
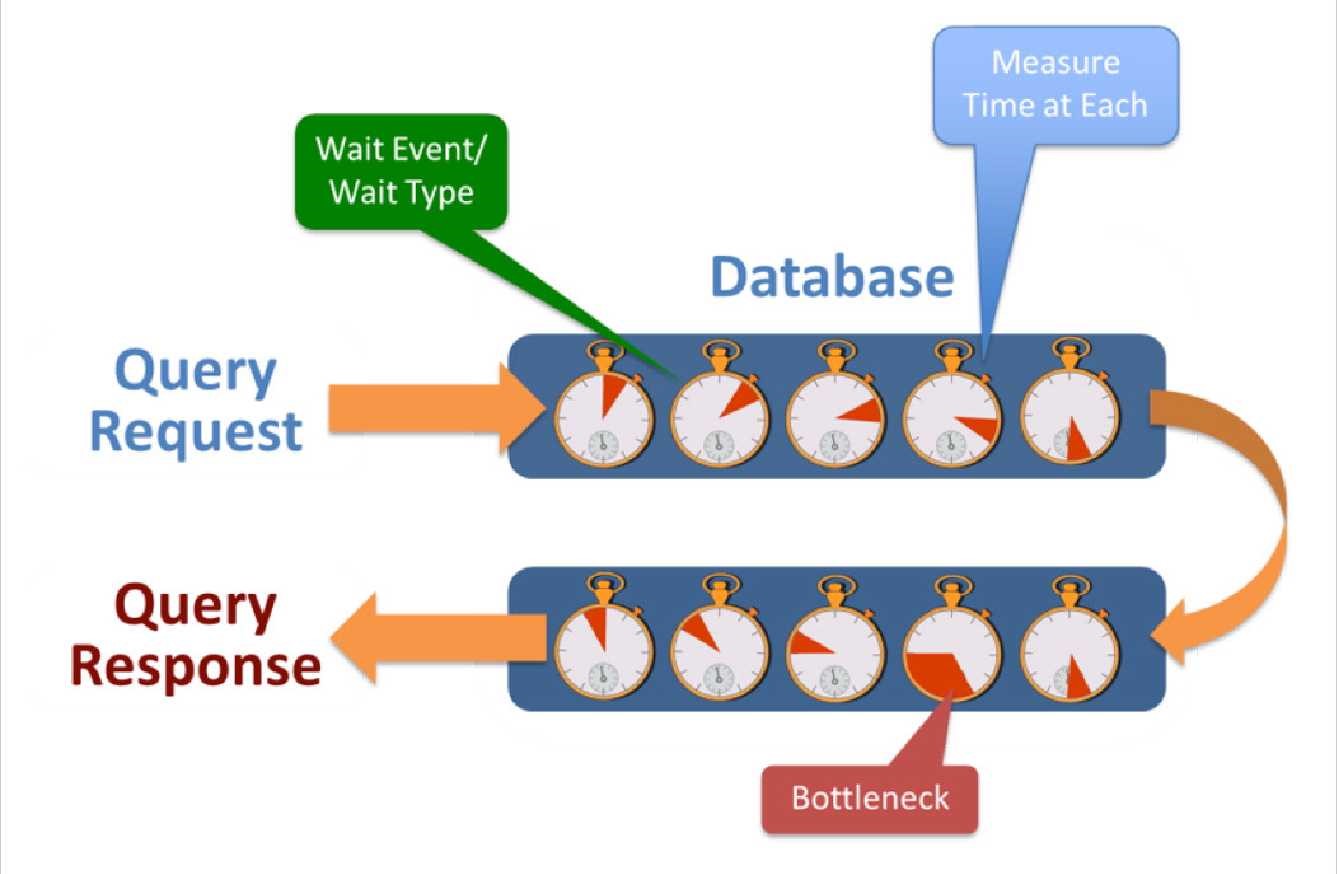
レスポンスタイム分析(RTA)は、DBAがクエリ実行にかかる時間を測定し、エンドユーザへの影響を測定できるようにするアプローチです。1999 年に Cary Millsap によってデータベースパフォーマンスの視点として紹介され、2001 年に Craig Shallahamer によって再び明確化された エンドユーザがアプリケーションオーナー、バッチプロセス、エンド ユーザー消費者のいずれであっても、ユーザにとって最適な結果に基づいてデータベースパフォーマンスを監視、管理、調整する、実証済みの包括的な方法です。
RTA は、アプリケーションパフォーマンス管理 (APM) が IT 部門に提供するのと同じことを DBA に提供します。エンドユーザからのクエリーリクエストに始まり、エンドユーザへのクエリーレスポンスに終わるエンドツーエンドプロセスを、その間の各ステップで費やされた時間を含めて測定します。RTAを使用することで、ボトルネックを特定し、その根本原因を突き止め、エンドユーザへの影響に基づいて対処の優先順位を決定することができます。つまり、RTAは、より良いサービスを提供し、トラブル・チケットを迅速に解決し、最も影響力のある場所に労力を集中させる時間を確保するのに役立つのです。
ここでは、RTA の詳細について説明し、RTA を実行するために利用できるツールの概要を示します。これにより、エンドユーザへの影響に着目してデータベースインスタンスのパフォーマンスを監視および管理することができます。
目次
カウンターやシステムヘルス指標だけでは不十分な理由とは?
データベース・インスタンスのパフォーマンスが低下したとき、Webページの読み込みが遅いとき、価格検索が遅すぎて顧客がページを放棄したとき、バッチ処理が時間内に完了しないとき、最初の対応としてカウンターとシステム健全性メトリクスを見て答えを見つけようとすることがよくあります。残念ながら、このような情報は不完全で、時には誤解を招くこともあり、エンドユーザ・エクスペリエンスと容易に関連付けられることはほとんどありません。
カウンターの側では、特定の期間内に行われた物理的な読み取り回数、書き込み回数、ロック統計などを見ることができます。しかし、このような性能の見方には限界があります。例えば、あるアプリケーションの動作が遅いと言われたとします。よく見てみると、キャッシュヒット率が60%しかないことがわかります。このことから、根本的な原因は何だと思いますか?バッファーキャッシュが小さすぎるのでしょうか?大規模なフルテーブルスキャンや非効率的なクエリが実行されているのでしょうか?もしそうなら、どのクエリですか?エンドユーザにどのような影響があるのでしょうか?これらの疑問は、キャッシュヒット率を見るだけでは答えられません。
システムの健全性評価指標の側でも、実用的な情報の量は同様に不足しています。例えば、あるサーバのCPU使用率が90%に上昇し、その状態が1日続いたとします。それはサーバに原因があるのでしょうか?クエリに問題があるのでしょうか?CPU使用率の上昇だけを見れば、需要がサーバのキャパシティを超えたと判断し、新しいサーバを追加するかもしれません。しかし、それでCPU使用率が変わらなかったらどうでしょう?エンドユーザに何か影響があったのでしょうか?高価なハードウェアを追加しても問題が解決されないのは、これが初めてではないでしょう。サーバの状態に関する情報だけでは、このような疑問に答えることはできないのです。
