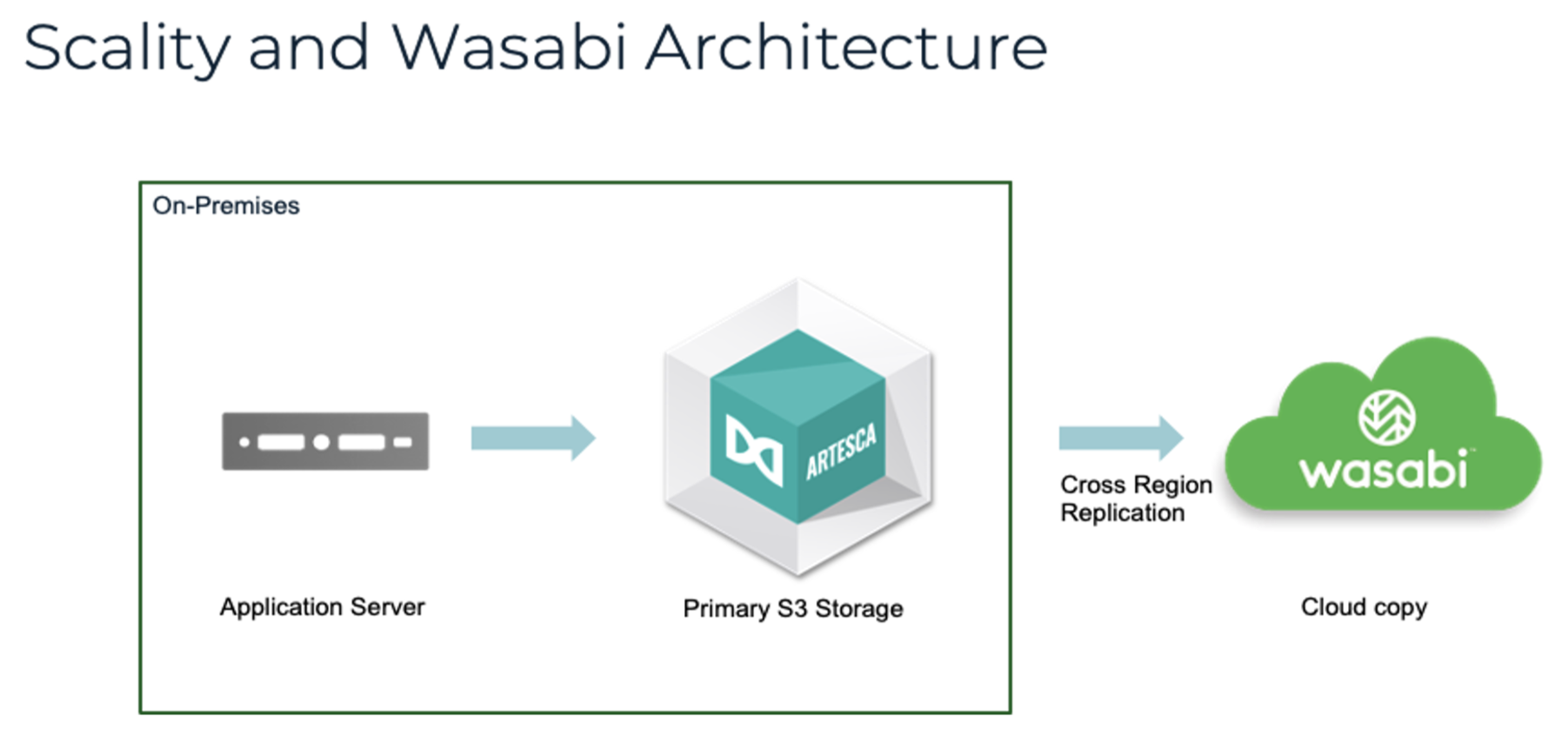
Climb Cloud Backup & SecurityはGoogle Workspaceの標準機能(Google Vaultなど)では補いきれない「意図しない削除」「ランサムウェア被害」「迅速な時点復元」に特化した、強力なクラウド・ツー・クラウド(C2C)バックアップソリューションを提供しています。
1. 主なバックアップ対象
Google Workspace内の主要なデータを網羅的に保護します。
-
Gmail: メール本文、添付ファイル、ラベル、スレッド全体。
-
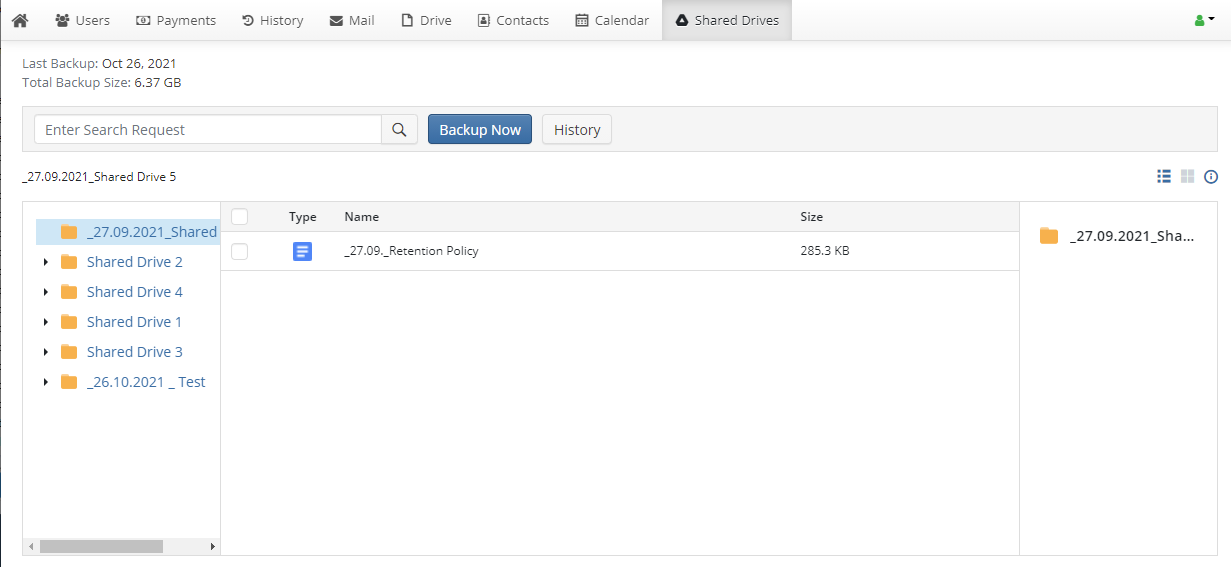
Google ドライブ: マイドライブ内のファイル・フォルダに加え、共有ドライブ(旧チームドライブ)も対象。
-
連絡先とカレンダー: 連絡先グループや予定、添付ファイルなど。
2. 注目すべき5つの保護機能
① エージェントレスの直接バックアップ
GoogleのデータセンターからAcronisのクラウドストレージへ直接データを転送します。自社サーバーの設置や、各PCへのソフトインストールは不要で、デバイスの動作が重くなることもありません。
② 高度な検索と粒度の細かい復元
-
全文検索: バックアップ内のメールやファイルをキーワードで検索し、必要なものだけを数秒で特定できます。
-
アイテム単位の復元: フォルダ丸ごとではなく、特定のメール1通、ファイル1件単位での復元が可能です。
③ ランサムウェア・セキュリティ対策
