

クライムが販売するARTESCAオブジェクトストレージソフトウェアに関する初期段階ながら秀でた性能結果を紹介いたします。下記の数値は、インテル研究所で実施されたARTESCAストレージサービス層(ストレージI/Oエンジン)のテスト結果です。性能は常に当該製品の設計目標であり、顧客やアプリケーションパートナーがS3オブジェクトストレージを新たな多様な方法で採用する中、性能の進化が求められるようになった現在、その重要性はさらに高まっています。ARTESCA製品は、このエコシステムの急速に変化するニーズに対応するソリューションを提供するという取り組みです。
多くのIT管理者は既に、従来の オブジェクトストレージ製品の特性を熟知しています。一般的な認識として、オブジェクトストレージは大容量ファイルに対して非常に優れた性能を発揮し、画像・動画・大規模バックアップペイロード向けのストリーミングスループットを提供できます。スケーラブルなスループットが主要指標となるワークロードにおいて、一部のオブジェクトストレージシステムは数十GB/秒を超えるスループットを容易に達成可能です。
対照的に、小規模なファイルデータに対する認識としては、オブジェクトストレージは強力なトランザクションスループット(秒間操作数)と極めて低い応答時間レイテンシの提供において比較的劣るとされています。これらの性能指標は、オブジェクトストレージが適用されるワークロードやデータセットがますます多様化・高度化する中で、今や非常に重要性を増しています。具体的にはAI・機械学習、IoT、データレイク/アナリティクス、そしてエッジ環境における予測不能なアプリケーションの急増などが挙げられます。新たなアプリケーションでは、数十バイトから数百バイト規模(IoTイベントストリームなど)のファイルを生成・消費すると同時に、数ギガバイト級のメディアファイルも処理する必要があります。
したがって、新たな時代には幅広い性能要求を持つワークロードが存在します。さらに、新しいアプリケーションには以下が求められます:
- ●最新のAmazon S3互換オブジェクトストレージ:高度な機能を含むS3 APIの包括的なサポート
- ●あらゆる局面での高性能:小規模ファイルへの超低遅延アクセス、高い(かつスケーラブルな)秒間操作数(ops/sec)を維持しつつ、大規模ファイル向けの高スループット性能を保持
- ●信頼性と耐久性に優れたストレージ:データ完全性や損失に対する多様な脅威からデータを保護し、可用性を維持するため、ソリューションは低レベルなストレージサービス層まで設計されなければなりません
ここで最後の項目が鍵となります。これらの制約のいずれかを緩和できれば、高速なオブジェクトストアを構築するのははるかに容易です。ストレージシステムが処理量を減らせる場合、ベンチマーク数値の向上が実証可能です。これは特に、軽量なS3フロントエンドに特化する一部のオブジェクトストレージシステムに当てはまりますが、その代償としてディスク管理やデータ保護機能が犠牲になります。
ここに登場するのがARTESCAです。軽量なオブジェクトストレージを提供するだけでなく、前述の2つの要件を妥協せずに実現するよう設計されています。
ARTESCAストレージサービスのレイテンシと帯域幅のテスト
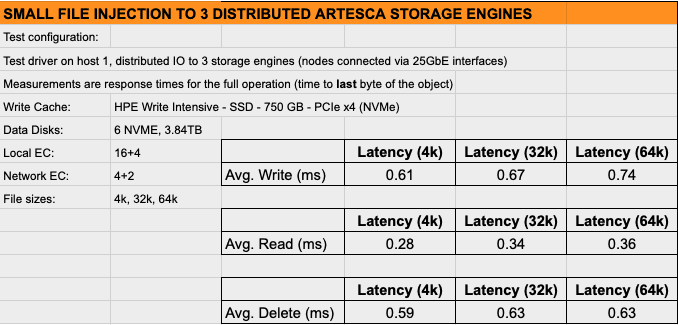
基盤技術の詳細に入る前に、ストレージエンジンのテストで得られた結果を確認します。ここでの目的は、要求の厳しい小ファイルワークロードでストレージエンジンに負荷をかけ、書き込みキャッシュとして使用されるNVMeフラッシュドライブとSSDでのパフォーマンスを検証することでした。全てのテストは、スイッチ上の25GbEネットワークインターフェース経由で接続された3台のホスト(ストレージサーバ)上で実行されました。小ファイルサイズ(4Kb、32Kb、64Kb)における読み取り、書き込み、削除操作のレイテンシを測定しました。結果を理解する上で重要なのは、各操作の完全な処理時間(ファイルの最終バイトまでの時間)を計測した点です。
