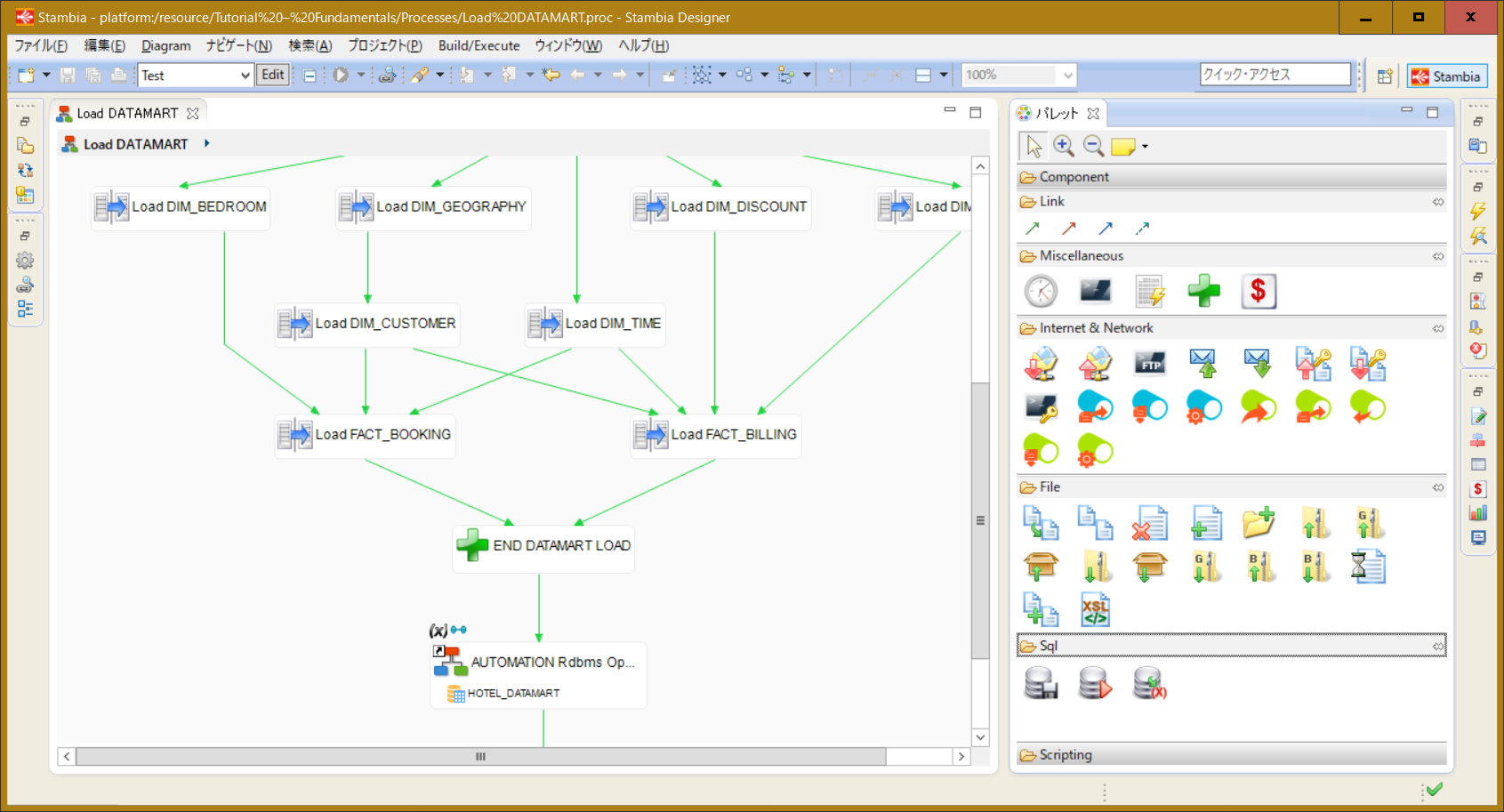
さらに、作成したプロセスをテンプレートとして使用することも可能です。これにより毎回のプロジェクトを0から開発する必要はなく、過去に作成したマッピングやプロセスを最大限活用して、開発にかかる手間と時間を短縮できるため、Stambiaは使えば使うほどより便利に、より効率的に開発を行えるようになるツールです。
関連したトピックス
- ビッグデータ分析のためのデータウェアハウスAmazon Redshiftの特長と利点
- StambiaのSalesforceとの接続ツール: Open Connector for Salesforce
- Syniti Data Replication 新機能ブログ③ Hadoop HDFSへのレプリケーション対応強化
- Stambia Component for SAP:SAPでの異なるデータ統合のユーザ使用例
- Stambia Component for SAPの機能紹介
- StambiaでIBM iのデータをAmazon Web Service S3へ簡単プッシュ!!
- Salesforceとのデータ統合:6つの利点 [Stambia]
- SAP HANAで空間(Spatial)データサイエンスを強化する仕組み
- Amazon Redshiftに対してOracle、AS/400、SQL Server、MySQLなどからデータをリアルタイムにレプリケーション[DBMoto]
- Oracle Data Integrator ― マイグレーションに関する4つの課題と Stambiaがもたらす解決策

 RSSフィードを取得する
RSSフィードを取得する

