
Zerto 7.0では主にUIの刷新とバックアップの機能拡張がメインとなっています。今回はこれをご紹介していきます。
ユーザインターフェイス(UI)の刷新
Zerto 7.0ではより操作を簡単にするためにUIが刷新されました。既にZertoをご利用の方は少々戸惑うかもしれませんが、項目名や各項目で行える操作は基本的に変わっていませんので、慣れればより便利に利用できます。
バックアップ機能の拡張:ロング ターム レテンションLTR
Zerto 6.5で既存のオフサイトバックアップ機能と置き換えで追加されたロング ターム レテンションLTR機能ですが、追加されたばかりは、増分での保持が可能になったのみで、保存先はNFSのみ、細かい設定は行えないと機能不足が否めない状態でした。
これが、7.0で機能拡張され、大幅に使いやすくなりました。
対応保存先の拡張
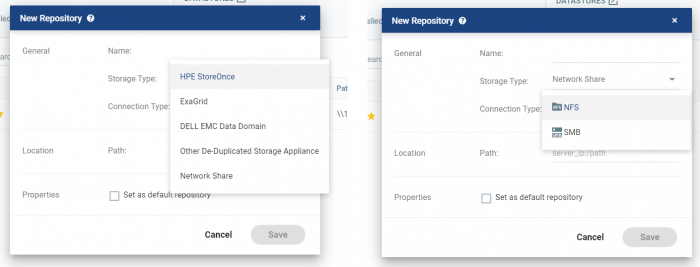
NFSだけでなく、SMBにも対応、加えてHPE StoreOnceやDELL EMC Data Domainなどの重複排除機能を持つストレージアプラインスへの最適化も行われています。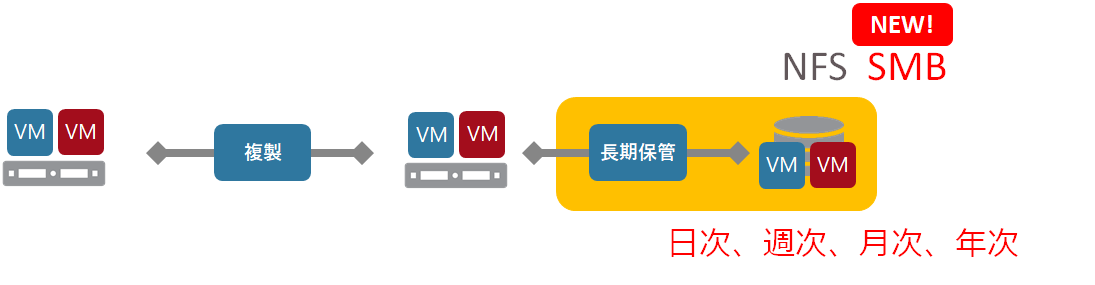
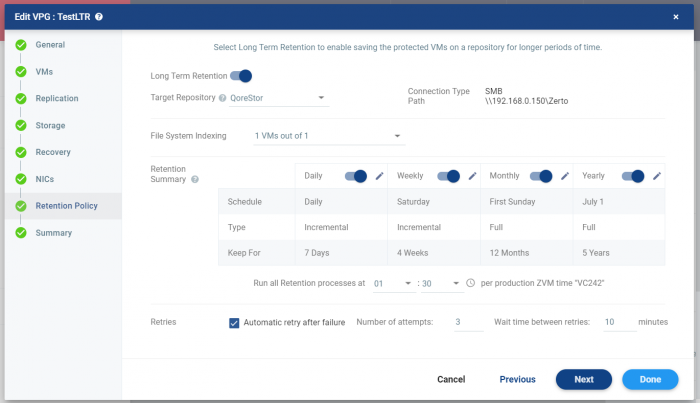
柔軟な保持設定
VPGでLTRの設定を行う際に、6.5までは最も古い世代の保持設定(1ヶ月や1年など)のみしか設定できず、保持世代数等は事前設定されており変更できないものとなっていました。
