

目次
データマスキングは?
データマスキングとは、ソフトウェアテストやユーザトレーニングなどの目的で使用でき、構造的には似ているが本物ではないバージョンの組織データを作成する方法です。その目的は、実際のデータを保護すると同時に、実際のデータが不要な場合に備えて機能的な代替物を用意することです。
ほとんどの組織では、保管されている本番データや業務で使用されているデータを保護するために厳格なセキュリティ管理が行われているが、同じデータ要素が安全性の低い業務に使用されていることもあります。このような業務がアウトソーシングされ、組織がその環境を管理しにくくなっている場合、問題はさらに深刻になることが多々あります。コンプライアンスに関する法規制の影響で、ほとんどの組織は不必要に実データを公開することに抵抗があります。
データマスキングは、データセット内の元の値を、さまざまなデータシャッフリングや操作テクニックを使ってランダム化したデータで置き換えます。複雑化されたデータは、元のデータのユニークな特性を維持し、元のデータセットと同じ結果をもたらします。
データマスキングの仕組み
暗号化は、機密データを安全に保存・転送するための最良の方法です。しかし残念ながら、暗号化されたデータは照会や分析が困難です。例えば、出生データが暗号化されている場合、年齢に基づいてユーザをフィルタリングすることはできません。そのため、研究、開発、テストにデータを使用する場合、データを安全かつプライベートに保つ別の方法が必要となります。
データマスキングは、データサニタイゼーション(Data Sanitization)とも呼ばれ、機密情報を認識できないようにしながらも使用できるようにすることで、機密情報を保護します。これにより、開発者、研究者、アナリストは、データを漏洩リスクにさらすことなくデータセットを使用することができます。
データマスキングは暗号化とは異なります。暗号化されたデータは、正しい暗号化キーがあれば復号して元の状態に戻すことができます。マスキングされたデータでは、元の値を復元するアルゴリズムはありません。データマスキングは、ハッカーにとって価値がゼロのデータセットで、特徴的に正確だが架空のバージョンを生成します。また、リバース・エンジニアリングも不可能であり、統計的な出力から個人を特定することもできません。
データの暗号化と同様、すべてのデータ・フィールドをマスキングする必要はありませんが、完全に隠さなければならないフィールドもります。
暗号化オペレーション例
なぜデータマスキングが重要なのか?
さまざまなデータ保護基準や規制により、企業やその他の組織は、個人を特定できる情報(PII:Personally Identifiable Information)や医療情報を保護し、機密を保持することが義務付けられています。これらの代表的な基準や規制には以下のようなものがあります:
●General Data Protection Regulation (GDPR:一般データ保護規則)
●Health Insurance Portability and Accountability Act (HIPAA:医療保険の相互運用性と説明責任に関する法律)
●Payment Card Industry Data Security Standard (PCI DSS:クレジットカード業界データセキュリティ基準)
これらの規制や基準は、適切なレベルのデータ保護を確立し、権限のないユーザによるデータへのアクセスを防止する上で重要な役割を果たしています。しかし、これらの規制や基準は、データを分析したり他者と共有したりしたい企業にとっては、困難なものもあります。データマスキングは、機密データが暴露されるリスクを軽減し、企業が規制されたデータを扱いながら様々な基準や規制に準拠することを可能にします。
 データマスキング・テクニック例
データマスキング・テクニック例
データマスキングのテクニック
データの種類に応じて、PIIおよびその他の個人情報や機密データをマスキングまたは匿名化するために、さまざまなデータ管理技術を使用することができます。これらのマスキングテクニック・手法には以下のようなものがあります:
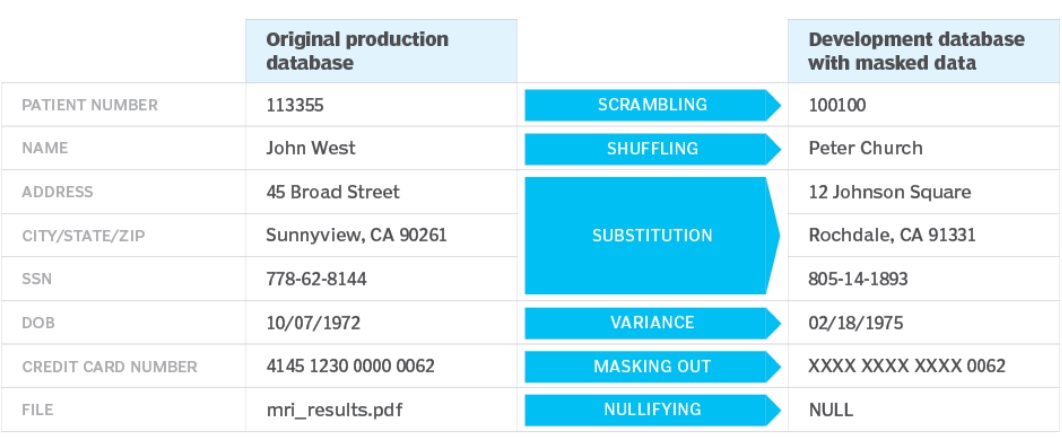
スクランブル
スクランブルは、英数字をランダムに並べ替え、元のコンテンツを見えなくします。例えば、本番環境では3429871という顧客からの苦情チケット番号が、テスト環境ではスクランブル後に8840162と表示されるようなものです。スクランブルは簡単に実装できますが、特定のタイプのデータにしか使えません。この方法で難読化されたデータは、他の技術ほど安全ではありません。
置換
この技術は、元のデータを信頼できる値の供給源から別の値に置き換えます。ルックアップテーブルは、元の機密データの代替値を提供するためによく使用されます。値はルールの制約をパスし、データの元の特性を保持しなければなりません。
スクランブリングよりも置換を適用するのは難しいが、いくつかのデータタイプに適用でき、優れたセキュリティを提供します。例えば、クレジットカード番号は、カードプロバイダの検証ルールをパスする番号に置き換えることができます。
