- ホームページで、右上の「アラート」をクリック
- アラートの管理」をクリック

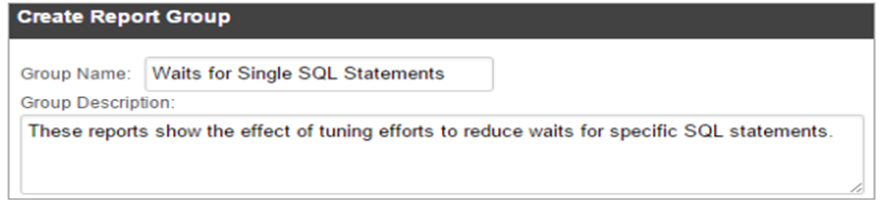
- アラートカテゴリとして「カスタム」を選択し、アラートタイプを選択してから、「アラートを作成」をクリックします。
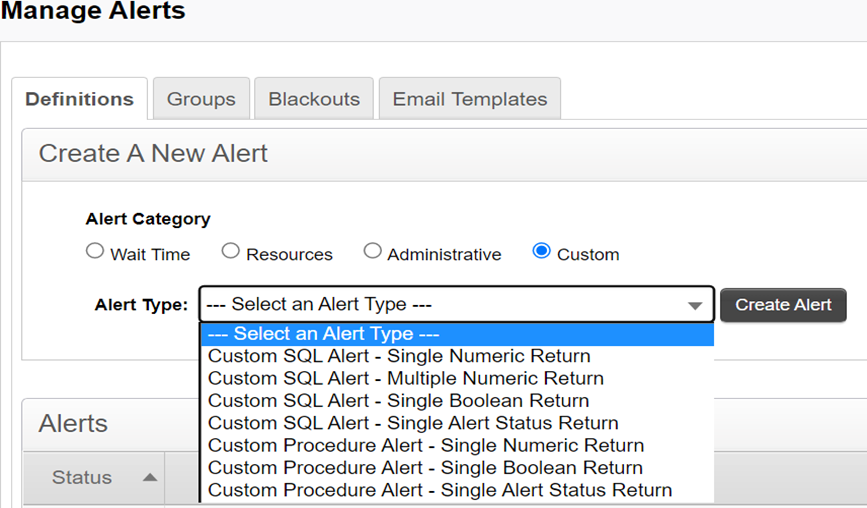
– 一意の名前を入力します
– アラートを無効にするには、[有効] チェックボックスをオフにします
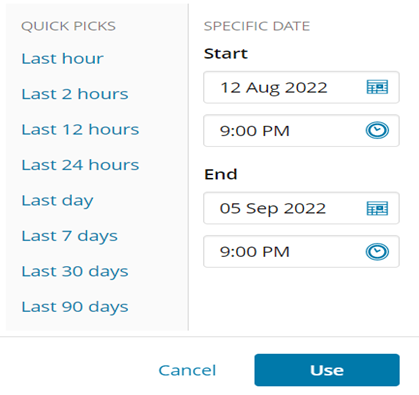
– 実行間隔を選択します。(DPAでは、実行間隔を少なくとも10分以上にすることを推奨します。)
– メール通知と共に送信する通知テキストを入力します。問題の説明と推奨される解決策を含めてください。
– アラートが適用されるデータベースインスタンスを指定します。これにより、SQLクエリまたはストアドプロシージャが(DPAリポジトリではなく)対象インスタンス上で実行されます。1つ以上の条件を満たすインスタンスは、手動で選択するか、ルールを使用して検索できます。
- ルールを選択すると、DPAはルール条件に基づいてアラートが監視するインスタンスを決定します。環境が変更されるたびに、インスタンスのリストは自動的に更新されます。
– [ルールを使用]をクリック
– [ルール]ページには既存のルールが一覧表示されます
– 既存のルールを選択するか、新規ルールを作成して選択します。
– [ルールの割り当てをクリア]
– アラート定義には、選択したルール名、ルール式、および現在ルール条件を満たしているインスタンスの一覧が表示されます。
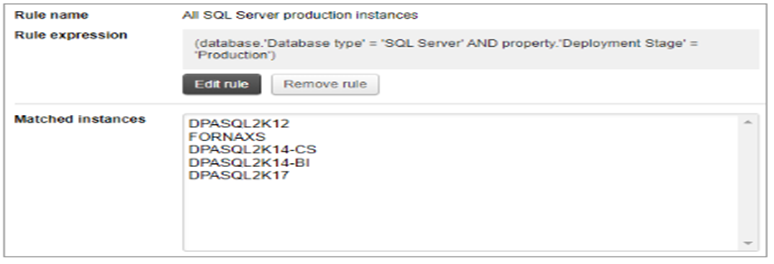
- データベースインスタンスを手動で選択する場合、リストは静的です
– [データベースインスタンスの選択] をクリックします。
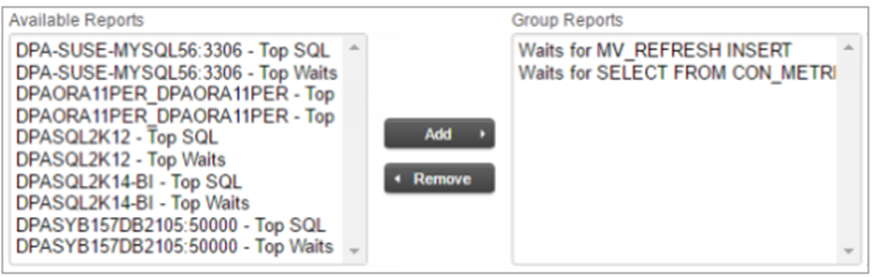
– 利用可能なデータベースインスタンスページにはデータベースインスタンスが一覧表示されます。アラートタイプが特定のデータベースタイプに限定されている場合、該当タイプのインスタンスのみが表示されます。
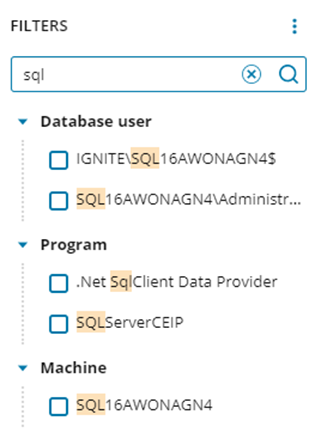
– 検索バーを使用してインスタンスを検索するか、フィルターを適用してリストを絞り込みます
– リスト内の全インスタンスを選択するには、リスト上部のチェックボックスを選択します。個々のインスタンスを選択するには、各インスタンスの横にあるチェックボックスを選択します。
– [割り当て]をクリックして戻る
– アラート定義画面に選択したインスタンスの一覧が表示されます。
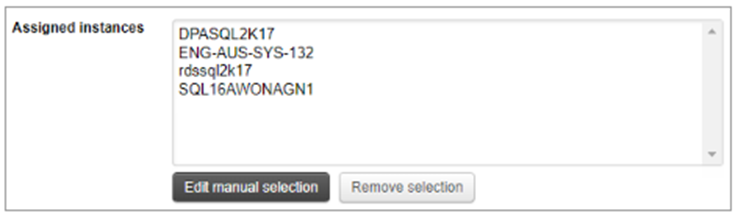