エンドユーザへの影響を測定することに焦点を当てたデータベースパフォーマンスアプローチは、明らかに異なる情報を必要とします。データベースインスタンスの内部で何が起きているのかを明らかにし、ユーザへの影響を定量化する情報が必要です。
レスポンスタイム分析(RTA)とは、待ち時間、キュー、時間についてのすべてである
RTAの核となるのは、待機イベントや待機タイプです。サーバプロセスやスレッドが、あるイベントの完了やリソースが利用可能になるのを待ってからクエリの処理を続行する必要がある場合、そのイベントを待ちイベントと呼びます。例えば、バッファへのデータ移動、ディスクへの書き込み、ロック待ち、ログファイルへの書き込みなどです。通常、クエリのリクエストとレスポンスの間には、数百の待機イベントが経過している必要があります。
もし、あるクエリが特定の待ちイベントで通常よりも多く待機している場合、それをどのようにして確認することができるでしょうか?何が「正常」なのか、どうやってそれを知ることができるのでしょうか?なぜ待たされるのかをどうやって調べればいいのでしょうか?そして、どのようにそれを修正するのでしょうか?そこで、RTAの出番です。
RTAは、各クエリの待ち時間を測定し、このデータを他のクエリや時間との関連で見ることができるため、エンドユーザに最も影響を与える取り組みの優先順位を決めることができます。
RTAが機能するためには、以下のことが必要です。
1.遅延の原因となっている特定の待ち事象を特定する。
潜在的な問題やボトルネックを切り分けることができるように、すべての待ちイベントを個別に測定する必要があります。
2. 遅延が発生した特定のクエリーを特定する。
インスタンス全体が遅延していることだけが分かっていると、遅延やボトルネックを引き起こしている特定のクエリを切り分けることができません。
パフォーマンス監視ツールやダッシュボードの中には、複数のクエリの平均的な評価を表示するものがあることを知っておくことが重要です。平均化されたデータを見ている場合、どのクエリがパフォーマンスを低下させているのか、どうやって判断するのでしょうか?RTAのアプローチを成功させるためには、個々のクエリレベルでパフォーマンス統計を収集する必要があります。
3.遅延の時間的影響を測定する。
各待機イベントごとに、タスクが完了し、次のプロセスに作業が引き継がれるまでの時間(待機イベント時間)を測定する必要があります。この情報がなければ、何がボトルネックになっているのか完全に把握することはできません。
これらのデータがあれば、クエリごとに、またクエリが使用するリソースごとに、それぞれ説明することができます。そして、データベースインスタンスの内外を問わず、遅延の根本原因を正確に突き止めることができるのです。
応答速度解析に必要なデータはどこから来るのか?
RTAに必要なパフォーマンスデータを取得する方法は、既存のデータベース管理ツールやTraceファイルなど、さまざまなものがあります。それぞれに長所がありますが、重要な制限もあります。例えば、ほとんどの場合、時間がかかり、ポイントインタイムビューに限定され、経験豊富なDBAのみがアクセス可能です。さらに、継続的なパフォーマンス監視ツールは、既存のデータベース管理ツールを補完し、RTAを大幅に簡素化および高速化することができます。
