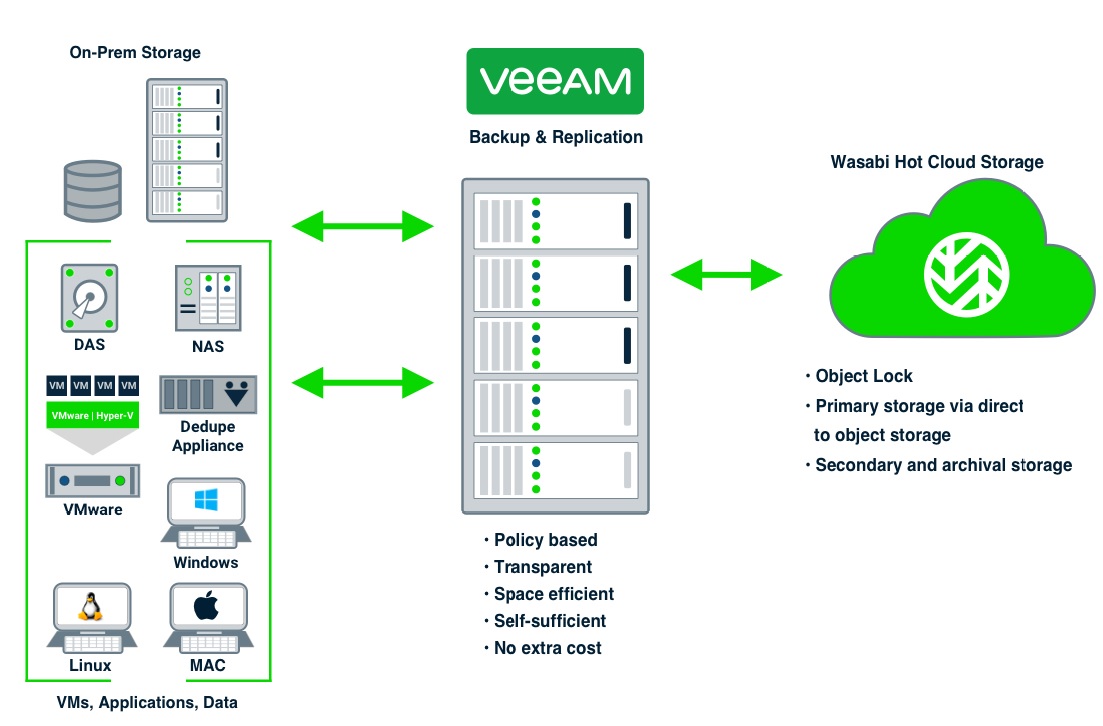
Dell EMC Data Domainを使用する利点
●重複排除により、長期保存に必要なディスク量が削減されるため、バックアップアプリケーションのディスクへの重複排除(つまり低コストのプライマリストレージディスク)と比較してコスト削減が可能
●重複排除により、オフサイトにレプリケートされるデータ量が削減され、WAN 帯域幅が節約される
Dell EMC Data Domainの短所
●インライン重複排除はバックアップを遅くする
●各リクエストごとにデータを再保存するため、リストアが大幅に遅くなる
●VMの起動には最大1時間、ファイルのリストアには最大20倍かかる
●パフォーマンスのスケーラビリティがないため(つまり、ディスクシェルフを追加するだけ)、データの増加に伴ってバックアップウィンドウが大きくなる
●フォークリフト・アップグレード(オーバーホール)を余儀なくされる – コントローラが限界に達した場合、システムを前進させ成長させるために多大なコストがかかる
●強制的な生産終了(EOL)ポリシーによる強制的な陳腐化、サポートの中止、またはサポート料金の大幅な増加
●ランサムウェアのリカバリに対応するために、デルから別途高価なソリューションを購入する必要がある。
●ランサムウェア・ソリューションはネットワーク上にあり(ネットワークに面している)、レプリケーション時にポートが開放されるため、ランサムウェア攻撃を受けやすい
●100TBを超えるとExaGridより高価 – Data Domainが適切なサイズであれば、2-3倍の価格に
● DELLは次回購入時に値上げすることが多い
Dell EMC Data Domainに対するExaGridの利点
●ExaGrid はディスクキャッシュの Landing Zone に直接書き込み(インライン重複排除なし)、Data Domain のインライン重複排除よりも 3 倍高速なディスク速度で書き込みを行う。
●ランディングゾーンのデータが重複排除されないため、リストアが20倍高速化。
●アプライアンスを追加することですべてのリソースをデータの増加に対応させるスケールアウトアーキテクチャにより、データが増加してもバックアップウィンドウの長さは一定に保たれる。
●ExaGridアーキテクチャ異なるサイズや世代のアプライアンスを混在が可能
●スケールアウトアーキテクチャにより、フォークリフト・アップグレードや製品の陳腐化がない
●リテンション・タイムロックによるシンプルなランサムウェアリカバリ、遅延削除とイミュータブルなデータオブジェクトによる非ネットワーク向けティア(ティアード・エアギャップ)を組込済
●ExaGridは100TB以上ならDataDomainよりさらに割安