
昨今では様々なBI・分析ツールやサービスが展開されており、企業のこれからの成長戦略や方針を決めるためにデータ分析は不可欠なものとなってきています。
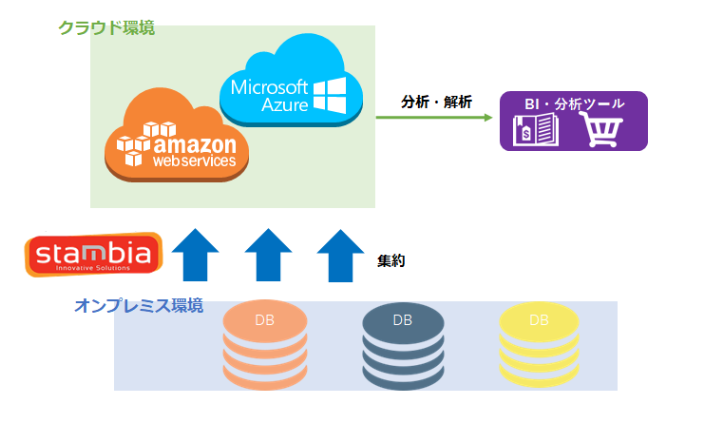
実際にデータを分析する際に、必要なデータと不必要なデータを仕分けし、更にデータをクリーニング、変換することはデータソースが1つだけであればマンパワーで対応できるかもしれませんが、以下の図のようにデータソースが混在している環境の場合、変換や集約、クリーニングには大きな手間がかかります。
さらに、これが各地、各拠点ごとに異なっている場合、マンパワーだけで対応するのは大きな負荷となります。
クライム取扱製品の1つであるStambiaは、この記事のように様々なデータソースに対応しており、
すべてのデータソースを、同一のGUIから管理することができます。
また、各データソース上にて変換処理を実施することで、従来のETLツールより効率的にデータ処理を実現できます。
本ブログでは、IBM iからデータを収集しファイルとして保持し、データをAmazon Web Service S3へプッシュする方法をご紹介します。
Amazon S3の登録
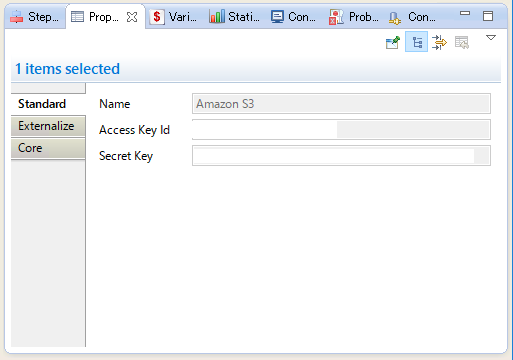
まず、StambiaからAmazon S3へデータをプッシュするために、StambiaマシンへAmazon S3を登録する必要があります。
Amazon S3へ接続するためには、Stambiaポータルサイトより、Amazon Templeteをダウンロードすることで、メタデータ登録時にAmazon S3を選択することができます。