トレースによる継続的な監視
トレースは、他の方法では得られないような正確で豊富な情報を提供し、すべてのクエリーを捕捉します。
しかし、トレースには多くの欠点がある。まず、トレースは選択的にオンになっており、履歴やトレンドの情報は得られません。いつ、どこで問題が発生するかを事前に把握し、そのセッションのトレースをオンにし、何が起こったかを見守る必要があります。つまり、トレースは24時間365日のモニタリングや、プロダクションシステムの完全なパフォーマンス分析、あるいはプロアクティブなパフォーマンス管理には役に立ちません。トレースはまた、高いオーバーヘッドを発生させます。もし、問題解決のために使うのであれば、最悪のタイミングでオーバーヘッドを増やすことになります。実際、トレースのようなツールがデータベースサーバに与える負荷は、一部のDBAがRTAを行いたくない理由の1つです。彼らは、トレースが効果的なRTAを行うために必要な情報を得る唯一の方法であると誤解しています。
トレースのもう一つの見落とされがちな問題は、トレースがあまりにも多くの情報を生成してしまうことです。それを正確に分類し、その意味を評価するためには、熟練した DBA と多くの時間が必要です。このため、開発者や経験の浅い DBA には特に不適切です。
最後にトレースは、パフォーマンス問題の根本原因の評価を歪めてしまう可能性があります。例えば、100セッションのうち95セッションは正常に動作しているが、5つのセッションがロックされた行を待つために99%の時間を費やしているという状況を考えてみましょう。95の「良好な」セッションの1つをトレースすると、ロックの問題はないと思うかもしれません。そして、それほど重要でない他のクエリのチューニングに時間を費やすことになるでしょう。一方、5つの「悪い」セッションの1つをトレースした場合、ロックの問題を修正し、待ち時間を99%短縮できると考えるかもしれません。どちらの評価も完全に正確ではなく、その評価に基づいて行う努力は、問題の真の原因に対処できないことになります。その結果、多くの時間とリソースを無駄にしてしまうことになります。
継続的なパフォーマンス監視ツール
継続的なパフォーマンス監視ツールは、RTAを実施するDBAが利用できるツールの次の進化を示します。これらのサードパーティツールは、通常、既存のデータベース管理ツールを補完するもので、パフォーマンス情報を一箇所に集約することでパフォーマンス管理を簡素化することを目的としています。
しかし、これらのツールにも限界がある場合があり、投資を行う前にツールを慎重に評価する必要があります。
RTAに最適な継続的パフォーマンス・モニタリング・ツールは、以下の基準を満たしています。
>>RTAに必要な3つの重要な要素を特定し、測定することができる。
>遅延した特定のクエリを特定する。
>遅延の原因となる特定のボトルネック(待機イベント)を特定する
>特定されたボトルネックの時間的影響を示す
特にツールのデータ収集方法、データ収集先に注目することが重要です。
>>過去のトレンドデータへのアクセスにより、24時間365日の継続的な監視を実現
>>システムに負荷をかけない(これらのツールの中には、パフォーマンスデータの収集にトレースに依存しているものがあり、監視対象のサーバに負荷をかける可能性があります)