-
改ざん防止(不変ストレージ): バックアップデータそのものが攻撃者によって暗号化されたり削除されたりするのを防ぎます。
-
ブロックチェーン認証: Acronis Notary技術により、バックアップデータがバックアップ時から改ざんされていないことを証明できます。
④ 自動化と効率化
-
新規ユーザーの自動保護: 新しく追加されたユーザーや共有ドライブを自動で検出し、バックアップ設定を適用します。
-
重複排除: 同じデータが複数の場所に存在しても、保存容量を最小限に抑える仕組みがあり、コスト効率を高めます。
⑤ コンプライアンスとガバナンス
Google標準の「保持ポリシー」では対応が難しい「特定時点へのロールバック(Point-in-time recovery)」が可能です。これにより、誤操作や悪意のある削除から確実にデータを守ります。
3. Google Workspace標準機能(Google Vault等)との違い
| 機能 | Google Workspace (標準/Vault) | Climb Cloud Backup & Security |
| 主な目的 | 電子情報開示・コンプライアンス保持 | 災害復旧・事業継続 (BCP) |
| 復元操作 | 複雑(エクスポート後の再インポート等) | 簡単(数クリックで元の場所に復元) |
| 時点復元 | 困難(削除されたものは保持されるが復旧が大変) | 容易(特定の日時の状態に即座に戻せる) |
| 一元管理 | Google管理画面のみ | サーバーや他クラウドと統合管理可能 |