– 実行するSQL文を入力するか、ストアドプロシージャの呼び出しを入力します。カスタムタグを使用して、データベースIDなどの変数や、ストアドプロシージャに必要な出力パラメータを含めることができます。
– [実行対象]ドロップダウンで、SQL文またはストアドプロシージャを、選択したデータベースインスタンスに対して実行するか、DPAリポジトリデータベースに対して実行するかを指定します。
– [説明]フィールドが利用可能な場合、アラート用のカスタム説明を入力できます。この説明は、メールテンプレートに[説明]パラメータが含まれている場合、アラートタイプのDPAデフォルト説明に置き換わります。
– アラートが数値を返す場合、返される値の単位を指定します。
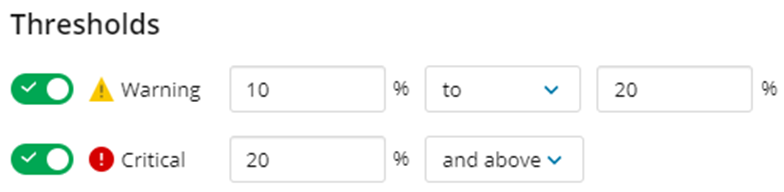
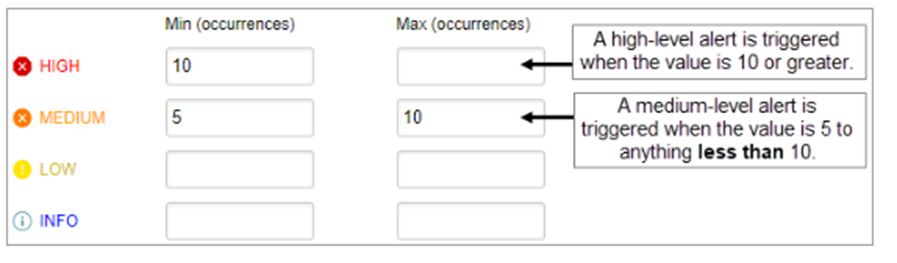
- アラートが数値を返す場合、有効にする各アラートレベルのしきい値を指定します。
– 最高レベルの最大値は空白のままにすると、そのレベルの最小値を超えるすべての値に対してアラートが通知されます。
– 複数のレベルを設定する場合、下位レベルの最大値は必ず等しい上位レベルの最小値に設定してください。
– レベルの最大値を入力すると、値が最小値を上回るか等しいが、最大値を下回る場合に、DPAはそのレベルでアラートを通知します。例えば、最小値が5で最大値が10の場合、値が5以上10未満のときにDPAはそのレベルでアラートを通知します。
- 各アラートレベルがトリガーされたとき、およびアラートが解除されたときに通知を受け取る個人またはグループを選択します(アラートステータスは、実行中にエラーが発生した場合に「解除」に設定されます)。アラートが「正常」に戻ったときに通知を送信するには、「正常」の受信者を選択します。アラートが「正常」に戻ったときに通知を送信するには、通知ポリシーが「レベル変更時に通知」である必要があります。
- このアラートによって送信されるメール通知の内容を定義するメールテンプレートを選択します。
- [メールプレビュー]をクリックすると、選択したメールテンプレートと連絡先情報を使用して生成されるメールの例を確認できます。
– アラートが複数のデータベースインスタンスに適用される場合、[メールプレビュー]ダイアログボックスでインスタンスを選択し、[OK]をクリックします。メールを確認後、別のデータベースインスタンスを選択するか、[キャンセル]をクリックして[メールプレビュー]ダイアログボックスを閉じることができます。プレビュー中に評価できないアラートパラメータがあるため、ユーザーに送信されるメールはプレビューと完全に一致しない場合があります。
- アラートをテストし、現在のアラートレベルを確認するには、[アラートテスト] をクリックします。テストではメールは生成されません。
- [保存] をクリックします。
追加リソース: カスタムアラートのドキュメント