シャッフル
列内の値、例えばユーザの姓をシャッフルしてランダムに並べ替えます。例えば、顧客の姓がシャッフルされた場合、結果は正確に見えますが、個人情報は明らかになりません。しかし、シャッフルマスキングアルゴリズムは、データマスキングプロセスをリバースエンジニアリングするために使用できないように、安全に保つことが不可欠です。
日付エージング
この方法は、日付フィールドを特定の日付範囲で増減させます。ここでも、使用される範囲値は安全に保たれなければなりません。
分散
数値または日付フィールドに分散を適用します。この方法は、財務や取引の値や日付情報のマスキングによく使われています。バリアンスアルゴリズムは、列の各数値や日付を、その実際の値のランダムなパーセンテージで変更します。例えば、従業員の給与の列にプラスマイナス5%の分散を適用することができます。これにより、給与の範囲と分布を既存の範囲内に維持しながら、データを合理的に偽装することができます。
マスキングアウト
マスキングアウトは値の一部だけをスクランブルするもので、下4桁だけが見えるクレジットカード番号によく適用されます。
無効化
無効化(Nullifying:ヌリフィング)は、データ列の実際の値をヌル値で置き換え、完全にデータを見えなくします。この種の削除は実装が簡単ですが、ヌル化されたカラムはクエリや分析では使用できません。その結果、開発やテスト環境のデータセットの整合性や品質を低下させる可能性があります。
データマスキングの種類
データをマスキングするプロセスは、データが必要とされる場所とタイミングによって、さまざまな方法で開始することができる。データマスキングには次のような種類があります:
●静的データマスキングは、研究、開発、モデリングなどの非生産環境で使用できる、本番データベースとは別のマスキングされたデータセットを作成します。マスキングされたデータ値は、元のデータを反映したテスト結果や分析結果を生成し、正確で再現性のある結果を保証するために、長期にわたって持続する必要があります。
●ダイナミック・データ・マスキングは、特に本番システムにおいて、ユーザが実データを必要とする場合に、役割ベースのセキュリティを提供します。データの要求に応じて、ダイナミック・マスキングは、ユーザの役割に基づいて、機密情報フィールドへのアクセスをリアルタイムで変換、不明瞭化、ブロックします。例えば、金融コールセンターのオペレーターが顧客からの問い合わせに対応する場合、生年月日、社会保障番号、クレジットスコアなどの機密フィールドは、オペレーターがこれらのフィールドを表示するために必要な権限を持っていない限り、マスクされます。リクエストに応じて本番環境からデータをストリーミングすることで、マスクされたデータを別のデータベースに保存する必要性を回避できます。しかし、データが複数のシステムにまたがっている場合、マスキングの一貫性が問題になることがあります。
●オンザフライ(臨機応変)・データ・マスキングにより、開発チームは本番データの小さなサブセットをテスト環境に直接読み込んでマスキングすることができます。データはある環境から別の環境にコピーされる際にマスキングされるため、ターゲット環境やターゲットのデータベースのトランザクションログにマスキングされていない状態で存在することはありません。このアプローチでは、ステージング環境を使用してデータを準備する際に発生する遅延をなくすことができる。そのため、継続的なソフトウェア開発環境に最適です。
データマスキングの課題
データマスキングでのいくつかの課題があります:
複雑性:データマスキングは単純なワンステップの作業ではありません。推論攻撃によって機密情報が暴露されるリスクを排除するために、データを変換しなければなりません。同時にシステムは、頻度分布など、マスキングされていない元のデータの複雑さと独自の特性を維持しなければなりません。これにより、クエリーや分析が元のデータと同じ結果をもたらすことが保証されます。
参照整合性:マスキングされたデータはシステムやデータベース間で参照整合性を維持する必要があります。これは決定論的データマスキングと呼ばれ、データベース間やサーバー間でマスキングされた出力の一貫性を保証し、値が常に同じマスキングされた値に置き換えられることを保証します。例えば、”Helen” という名前は、マスキングされたデータのどこに出現しても常に “Denise” という値に置き換えられ、主キーや外部キー、リレーションシップが保持されます。
これは簡単に聞こえるかもしれませんが、ほとんどのデータベースはパフォーマンスのために正規化されており、機密データは1つまたは複数のデータベースのさまざまなテーブルに格納されます。XML(Extensible Markup Language)のような構造化されたテキストは、難読化しなければならない値を含む可能性があるため、解析してマスキングしなければならなりません。