これが7.0では細かく、日次、週次、月次、年次ごとに何世代残すか、また残す際の方式は増分の世代として残すかどうかというポリシーに合わせた設定が可能になりました。
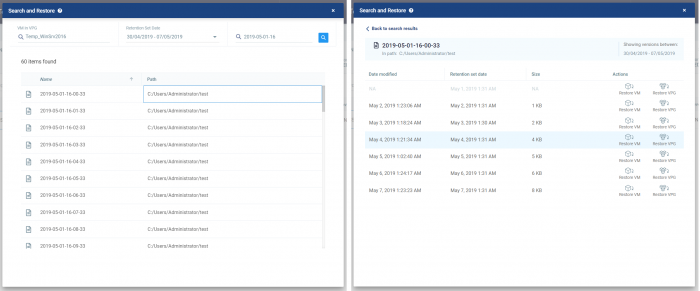
ファイルシステム インデックス サーチ
LTRを有効にしたVPGで特定の仮想マシンに対して、ファイルシステムのインデックスを作成することができるようになりました。これを有効にしたVMはLTRバックアップとして長期保管している世代のどれに特定のファイルが含まれるか、また、そのファイルの変更日時はいつかという情報を確認して特定のVMまたはVPG全体をリストアできます。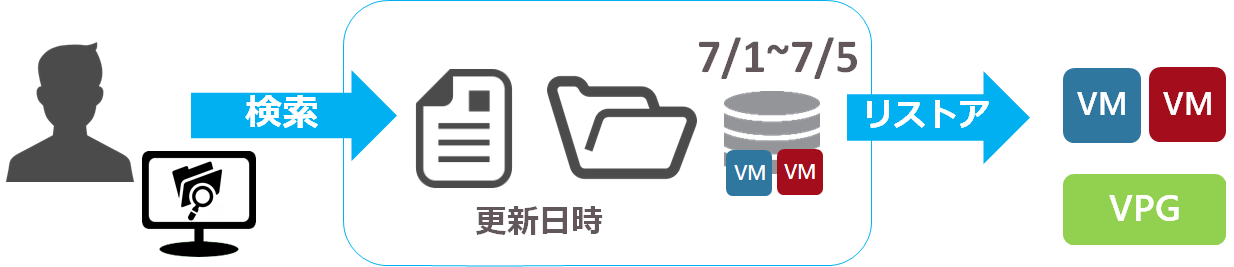
Azureへのフェイルオーバー処理のスケールアウト化
Azureへレプリケーションしている場合、同時にフェイルオーバーを実施しようとすると、これを単一のワーカーインスタンスで処理しようとしていたため、キューがいっぱいになると待機する必要がありました。
これに対して7.0では、Azureスケールセットを使用し、フェイルオーバーで大量のキューが発生する際には、インスタンスを自動追加し、完了後には自動で削除するようになりました。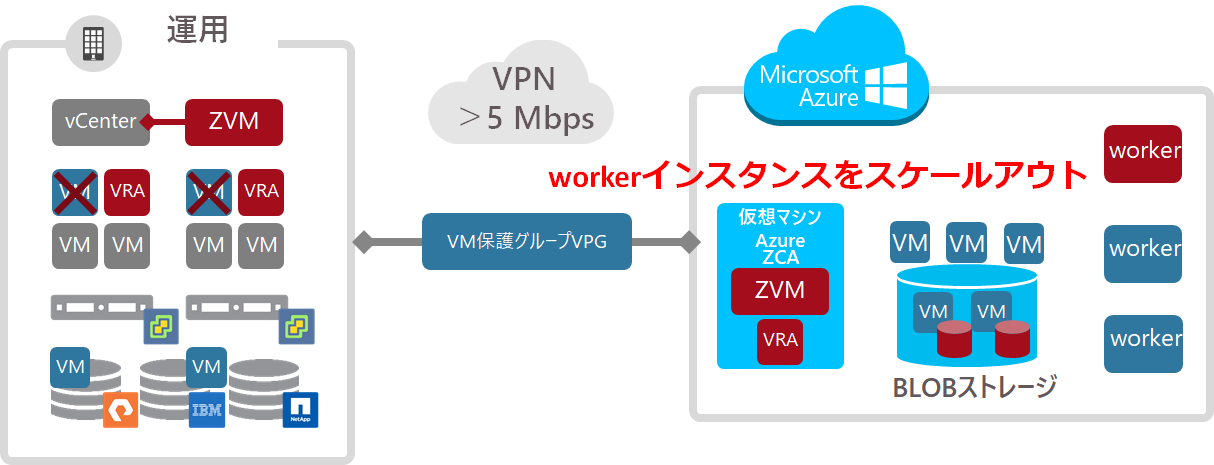
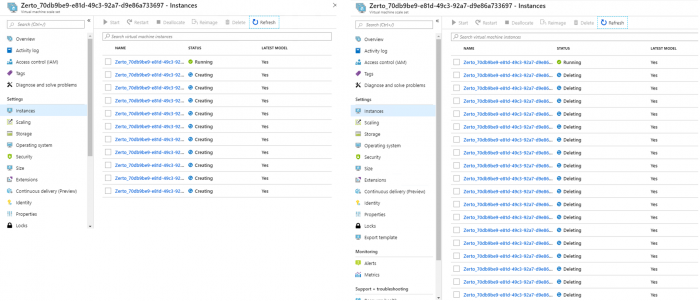
これにより、大規模環境における大量VMの同時フェイルオーバー速度が向上しRTOを短縮できるようになりました。









 RSSフィードを取得する
RSSフィードを取得する