注:サーバ構成の詳細については、本ブログの後半で説明します。
では、まず結論からパフォーマンス数値を提示します。要約すると、SSDを書き込みキャッシュとして使用し、NVMeフラッシュをデータストレージとして使用するサーバにおいて、このストレージエンジンは4Kファイルの操作レイテンシを1ミリ秒未満に抑えることに成功しました(繰り返しになりますが、ファイルの最終バイトまでの完全な操作時間を計測):
- ●0.28ミリ秒 (ms) 4kファイルの読み取りレイテンシ
- ●0.61ミリ秒 (ms) 4kファイルの書き込みレイテンシ
- ●1ミリ秒未満のレイテンシ は、32kファイル(それぞれ0.34 & 0.67 ms)および64kファイル(それぞれ0.36 & 0.74 ms)の読み書き操作でも持続します。
- ●これらの数値は、完全なデータ保護メカニズム(次節で説明する二重レベル消去符号化)を有効化した状態で達成されています。
前述の通り、これらの結果は非常に有益です。データ保護を確保するためにストレージエンジンが担う重い処理が、現代のフラッシュサーバ上でミリ秒未満のレイテンシと共存できることを示しているからです。これはオブジェクトストレージを高速化するシステム設計全体の一部であり、次回では大容量ファイルおよびフルスタックのパフォーマンスについて検討します。次のセクションでは、この耐久性のあるデータ保護を実現するための仕組みについて説明します。
ARTESCAのデータ耐久性
ストレージエンジンの設計において、3つの主要な目標を設定しました:
- ●比類のないデータ耐久性と高速化された再構築
- ●高密度フラッシュ(NVMe、QLC、将来のメディア)を活用し、メディアの信頼性を維持(将来の密度増加時も含む)
- ●ソフトウェア定義アーキテクチャによる柔軟なプラットフォームサポートの選択肢の維持
ARTESCAストレージサービスは、高密度ストレージサーバ上でデータを効率的に保存し保護するため、以下のメカニズムを実装しています:
- ●二重レベル消去符号化(EC): ネットワーク(分散)消去符号とサーバ内ローカルパリティ符号の組み合わせ。これにより障害に対する保護が提供され、ローカルディスク障害時のローカル(非ネットワーク)修復時間が短縮されます。特に大容量ドライブにおいて耐久性が大幅に向上します。スキーマは柔軟性を考慮して設定可能であり、ドライブ障害発生時にも適応します。
- ●データ複製: オブジェクトの複数コピーを異なる複数のディスクドライブおよびマシンに分散保存。小規模データオブジェクトにおいて、ストレージ効率とパフォーマンスの面で最適です。
- ●データ整合性保証: エクステントレベルおよびオブジェクトレベルでチェックサムを保存。継続的なバックグラウンドスキャン(ディスクスクラビング)と、読み取り時のチェックサム検証を実施。これにより、ディスクエラー(「ビット腐敗」)に起因するデータ破損問題の排除に重点を置いています。
- ●障害検出と自動自己修復(修復/再構築): ディスクドライブ障害発生時、ストレージエンジンは影響を受けた(または欠落した)ブロックを他の利用可能な未割り当てストレージ領域へ再配置可能であり、複数のディスクに対して並列に実行できます。
マルチサーバARTESCAクラスターにおいて、この二重レベルEC方式は極めて高いディスク障害耐性と耐久性を提供します。具体的な例を挙げると:
最新のストレージサーバ6台(各サーバ24台のディスクドライブ)を想定します。データ耐久性のため、システムは二重レベル消去符号(16+4:ローカルECデータ+パリティ、4+2:ネットワークECデータ+パリティ)で構成されました。通常時、各サーバはローカルパリティでデータを保護しますが、システムは分散データとパリティストライプによりデータをクラスター全体に分散します。これらの耐久性ポリシーは柔軟に設定可能であり、より高い耐久性やスペース効率に応じて調整できます。
当該システムがデータ損失やサービス可用性の低下なく耐えられる障害数は以下の通り:
- ●各サーバのローカルEC:サーバあたり4ドライブの障害に耐性
- ●ネットワークEC併用時:2台のサーバ全体が同時に障害発生可能(48ドライブ)
- ●計算式:2台のサーバ全体が障害発生可能(48ドライブ)+残る4台のサーバが各4ドライブ(計16ドライブ)の障害に耐性 → 合計64ドライブの損失に耐えられる
この構成では、ドライブの44%が故障してもシステムの可用性とデータ保護が維持されます。その結果、従来の分散型消去符号化方式と比較して10倍の故障耐性を提供しつつデータ保護を維持するため、非常に高いレベルの耐久性保護が実現されます。

技術解説:ARTESCAストレージサービスの内部構造
ARTESCAが耐久性と高性能を両立させる仕組みを、ストレージエンジンの内部構造から見ていきまます。
ARTESCAはオブジェクトデータのペイロードを固定サイズのエクステントで保存します。これだけで複数の利点があります:ファイルシステムのiノードの過剰割り当てを回避し、スケーラビリティを向上させ、断片化も防ぎます。小規模オブジェクトは空きエクステントの空き領域に収まります(大規模ファイルは分割され複数のエクステントに分散保存されます)。オブジェクトは保存時に現在の空きエクステント内で領域を割り当てられ、空き領域に順次書き込まれます。クローズされると、エンジンは各サーバ上でエクステントのパリティ(前述のローカルパリティコード)を計算し、エクステントレベルのチェックサムと共に保存します。エクステントが満杯になるとクローズされ、新しいエクステントが割り当てられます。
これは高密度フラッシュの最適化にも寄与します。固定エクステントストレージ方式はフラッシュメディアのI/Oパターンに自然に適合するためです。最初に高速フラッシュメディア(上記のテストではSSDを書き込みバッファとして使用)にエクステントを安全に保存し、満杯になると、システムはこれらのロック済み(満杯かつ消去符号化済み)エクステントを恒久的な長期保存メディア(NVMeまたはQLCフラッシュ)へステージングダウンできます。さらなる効果として、長期保存メディアへのI/Oが最小化され、高密度フラッシュデバイスのプログラム/消去(P/E)サイクルが保護されます。
テストシステム構成
前述の実験テスト実施に使用したセットアップに関する追加情報です。3台の最新Intelベース24ドライブストレージサーバを使用し、各サーバは以下のように構成されています:
- ●Intel Xeon-Gold 6226R (2.9 GHz/16コア/150 W) プロセッサ
- ●128GB (1 x 128GB) クワッドランクx4 DDR4-2933
- ●1 x HPE Write Intensive – SSD – 750 GB – PCIe x4 (NVMe)
- ●1 NVME, 750GB (OS/システムディスク)
- ●6 NVME, 3.84TB (NVMe Gen4 メインストリーム性能 SFF SSD)
- ●イーサネット 10/25Gb 2ポートアダプター
上記の結果は、ディスクドライブが部分的に搭載されたサーバで達成されたものであり、ディスクを追加すればIO集約型ワークロードのパフォーマンスがさらに向上することは間違いありません。









 RSSフィードを取得する
RSSフィードを取得する