管理:ソフトウェア・テストで使用されるデータの場合、マスキング・プロセスは、データが郵便番号や銀行口座番号のようなデータ属性を管理する内部ルールと一致していることを保証しなければなりません。ここで注意が払われないと、データ検証チェックが失敗するため、アプリケーションは更新テストに失敗します。
このような課題を克服するために、データベース管理者はマスクされるデータの詳細なレビューを行わなければなりません。開発者、テスター、データサイエンティスト、セキュリティチームなど、データに関わる他の関係者もレビューに貢献する必要があります。これらの利害関係者からのインプットにより、適切なマスキング技術が使用され、有効な置換値のデータソースが生成され、すべてのシステムにわたって参照整合性が維持され、マスキングされたデータが元のデータの特性を維持することが保証されます。
データマスキングのベストプラクティス
データマスキングは、組織がプライバシー規制を遵守し、かつ価値ある洞察のためにデータをマイニングするための重要な要素です。しかし、組織が収集する構造化データおよび非構造化データの量が増え続けているため、規模に応じたデータマスキングの複雑さが増しています。コンプライアンスを維持するには、ベストプラクティスに従うことが不可欠です:
●整理と追跡:企業データは、さまざまなテクノロジーや場所に分散し、さまざまなデータベース、テーブル、カラムに格納されています。正しいデータを確実に保護するためには、保護が必要な機密データを特定し、分類することが重要です。
●非構造化データについての考慮:画像、PDF、XMLやテキストベースのファイルを保護する必要があります。パスポート、運転免許証、領収書、小切手、契約書などの画像は、偽物に置き換える必要があります。光学式文字認識を使用して、ファイル内の機密コンテンツを検出し、マスクすることができます。
●安全性:マスキングされたデータへのアクセスは、役割、場所、権限に関するセキュリティ・ポリシーに従わなければなりません。
●評価:データマスキング技術の結果をテストし、正しいセキュリティレベルを提供し、クエリ結果が元のデータからの結果と同等であることを確認します。
データマスキングの使用例
データマスキングは、イノベーションを推進し、サービスを改善するために多くの業界で使用されています。例えば、銀行や金融業界では、新システムの開発やテスト、不正検知アルゴリズムの改善に利用されています。
データマスキングが使用される理由はさまざまですが、主な原動力はデータセキュリティと個人データのプライバシーです。
●データ漏洩の防止: データ難読化技術は、データ侵害に対する主な防御策です。ネットワークの防御で攻撃者が機密データの流出を防げなかったとしても、データが正しくマスキングまたは暗号化されていれば、攻撃者はデータと個人を関連付けることができません。
●プライバシー・バイ・デザイン:アプリケーションの開発、テスト、分析のライフサイクルの一環としてデータマスキングを実装することで、データプライバシー規制を遵守しながら、重要なデータを社内外で共有することができます。
●役割ベースのアクセス制御:多くの業務では、対象者のデータ属性のすべてではなく、一部へのアクセスが必要です。データマスキングにより、従業員は閲覧権限のないデータを見ることなく業務を遂行できます。
●より速く、より安全なテストデータ:マスキングされたデータは、実際のデータを損なうことなく、テストに必要な完全性と品質を保持します。自動化されたデータマスキングを既存のシステムに統合することで、時間のかかる手動ステップを削除できます。このようにして、テストデータを保護し、中断することなく、本番環境から迅速にリリースすることができます。データマスキングは、本番データがより緩やかな非本番環境や第3者の開発者のアクセスによって公開されないことを確実にします。
各ベンダーから、データマスキングを簡素化し、既存のシステムと統合する機能やサービスが提供されていますが、ぜひAccellarioのデータマスキング機能を検討ください。
関連したトピックス
- Entrust KeyControl Vault for Oracle
- 環境に合わせた独自のデータマスキングルールを作成するには [Accelario]
- EnterpriseDB社のPostgres Plus Standard Server + DBMotoの動作確認【リアルタイムレプリケーションDBMoto】
- DevOpsを高速化!自動マスキングの「Accelario」
- Oracle Standard Editionのためのリーズナブルなディザスタリカバリ・ソリューション [Accelario]
- SQL ServerとMySQLリレーショナルデータベースの比較
- DBMoto with Japanese Language Settings(Ver4.1)【リアルタイムレプリケーションツールDBMoto】
- ユーザ・データベースの最適化とOracle支出の削減
- Database Performance Monitor :データベースの監視と効率化を行うSaaS型ソリューション

 RSSフィードを取得する
RSSフィードを取得する