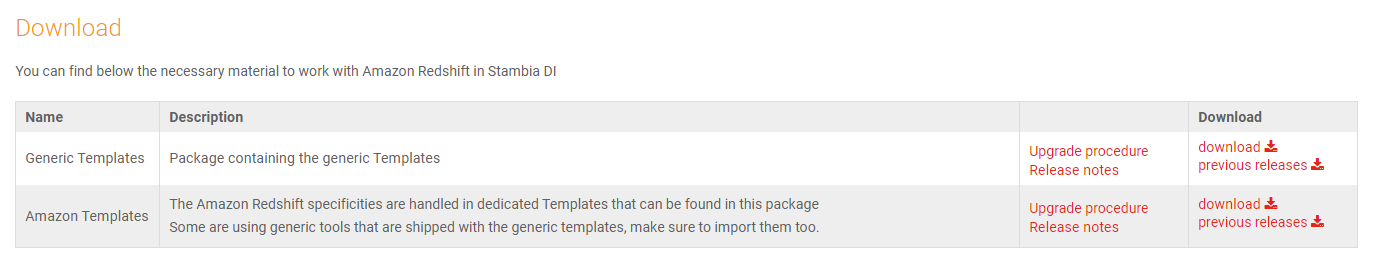
上の図にあるAmazon Templeteをダウンロードし、Stambiaへ取り込むことで、メタデータ登録時にAmazon S3を選択することができます。
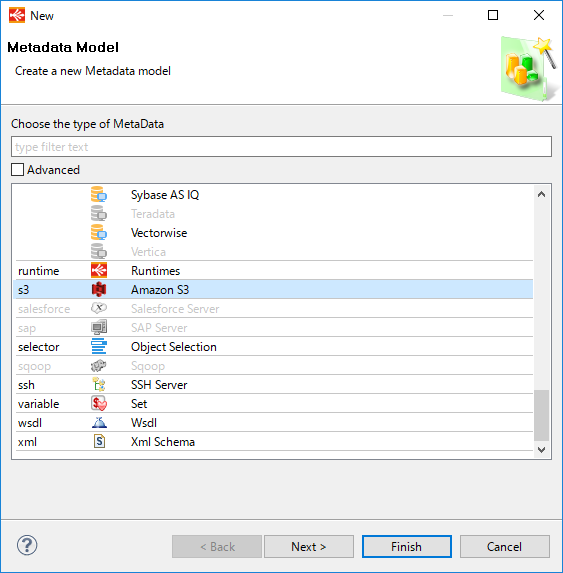
アクセスキーとシークレットキーを指定することで、Amazon S3の登録は完了です。
ファイルとしての収集
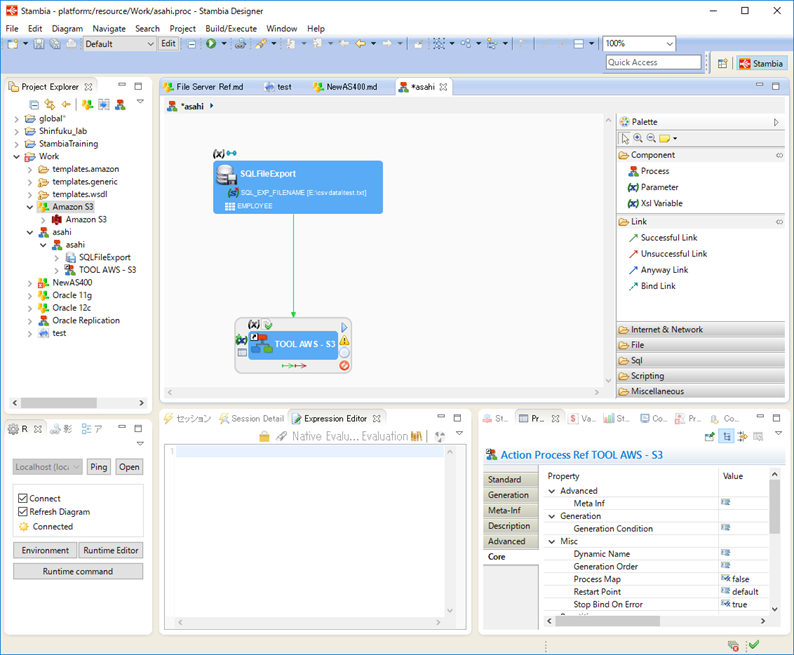
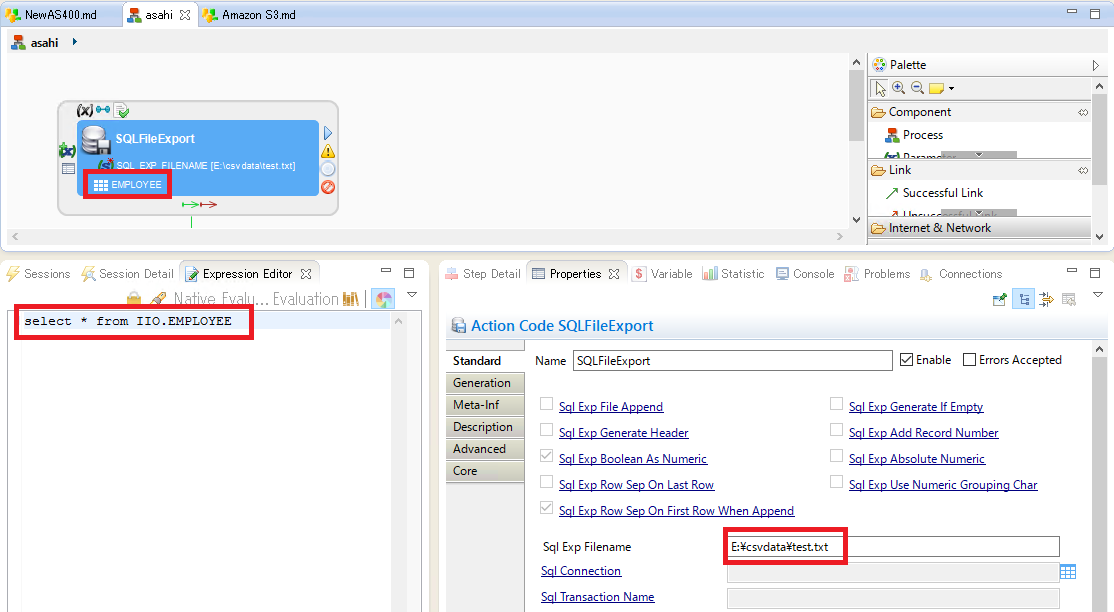
ファイルとしてデータを収集する場合には、SQLFileExportと呼ばれる機能を使用します。
このテンプレートでは、どこのデータソースから、どのようなクエリを発行して、どのフォルダへファイルとしてデータをエクスポートするか指定します。
以下の図では、EMPLOYEEというテーブルに対してSelectコマンドを実行し、返ってきた値を E:\csvdata\test.txt としてエクスポートしています。
要件によってさらにデータソースを追加し、クエリを調整することで複数のデータソースからデータを統合し、ファイルにエクスポートすることも可能です。
Amazon S3へのプッシュ
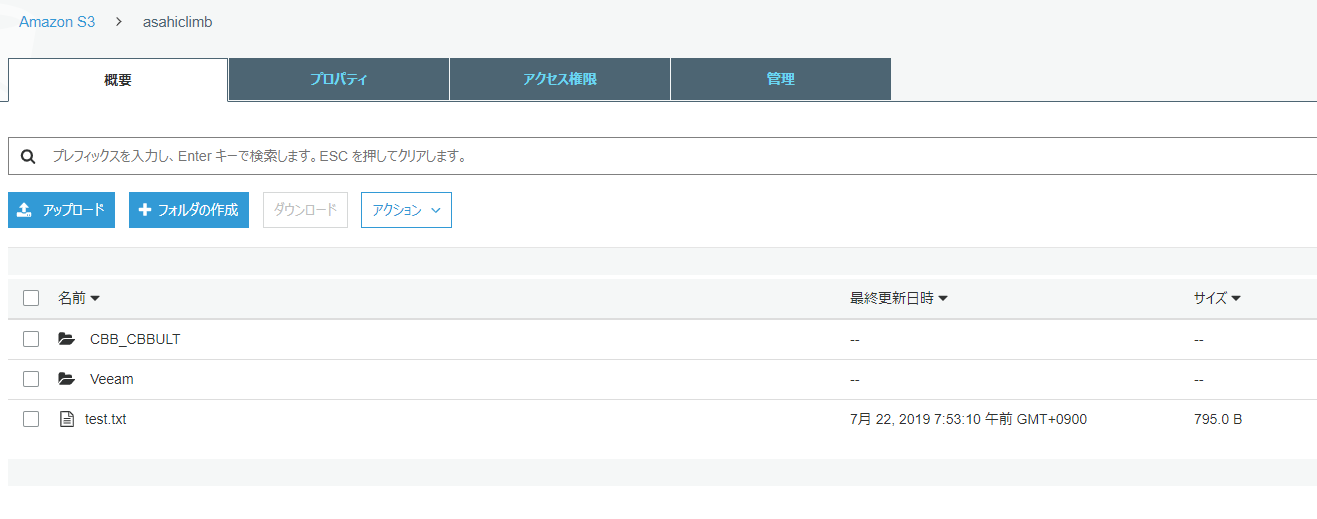
実際にAmazon S3へデータをプッシュする場合には、Stambiaテンプレートの中にあるTOOL AWS -S3を使用します。ここでは、既に登録したAmazon S3のアクセスキー、シークレットキーの他に、バケット名やリージョンを指定します。
今回は、東京リージョンのasahiclimbというバケットを指定しています。

あとは実際にプロセスを実行することで、ファイルとして収集したデータをAmazon S3へ保存することができ、各種BI・解析ツールやサービスでデータを分析することができます。
関連したトピックス
- Database Performance Analyzer (旧Ignite)の情報からSQLチューニング実践:索引編
- StambiaのSalesforceとの接続ツール: Open Connector for Salesforce
- Stambia Component for SAPの機能紹介
- Stambia ユーザー導入事例:仏ランジェリー ブランド Chantelle(シャンテル)
- Oracle Data Integrator ― マイグレーションに関する4つの課題と Stambiaがもたらす解決策
- Stambia Component for SAP:SAPでの異なるデータ統合のユーザ使用例
- Salesforceとのデータ統合:6つの利点 [Stambia]
- レプリケーション検証機能(Validate)によるトランザクション情報取得チェック
- クエリ実行とデータベースパフォーマンスの理解 ,そしてそれらがアプリケーションに与える影響 [DPA]
- 豊富なテンプレートでデータ統合に最適な処理を手間なく簡単開発 [Stambia]

 RSSフィードを取得する
RSSフィードを取得する