>> 開発者や管理者などの非DBAがパフォーマンスを評価するために使用することができる(そのため、DBAは説明する時間を減らし、実行する時間を増やすことができる)以下の質問を必ずしてください。
>>非 DBA が使用できるほど、使用と理解が容易であるか?
>>実稼働中のデータベースインスタンスにアクセスできるユーザを必要とするか?
これらの要件をすべて満たすツールでなければ、RTAの実行に役立つことは限られます。
今こそレスポンスタイム分析
RTAは、ユーザ・エクスペリエンスに関連するパフォーマンスを発見し、測定するための体系的な方法を提供します。RTAは、リクエストからレスポンスまで、クエリのエンドツーエンド、その間に発生したすべての待ち時間、および処理中にクエリが使用したすべてのリソースを測定します。RTAは、この情報を他のクエリとの関連付けを行い、過去のトレンド情報を提供することで、エンドユーザに最大の影響を与えるボトルネックを特定し修正することができます。RTAは、チューニングを深夜や週末に危機管理モードで行われる後手後手のプロセスから、サービスを提供するエンドユーザに結びついた先を見越したプラクティスに変えることができます。
Database Performance Analyzer(旧Ignite、以下DPA)は、DB管理者、ITマネージャーおよびアプリケーション開発者向けに、レスポンス・タイム(応答時間)の計測を用いて、包括的なデータベースパフォーマンスをモニター化することで、データベースの監視するRTAツールです。DPA独自の多次元データベースパフォーマンス分析により、物理サーバー、クラウドベースサーバー、VMwareサーバー上のSQL Server、Oracle、SAP ASE、DB2データベースを継続的に監視し、アプリケーションパフォーマンスに影響を与えるデータベース問題の根本を素早く突き止めることが可能です。
関連したトピックス
- Database Performance Analyzer [DPA] でSQL Serverのパフォーマンスを見つけ、分析し、最適化へ
- 仮想化されたデータベース:パフォーマンス監視の考慮事項
- パフォーマンス監視とチューニングのためのSQLデータベースとデータサーバツール [DPA]
- Amazon AWSクラウド上でのアプリケーションとデータベースのパフォーマンス問題
- Database Performance Analyzer(旧Ignite)画面のDBやSQLの表示名変更方法
- 待ち時間分析によるOracleからPostgreSQLへの移行のトラブルシューティング:Database Performance Analyzer(DPA)
- MySQLスロー・クエリログ・アナライザ [DPA]
- Database Performance Analyzer [DPA] による待ち時間の増加の調査手法
- Webセミナー録画とプレゼンテーション『 Oracle コンサルいらずのチューニングことはじめ』:2020/2/6 開催
- Database Performance Analyzer (旧Ignite) for SQL Severの主な機能: SQL Serverパフォーマンス・モニター、レスポンス分析ソフト

 RSSフィードを取得する
RSSフィードを取得する


